






Smart Document Filtering with Metadata Extraction in h2oGPTe

The Challenge: Finding the Right Documents in Large Collections
Imagine you're building a RAG (Retrieval-Augmented Generation) application that processes hundreds of invoices, contracts, or compliance documents. Your users ask questions like "What are the customer names and amounts for documents expiring on March 31, 2026?"
Traditional semantic search alone can struggle with this. While vector similarity finds documents with related content, it doesn't efficiently filter on structured attributes like dates, categories, or status codes. You need a hybrid approach: semantic search combined with structured metadata filtering.
This is where h2oGPTe's metadata extraction and filtering capabilities shine.
The Solution: Automated Metadata Extraction + Filtered Retrieval
In this article, I'll demonstrate a complete pipeline that:
- Generates sample documents using h2oGPTe's agent capabilities
- Extracts structured metadata (expiration dates) using AI-powered document processing
- Stores metadata programmatically for each document
- Queries with precision using metadata filters to retrieve exact document subsets
This workflow showcases API-exclusive features that unlock advanced document management capabilities.
Architecture Overview
We will walk through 5 steps. In your production pipelines, you will skip step 1 and 2 which are focused on using h2oGPTe to generate us fake data for the blog post!
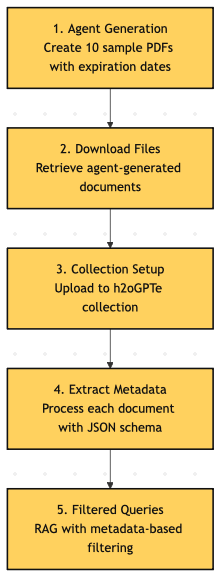
Let's walk through each step with code and results.
Step 1: Generating Sample Documents with Agents
First, we need test data. h2oGPTe's agent functionality can generate documents programmatically:
from h2ogpte import H2OGPTE
import os from dotenv import load_dotenv
load_dotenv()
h2ogpte = H2OGPTE(
address=os.environ['H2OGPTE_URL'],
api_key=os.environ['H2OGPTE_API_TOKEN']
)
# Create a chat session for the agent
chat_session_id = h2ogpte.create_chat_session()
agent_prompt = (
'Generate for me 10 fake PDFs each with 1 page of made up data; '
'somewhere on the page should be an "Expire Date" and each date should be different. '
'At least 1 of the files should use the date 03/31/2026'
)
with h2ogpte.connect(chat_session_id) as session:
reply = session.query(
agent_prompt,
llm_args=dict(use_agent=True, agent_accuracy="basic"),
timeout=600,
)
Key Feature: The use_agent=True parameter activates h2oGPTe's agentic workflow, enabling it to use tools like code execution to generate actual PDF files. This goes beyond simple text responses.
The agent successfully created 10 PDFs with varying expiration dates:
| File Name | Expire Date | Status |
|-----------------|--------------|------------------|
| document_1.pdf | 03/31/2026 | ✅ Required date |
| document_2.pdf | 01/15/2026 | ✅ |
| document_3.pdf | 02/28/2026 | ✅ |
| document_4.pdf | 04/30/2026 | ✅ |
| document_5.pdf | 05/15/2026 | ✅ |
...
Step 2: Retrieving Agent-Generated Files
Agent responses can include file attachments. Here's how to programmatically download them:
import json
import tempfile
# Extract file metadata from the agent's response
agent_files_meta = h2ogpte.list_chat_message_meta_part(
reply.id,
"agent_files"
).content
agent_files = json.loads(agent_files_meta) if agent_files_meta else []
# Download to temporary directory
downloaded_filepaths = []
with tempfile.TemporaryDirectory() as tmpdir:
for f in agent_files:
doc_id = list(f.keys())[0]
if "document_" not in f[doc_id]:
continue
doc_name = f[doc_id]
downloaded = h2ogpte.download_document(tmpdir, doc_name, doc_id)
downloaded_filepaths.append(downloaded)
Result: Successfully downloaded 10 PDF files to a temporary directory for processing.
Step 3: Creating a Collection and Ingesting Documents
Now we upload these documents to h2oGPTe for semantic search and RAG:
collection_id = h2ogpte.create_collection(
name="Agent Generated PDFs",
description='PDFs generated by agent; each with an "Expire Date".'
)
# Upload each PDF
uploads = []
for fp in downloaded_filepaths:
with open(fp, "rb") as f:
upload_id = h2ogpte.upload(os.path.basename(fp), f)
uploads.append(upload_id)
# Ingest into collection
job = h2ogpte.ingest_uploads(collection_id, uploads)
print(f"Ingestion completed: {job.completed}")
Result: All 10 documents successfully ingested into the collection.
Step 4: Extracting Metadata with Structured Schemas
Here's where the API truly differentiates itself. We'll use process_document() with a JSON schema to extract structured metadata and then assign it to each document :
# Define extraction schema
extraction_schema = {
"type": "object",
"properties": {
"expiration_date": {
"type": "string",
"description": "The expiration date found in the document"
}
},
"required": ["expiration_date"]
}
documents = h2ogpte.list_documents_in_collection(
collection_id,
offset=0,
limit=100
)
for doc in documents:
# Extract structured data
extraction = h2ogpte.process_document(
document_id=doc.id,
system_prompt="You are h2oGPTe, an expert question-answering AI system created by H2O.ai.",
pre_prompt_summary="Extract the Expiration Date from the document.",
prompt_summary="Based on the document context you have seen, extract the Expiration Date.",
schema=extraction_schema,
llm="meta-llama/Llama-3.1-8B-Instruct",
llm_args=dict(max_new_tokens=200, enable_vision="off"),
meta_data_to_include={"text": True},
)
# Parse and store metadata
extracted_data = json.loads(extraction.content)
h2ogpte.update_document_metadata(doc.id, document_metadata=extracted_data)
Why This Matters: The schema parameter enforces structured JSON output, making the extraction reliable and parseable. This is far more robust than asking for unstructured text responses.
