
Lending Club : Predict Bad Loans to Minimize Loss to Defaulted Accounts

As a sales engineer on the H2O.ai team I get asked a lot about the value add of H2O. How do you put a price tag on something that is open source? This typically revolves around the use cases; if a use case pertains to improving user experience or making apps that can improve internal operations then there’s no straightforward way of monetarily accumulating better experiences. However, if the use case is focused on detecting fraud or maintaining enough supply for the next sales quarter, we can calculate the total amount of money saved by detecting pricey fraudulent cases or sales lost due to incorrectly forecasted demand.
The H2O team has built a number of user-facing demostrations from our Ask Craig App to predicting flight delays which are available in R , Sparkling Water ,and Python . Today, we will use Lending Club’s Open Data to obtain the probability of a loan request defaulting or being charged off. We will build an H2O model and calculate the dollar amount of money saved by rejecting these loan requests with the model (not including the opportunity cost), and then combine this with the profits lost in rejecting good loans to determine the net amount saved.
Summary of Approved Loan Applicants
The dataset had a total of half a million records from 2007 up to 2015 which means with H2O, the data can actually just be processed on your personal computer with an H2O instance with at least 2GB of memory. The first step is to import the data and create a new column that categorizes the loan as either a good loan or a bad loan (the user has defaulted or the account has been charged off). The following is a code snippet for R:
print("Start up H2O...")
library(h2o)
conn <- h2o.init(nthreads = -1)
print("Import approved and rejected loan requests from Lending Tree...")
path <- "/Users/amy/Desktop/lending_club/loanStats/"
loanStats <- h2o.importFile(path = path, destination_frame = "LoanStats")
print("Create bad loan label, this will include charged off, defaulted, and late repayments on loans...")
loanStats$bad_loan <- ifelse(loanStats$loan_status == "Charged Off" |
loanStats$loan_status == "Default" |
loanStats$loan_status == "Does not meet the credit policy. Status:Charged Off",
1, 0)
loanStats$bad_loan <- as.factor(loanStats$bad_loan)
print("Create the applicant's risk score, if the credit score is 0 make it an NA...")
loanStats$risk_score <- ifelse(loanStats$last_fico_range_low == 0, NA,
(loanStats$last_fico_range_high + loanStats$last_fico_range_low)/2)
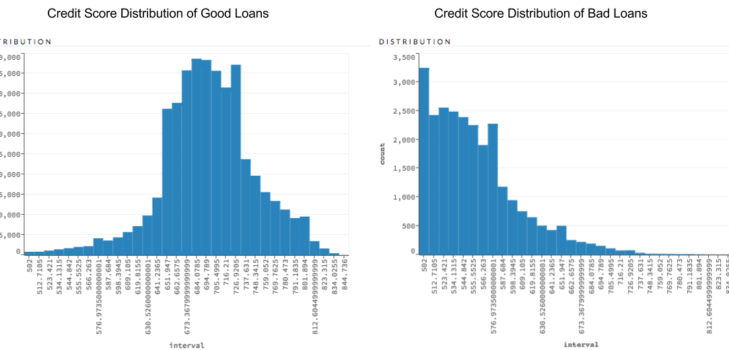
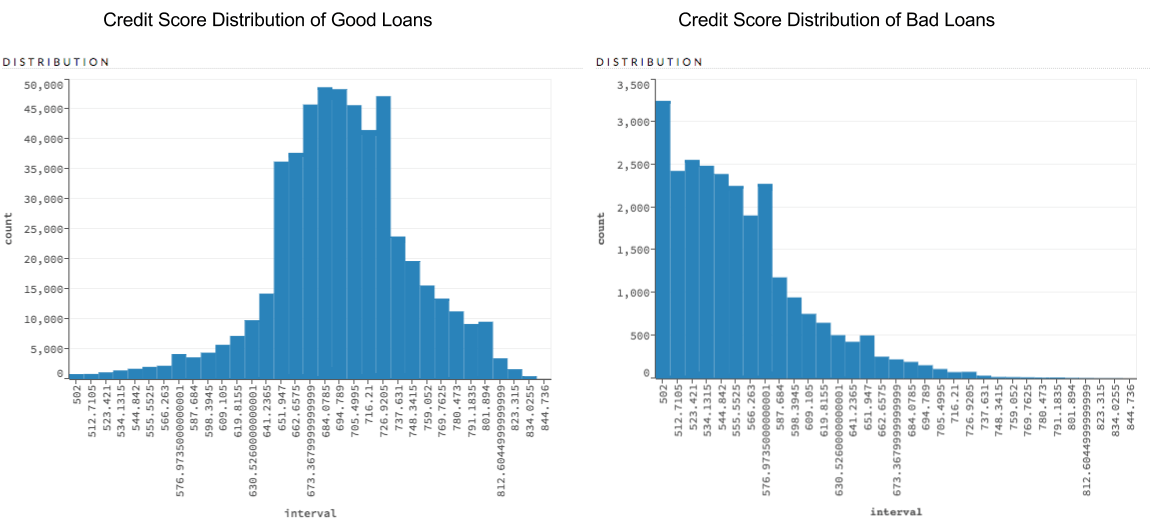
Credit Score Summaries
In H2O Flow, you can grab the distribution of credit scores for good loans vs bad loans. It is easy to see that owners of bad loans typically have the lowest credit score, which will be the biggest driving force in predicting whether a loan is good or not. However we want a model that actually takes into account other features so that loans aren’t automatically cut off at a certain threshold.
Modeling
Pending review : Will update blog soon