
Random Forest Measurements for the MNIST Dataset

This post discusses the performance of H2O’s Random Forest [5] algorithm. We compare different versions of H2O as well as the RF implementation by wise.io . We use wall-clock time to measure work flows that match up with the user experience. A link to the scripts used is available here [1] .
Specifications
Hardware
- Amazon EC2 in US-EAST-1
- M2 High-Memory Quadruple Extra Large EC2 (m2.4xlarge)
- 26 ECUs, 8 vCPUs, 68.4 GB RAM
- We used a 100 GB EBS mount to host the code and data.
- No additional swap volume was needed.
Software
- Software environment:
- Ubuntu Server 12.04 LTS (64 bit)
- Oracle Java 1.7.0_25
- Bash 4
- d3.js
- Software under test:
- H2O-Fourier-1 (60GB Heap)
- H2O-Fourier-6 (60GB Heap)
- WiseRF 1.5.9
Test Notes
- 0xdata recommends using the Oracle JDK/JRE.
- No swapping occurred.
- EC2 has variable performance and results are aggregate scores over many runs.
- We used H2O’s REST API. This API is intended for customer use.
- Caches were dropped before each run (“sudo bash -c “sync; echo 3 > /proc/sys/vm/drop_caches”)
Data
The original MNIST data (60,000 28×28 images of hand-written digits) was expanded into 8.1 million instances by thickening, dilating, skewing, and contracting the original images as described here [2] .
This expanded MNIST dataset is available here [3] . There are 784 features with values in the range 0 – 255. This data was split into testing and training sets following the methodology described here [4] .
Dataset Name: mnist8m
Number of Features: 784</code></li>
Number of Training Observations: 7,000,000
Number of Testing Observations: 1,100,000
Number of Classes: 10
Parameters & Methodology
The following parameters were used for comparing the H2O RF and WiseRF algorithms. These parameters were chosen using the methodology described here [4] .
This methodology was previously shown to produce very low error rates when predicting on the test data (less than one-tenth of one percent in all cases).
Tests were performed on an Amazon EC2 instance. Since individual runs in EC2 can experience variability, each configuration was run 10 times. The graphs in the “Speed” section below show box plots for each configuration (each box represents 10 runs).
Config:
H2O
mtry: 37sample: 100ntree: 10criteria: entropy
Defaults:
seed: 784834182943470027depth: 2147483647 (no limit)bin limit: 1024parallel: 1
WiseRF
mtry: 33lambda: 1ntree: 10criteria: infogainbootstrap: false
Defaults:
seed: 1max depth: 0 (no limit)min node size: 1threads: 10feature type: uchar, float, double
Speed
The following graphs show the measurements for H2O’s RF and WiseRF. All measurements are wall clock times. The graphs are broken down into overall run time, the time to parse the training file, the time to train the model, and the time to parse and score a test file. Note: Graphs are annotated with median times.
The graphs show that H2O’s RF performance improved significantly from Fourier-1 to Fourier-6. The reader can see that overall the Wise RF algorithm performs roughly equivalently to H2O when the dataset values do not fit perfectly within a single byte. Also note that, once a model is built, both H2O and WiseRF-uchar parse and score the test data in nearly the same amount of time.
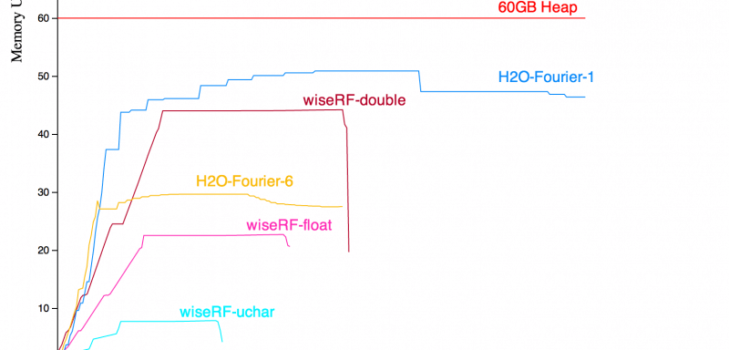
Memory Usage
The graph shows memory utilization (RSS) for each algorithm over time. These values were collected over one additional independent run for each algorithm. Note that none of the algorithms required swap to run.
Conclusions
H2O’s Random Forest is open source and continuously improving . 0xdata invites everyone to download the source code and contribute improvements to the algorithm and harness.
Reproducing These Results
Scripts and Steps to reproduce the data are available here . Directions in the README.
Data used to generate charts above available here and also below in the tables (memory tables excluded).
References
[1] Data and Scripts
[2] Bottou et al. MNIST8M Origination (pdf)
[3] MNIST8M in libsvm format
[4] wise.io blog
[5] Random Forest is a trademark of Salford Systems, Inc.
