
In-memory Big Data: Spark + H2O

Category: Uncategorized
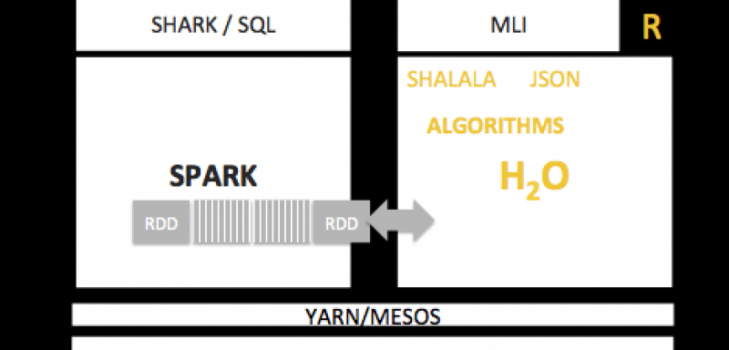
Big Data has moved in-memory. Customers using SQL in their Join & Munging efforts via SHARK and Apache Spark need to use Regressions and Deep Learning. To make their experiences great & seamlessly weave SQL workflows with Data Science and Machine Learning, we are architecting a simple RDD data import-export in H2O. This brings continuity to their in-memory interactive experience. And support for Spark MLI using our native Scala API – Shalala.
Big Data users can now use SHARK to extract and fuse datasets and H2O for better predictions.
hdfs | Spark | SHARK/SQL | RDD | h2o.readRDD() | h2o.deepLearning() | h2o.predict() | h2o.persist(RDD or HDFS)
Calling h2o.deepLearning() from within Scala interface alongside Spark (via Shalala) will make the workflow even more seamless for end users.