






H2O AI Super Agent™
for Sovereign AI

BEYOND SURFACE-LEVEL INSIGHTS
We Built the World’s
Leading Deep Research Solution,
On-Premise & Air-Gapped



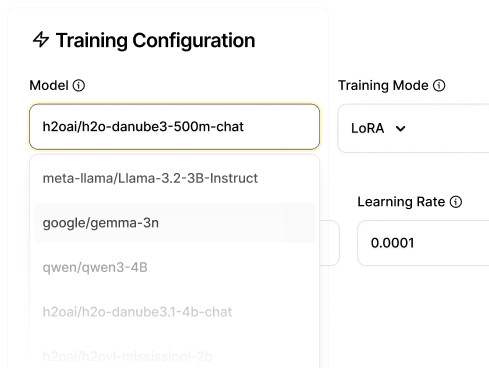

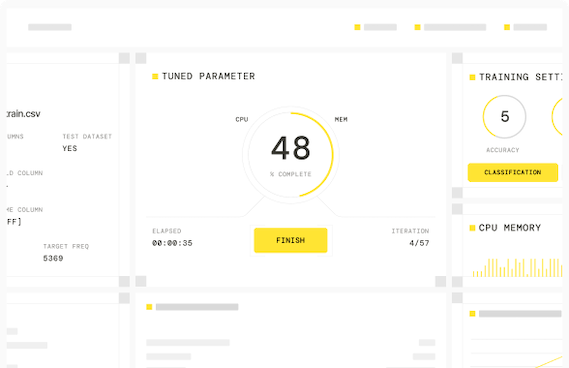

H2O Driverless AI
Accelerate model development with automatic feature engineering and explainability.


SOCIAL PROOF
Transform Your Data into Secure,
Autonomous Agents—Today
Trusted by the World’s Most Regulated Industries





H2O.ai helps you transition from pilots to production using your models and private data—deployed securely on your infrastructure.











SMART WORKFLOWS SECURED
Autonomous agentic workflows with human-in-the-loop oversight, reasoning, and safeguards — at the highest possible accuracy.
From fraud detection to HR support agents, H2O Vertical Agents scale the delivery of critical jobs to be done, without compromising trust.
Works with Your Apps
Together, they enable agents that go beyond language—able to forecast, reason, optimize, and take action. This convergence powers decision-making and automation across enterprise workflows.
- KYC and customer onboarding
- Loan automation and fraud investigations
- Trade reconciliation and regulatory reporting
- Wealth portfolio rebalancing and debt collection
- Call center resolution and customer support
- Document routing and policy filing

- Call center classification
- Text to SQL
- Customer service agents
- Billing issue resolution agents
- NOC alert triage agents
- Field dispatch optimization agents

- Audio Surveillance & Translation
- Satellite Imagery & Object Detection
- Immigration Policy Simulation
- Anomaly Detection for IT Ops
- LLM-Powered Document & Archive Summarization
- Agency Assistants and Chatbots