Tables
WiseRF-double Speed Summary
| trainfile_parse.minutes | 8.55 | 0.7 |
|---|---|---|
| train_time.minutes. | 14.71 | 0.06 |
| test_time.seconds. | 94.5 | 3.1 |
| overall_time.minutes. | 25.37 | 0.7 |
WiseRF-float Speed Summary
| trainfile_parse.minutes. | 8.4 | 1.41 | |
|---|---|---|---|
| train_time.minutes. | 11.73 | 0.51 | |
| test_time.seconds. | 91.0 | 12.71 | |
| overall_time.minutes. | 22.03 | 1.6 |
WiseRF-uchar Speed Summary
| trainfile_parse.minutes. | 5.85 | 1.75 | |
|---|---|---|---|
| train_time.minutes. | 8.22 | 0.12 | |
| test_time.seconds. | 48.5 | 5.84 | |
| overall_time.minutes. | 15.1 | 1.73 |
H2O-Fourier-1-aec3679e7c.csv Speed Summary
| trainfile_parse.minutes. | 4.15 | 0.31 | |
|---|---|---|---|
| train_time.minutes. | 37.45 | 0.36 | |
| test_time.seconds. | 44.2 | 7.64 | |
| overall_time.minutes. | 42.47 | 0.52 |
H2O-Fourier-6-137 Speed Summary
| trainfile_parse.minutes. | 3.92 | 0.21 | |
|---|---|---|---|
| train_time.minutes. | 18.53 | 0.2 | |
| test_time.seconds. | 42.7 | 3.33 | |
| overall_time.minutes. | 23.29 | 0.37 |
Speed Table (All Data Points)
| fourier-1-h2o-aec3679e7c | 4.92 | 37.6 | 46.0 | 43.38 | |
|---|---|---|---|---|---|
| fourier-1-h2o-aec3679e7c | 4.15 | 37.43 | 41.0 | 42.45 | |
| fourier-1-h2o-aec3679e7c | 3.9 | 37.23 | 52.0 | 42.12 | |
| fourier-1-h2o-aec3679e7c | 4.08 | 36.77 | 41.0 | 41.67 | |
| fourier-1-h2o-aec3679e7c | 4.13 | 37.25 | 25.0 | 41.93 | |
| fourier-1-h2o-aec3679e7c | 3.97 | 37.77 | 49.0 | 42.7 | |
| fourier-1-h2o-aec3679e7c | 3.85 | 37.57 | 44.0 | 42.27 | |
| fourier-1-h2o-aec3679e7c | 4.07 | 38.1 | 47.0 | 43.08 | |
| fourier-1-h2o-aec3679e7c | 4.0 | 37.55 | 47.0 | 42.48 | |
| fourier-1-h2o-aec3679e7c | 4.43 | 37.25 | 50.0 | 42.65 | |
| fourier-6-h2o-137 | 3.78 | 18.68 | 49.0 | 23.42 | |
| fourier-6-h2o-137 | 4.27 | 18.98 | 44.0 | 24.13 | |
| fourier-6-h2o-137 | 3.88 | 18.35 | 44.0 | 23.1 | |
| fourier-6-h2o-137 | 3.57 | 18.67 | 39.0 | 23.03 | |
| fourier-6-h2o-137 | 4.0 | 18.37 | 44.0 | 23.23 | |
| fourier-6-h2o-137 | 3.97 | 18.52 | 45.0 | 23.37 | |
| fourier-6-h2o-137 | 3.9 | 18.35 | 40.0 | 23.03 | |
| fourier-6-h2o-137 | 4.15 | 18.5 | 39.0 | 23.42 | |
| fourier-6-h2o-137 | 3.65 | 18.35 | 39.0 | 22.77 | |
| fourier-6-h2o-137 | 4.0 | 18.53 | 44.0 | 23.38 | |
| WiseRF-double | 8.39 | 14.7 | 95.0 | 25.2 | |
| WiseRF-double | 8.35 | 14.66 | 96.0 | 25.15 | |
| WiseRF-double | 8.51 | 14.61 | 97.0 | 25.3 | |
| WiseRF-double | 8.42 | 14.67 | 96.0 | 25.23 | |
| WiseRF-double | 10.52 | 14.82 | 86.0 | 27.35 | |
| WiseRF-double | 8.24 | 14.73 | 94.0 | 25.05 | |
| WiseRF-double | 8.2 | 14.67 | 96.0 | 25.02 | |
| WiseRF-double | 8.22 | 14.78 | 95.0 | 25.13 | |
| WiseRF-double | 8.3 | 14.71 | 95.0 | 25.13 | |
| WiseRF-double | 8.31 | 14.72 | 95.0 | 25.15 | |
| WiseRF-float | 7.02 | 11.47 | 80.0 | 20.2 | |
| WiseRF-float | 7.0 | 11.52 | 81.0 | 20.23 | |
| WiseRF-float | 9.52 | 11.53 | 103.0 | 23.13 | |
| WiseRF-float | 9.14 | 11.53 | 80.0 | 22.37 | |
| WiseRF-float | 7.12 | 11.44 | 112.0 | 20.8 | |
| WiseRF-float | 10.4 | 11.57 | 106.0 | 24.1 | |
| WiseRF-float | 10.51 | 11.53 | 83.0 | 23.8 | |
| WiseRF-float | 7.41 | 11.49 | 80.0 | 20.6 | |
| WiseRF-float | 7.28 | 12.09 | 85.0 | 21.15 | |
| WiseRF-float | 8.63 | 13.09 | 100.0 | 23.88 | |
| WiseRF-uchar | 5.13 | 8.18 | 48.0 | 14.32 | |
| WiseRF-uchar | 5.15 | 8.16 | 47.0 | 14.32 | |
| WiseRF-uchar | 5.25 | 8.37 | 46.0 | 14.62 | |
| WiseRF-uchar | 5.14 | 8.52 | 46.0 | 14.67 | |
| WiseRF-uchar | 5.03 | 8.15 | 46.0 | 14.17 | |
| WiseRF-uchar | 5.05 | 8.12 | 46.0 | 14.17 | |
| WiseRF-uchar | 10.62 | 8.17 | 47.0 | 19.8 | |
| WiseRF-uchar | 5.16 | 8.17 | 47.0 | 14.37 | |
| WiseRF-uchar | 6.75 | 8.21 | 47.0 | 15.97 | |
| WiseRF-uchar | 5.17 | 8.19 | 65.0 | 14.65 |