Execution Results:
Processing: document_1.pdf (ID: 2a2e6723-de5d-4dff-a03d-85bcf83be77d)
Extracted: {'expiration_date': '03/31/2026'}
Saved metadata: {'expiration_date': '03/31/2026'}
Processing: document_2.pdf (ID: 8226c365-da94-4d07-8ca8-43dc54bd9fdf)
Extracted: {'expiration_date': '01/15/2026'}
Saved metadata: {'expiration_date': '01/15/2026'}
Processing: document_3.pdf (ID: 1ed48561-14d0-4444-a091-f6176e7fcca8)
Extracted: {'expiration_date': '02/28/2026'}
Saved metadata: {'expiration_date': '02/28/2026'}
...
Every document now has structured, queryable metadata attached.
Step 5: Querying with Metadata Filters
Finally, we demonstrate the power of metadata-based filtering. Create a chat session connected to the collection and query with filters:
chat_session_id = h2ogpte.create_chat_session(collection_id)
# Query WITH metadata filter
with h2ogpte.connect(chat_session_id) as session:
reply = session.query(
"What is the customer names and amounts",
timeout=240,
metadata_filter={'expiration_date': '03/31/2026'},
include_chat_history=False
)
print(reply.content)
Filtered Query Result (Only documents with expiration_date = '03/31/2026'):
According to the provided document data:
- Customer Name: Customer A Smith
- Amount: $114.28
The system correctly identified and retrieved information from only the single document matching the metadata filter.
Unfiltered Query Result (All documents):
# Query WITHOUT metadata filter
with h2ogpte.connect(chat_session_id) as session:
reply = session.query(
"What is the customer names and amounts",
timeout=240,
include_chat_history=False
)
print(reply.content)
According to the information provided, here are the customer names and their corresponding amounts:
- Customer H Smith: $5554.13
- Customer J Smith: $1114.07
- Customer D Smith: $8605.87
- Customer E Smith: $9475.29
- Customer C Smith: $7787.76
- Customer A Smith: $114.28
- Customer G Smith: $4618.66
- Customer F Smith: $2756.55
- Customer B Smith: $5601.67
- Customer I Smith: $2911.23
Without the filter, the system retrieved information from all 10 documents in the collection.
Why This Workflow Matters for Data Scientists
1. Precision Retrieval
Semantic search is powerful but imprecise for structured queries. Combining it with metadata filters gives you SQL-like precision with semantic flexibility.
2. Automated Document Enrichment
Instead of manually tagging documents, use LLMs with JSON schemas to extract and structure metadata automatically at scale.
3. API-Exclusive Capabilities
The metadata_filter parameters are currently only available through the h2oGPTe SDK, not the web UI. This gives programmatic users significant capabilities for production workflows.
4. Multi-Dimensional Document Organization
This pattern extends beyond dates. Extract:
Document types (invoice, contract, report)
Status codes (active, expired, pending)
Risk levels (high, medium, low)
Geographic regions
Any structured field present in documents
5. Production-Ready Patterns
This workflow demonstrates patterns essential for enterprise RAG applications:
Temporary file handling with context managers
Batch document processing
Error handling for ingestion jobs
Independent queries with include_chat_history=False
Real-World Applications
This pattern is immediately applicable to:
Compliance Management: Filter active vs. expired certifications, permits, or contracts
Invoice Processing: Query by date ranges, vendors, or payment status
Legal Document Review: Filter by jurisdiction, case status, or filing dates
Medical Records: Retrieve records by diagnosis codes, treatment dates, or patient status
Contract Analytics: Filter by contract type, renewal dates, or counterparty
Key Takeaways
h2oGPTe's API unlocks advanced capabilities not available in the UI, particularly around document processing and metadata management
JSON schema-based extraction provides reliable, structured metadata from unstructured documents
Metadata filtering transforms RAG from semantic-only search to hybrid structured+semantic retrieval
Agent-based workflows enable end-to-end automation, from document generation to querying
The pattern is scalable: Handle hundreds or thousands of documents with the same code
Getting Started
If you are new to h2oGPTe, you can visit our free trial environment and get your own API key at h2ogpe.genai.h2o.ai
Conclusion
As RAG applications mature beyond simple Q&A, the ability to precisely filter and organize documents becomes critical. h2oGPTe's API provides the tools data scientists need to build production-grade document processing pipelines with automated metadata extraction and intelligent filtering.
By combining semantic understanding with structured metadata, you can build RAG applications that answer questions like "Show me all expired contracts from Q1" or "What are the high-risk findings from last month's audit?" with accuracy and confidence.
The future of document intelligence isn't just semantic search, it's the intelligent fusion of structured and unstructured data retrieval. With h2oGPTe's API, that future is available today.
For more information about h2oGPTe and the Python SDK, visit H2O.ai or check out the h2oGPTe documentation.







