






Research Papers


TabH2O: A Unified Foundation Model for Tabular Prediction
This paper presents TabH2O, a foundation model for tabular data that performs classification and regression in a single forward pass via in-context learning. TabH2O builds on the TabICL architecture with several key modifications: (1) unified training, a single model handles both classification and regression via a dual-head architecture, eliminating the need for separate models and reducing total pretraining cost; (2) single-stage pretraining, training stability improvements (bounded scalable softmax, inter-stage normalization, learnable residual scaling, logit soft-capping) eliminate the need for multi-stage curriculum learning, enabling training with full-length sequences from the start; and (3) noise-aware pretraining, synthetic datasets include explicit noise dimensions to teach the model robustness to irrelevant features. We evaluate TabH2O v1 (29.2M parameters) on the TALENT benchmark (300 datasets), where it achieves an average rank of 2.55 out of 6 evaluated methods, outperforming tuned CatBoost (4.07), H2O AutoML (4.18), and LightGBM (5.08), competitive with TabPFN v2.6 (2.74), and behind TabICL v2 (2.12), while placing in the top-3 on 81% of the testing datasets across classification and regression tasks.
Read more
H2OVL-Mississippi Vision Language Models Technical Report
Smaller vision-language models (VLMs) are becoming increasingly important for privacy-focused, on-device applications due to their ability to run efficiently on consumer hardware for processing enterprise commercial documents and images. These models require strong language understanding and visual capabilities to enhance human-machine interaction. To address this need, we present H2OVL-Mississippi, a pair of small VLMs trained on 37 million image-text pairs using 240 hours of compute on 8 x H100 GPUs. H2OVL-Mississippi-0.8B is a tiny model with 0.8 billion parameters that specializes in text recognition, achieving state of the art performance on the Text Recognition portion of OCRBench and surpassing much larger models in this area. Additionally, we are releasing H2OVL-Mississippi-2B, a 2 billion parameter model for general use cases, exhibiting highly competitive metrics across various academic benchmarks. Both models build upon our prior work with H2O-Danube language models, extending their capabilities into the visual domain. We release them under the Apache 2.0 license, making VLMs accessible to everyone, democratizing document AI and visual LLMs.
Read more
Model Validation Practice in Banking: A Structured Approach
This paper presents a comprehensive overview of model validation practices and advancement in the banking industry based on the experience of managing Model Risk Management (MRM) since the inception of regulatory guidance SR11-7/OCC11-12 over a decade ago. Model validation in banking is a crucial process designed to ensure that predictive models, which are often used for credit risk, fraud detection, and capital planning, operate reliably and meet regulatory standards. This practice ensures that models are conceptually sound, produce valid outcomes, and are consistently monitored over time. Model validation in banking is a multi-faceted process with three key components: conceptual soundness evaluation, outcome analysis, and on-going monitoring to ensure that the models are not only designed correctly but also perform reliably and consistently in real-world environments. Effective validation helps banks mitigate risks, meet regulatory requirements, and maintain trust in the models that underpin critical business decisions.
Read more
Automatic Generation of Behavioral Test Cases For Natural Language Processing Using Clustering and Prompting
Recent work in behavioral testing for natural language processing (NLP) models, such as Checklist, is inspired by related paradigms in software engineering testing. They allow evaluation of general linguistic capabilities and domain understanding, hence can help evaluate conceptual soundness and identify model weaknesses. However, a major challenge is the creation of test cases. The current packages rely on semi-automated approach using manual development which requires domain expertise and can be time consuming. This paper introduces an automated approach to develop test cases by exploiting the power of large language models and statistical techniques. It clusters the text representations to carefully construct meaningful groups and then apply prompting techniques to automatically generate Minimal Functionality Tests (MFT). The well-known Amazon Reviews corpus is used to demonstrate our approach. We analyze the behavioral test profiles across four different classification algorithms and discuss the limitations and strengths of those models.