The Highest Caliber Institutions Trust H2O.ai’s Technology Vision
H2O is modular, composable, and enterprise-ready—built for speed, accuracy, and high-precision.
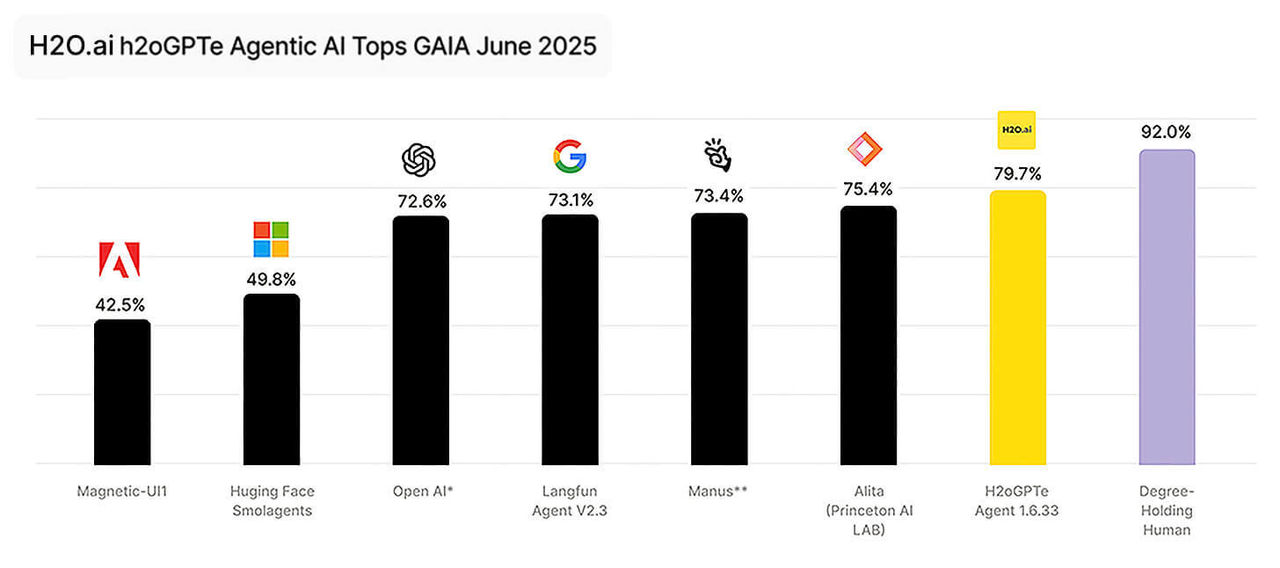
Our h2oGPTe Agent consistently tops the leaderboard for deep research accuracy
We were the first to achieve 75% accuracy on the General AI Assistant (GAIA) test, placing us ahead of OpenAI’s deep research.
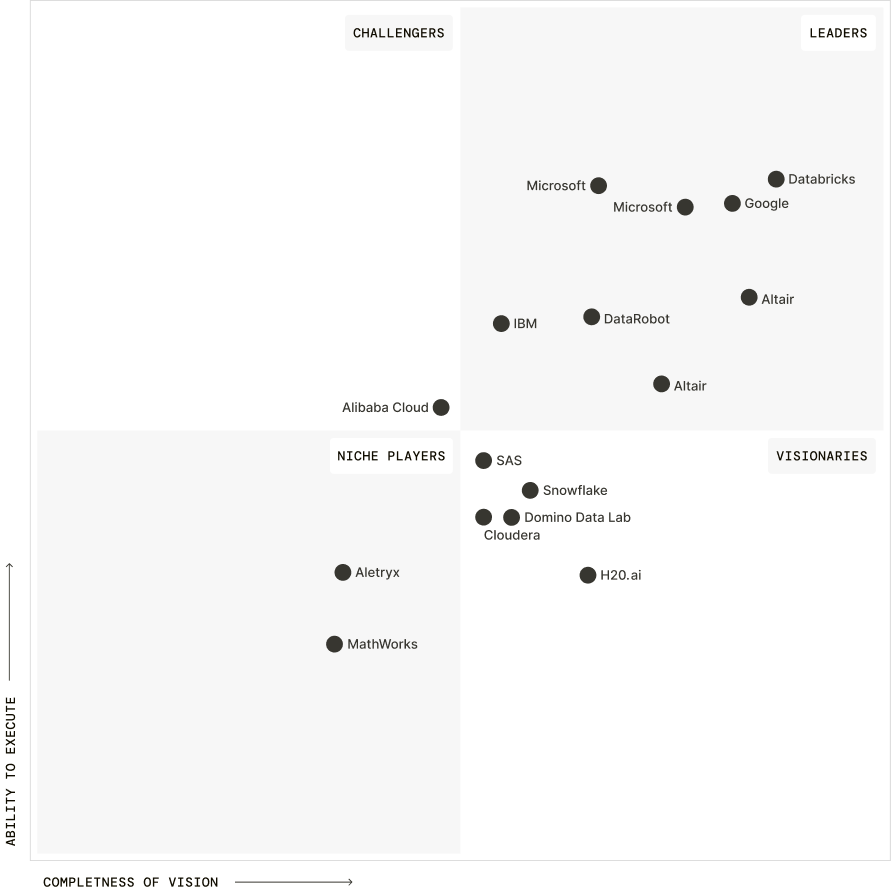
Gartner MQ DSML
H2O.ai is recognized based on its completeness of vision and ability to execute.

AI AGENT
Create powerful AI agents to
automate work at scale
-
Vertical Agents

Create powerful domain-specific agents to automate work at scale on your private data.
-
Digital Assistants

Find answers. Generate responsive, situation-specific content you can trust.
-
Safety

H2O MRM and Eval Studio provide automated testing, human-calibrated evaluations, and real-time risk monitoring to ensure transparency—strengthening compliance, risk management, and user confidence.
-
Easily Integrate Into Your Stack

H2O’s APIs make it easy to integrate agentic AI search and task agents into existing workflows via Google Drive, SharePoint, Slack, Teams, and more.