Read more
H2O-Danube3 Technical Report
We present H2O-Danube3, a series of small language models consisting of H2O-Danube3-4B, trained on 6T tokens and H2O-Danube3-500M, trained on 4T tokens. Our models are pre-trained on high quality Web data consisting of primarily English tokens in three stages with different data mixes before final supervised tuning for chat version. The models exhibit highly competitive metrics across a multitude of academic, chat, and fine-tuning benchmarks. Thanks to its compact architecture, H2O-Danube3 can be efficiently run on a modern smartphone, enabling local inference and rapid processing capabilities even on mobile devices. We make all models openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
Read more
H2O-Danube-1.8B Technical Report
We present H2O-Danube-1.8B, a 1.8B language model trained on 1T tokens following the core principles of LLama 2 and Mistral. We leverage and refine various techniques for pre-training large language models. Although our model is trained on significantly fewer total tokens compared to reference models of similar size, it exhibits highly competitive metrics across a multitude of benchmarks. We additionally release a chat model trained with supervised fine-tuning followed by direct preference optimization. We make H2O-Danube-1.8B openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
Read more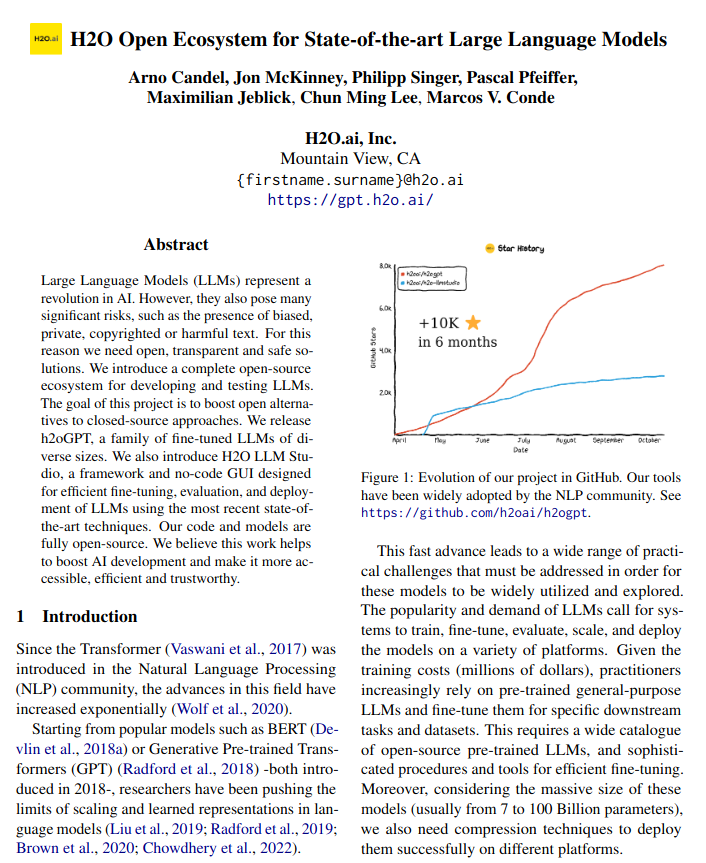
H2O Open Ecosystem for State-of-the-art Large Language Models
Large Language Models (LLMs) represent a revolution in AI. However, they also pose many significant risks, such as the presence of biased, private, copyrighted or harmful text. For this reason we need open, transparent and safe solutions. We introduce a complete open-source ecosystem for developing and testing LLMs. The goal of this project is to boost open alternatives to closed-source approaches. We release h2oGPT, a family of fine-tuned LLMs of diverse sizes. We also introduce H2O LLM Studio, a framework and no-code GUI designed for efficient fine-tuning, evaluation, and deployment of LLMs using the most recent state-of-the-art techniques. Our code and models are fully open-source. We believe this work helps to boost AI development and make it more accessible, efficient and trustworthy. The demo is available at: https://gpt.h2o.ai
Read more
Rapid Deforestation and Burned Area Detection using Deep Multimodal Learning on Satellite Imagery
Deforestation estimation and fire detection in the Amazon forest poses a significant challenge due to the vast size of the area and the limited accessibility. However, these are crucial problems that lead to severe environmental consequences, including climate change, global warming, and biodiversity loss. To effectively address this problem, multimodal satellite imagery and remote sensing offer a promising solution for estimating deforestation and detecting wildfire in the Amazonia region. This research paper introduces a new curated dataset and a deep learning-based approach to solve these problems using convolutional neural networks (CNNs) and comprehensive data processing techniques. Our dataset includes curated images and diverse channel bands from Sentinel, Landsat, VIIRS, and MODIS satellites. We design the dataset considering different spatial and temporal resolution requirements. Our method successfully achieves high-precision deforestation estimation and burned area detection on unseen images from the region.
Read more
h2oGPT: Democratizing Large Language Models
Applications built on top of Large Language Models (LLMs) such as GPT-4 represent a revolution in AI due to their human-level capabilities in natural language processing. However, they also pose many significant risks such as the presence of biased, private, or harmful text, and the unauthorized inclusion of copyrighted material. We introduce h2oGPT, a suite of open-source code repositories for the creation and use of LLMs based on Generative Pretrained Transformers (GPTs). The goal of this project is to create the world's best truly open-source alternative to closed-source approaches. In collaboration with and as part of the incredible and unstoppable open-source community, we open-source several fine-tuned h2oGPT models from 7 to 40 Billion parameters, ready for commercial use under fully permissive Apache 2.0 licenses. Included in our release is 100\% private document search using natural language. Open-source language models help boost AI development and make it more accessible and trustworthy. They lower entry hurdles, allowing people and groups to tailor these models to their needs. This openness increases innovation, transparency, and fairness. An open-source strategy is needed to share AI benefits fairly, and this http URL will continue to democratize AI and LLMs.
Read more
A Brief Overview of AI Governance for Responsible Machine Learning Systems
Organizations of all sizes, across all industries and domains are leveraging artificial intelligence (AI) technologies to solve some of their biggest challenges around operations, customer experience, and much more. However, due to the probabilistic nature of AI, the risks associated with it are far greater than traditional technologies. Research has shown that these risks can range anywhere from regulatory, compliance, reputational, and user trust, to financial and even societal risks. Depending on the nature and size of the organization, AI technologies can pose a significant risk, if not used in a responsible way. This position paper seeks to present a brief introduction to AI governance, which is a framework designed to oversee the responsible use of AI with the goal of preventing and mitigating risks. Having such a framework will not only manage risks but also gain maximum value out of AI projects and develop consistency for organization-wide adoption of AI.
Read more
General Image Descriptors for Open World Image Retrieval using ViT CLIP
The Google Universal Image Embedding (GUIE) Challenge is one of the first competitions in multi-domain image representations in the wild, covering a wide distribution of objects: landmarks, artwork, food, etc. This is a fundamental computer vision problem with notable applications in image retrieval, search engines and e-commerce. In this work, we explain our 4th place solution to the GUIE Challenge, and our "bag of tricks" to fine-tune zero-shot Vision Transformers (ViT) pre-trained using CLIP.
Read more