





Natural Language Processing
Overview
NLP in H2O Driverless AI
Text data can contain critical information to inform better predictions. Driverless AI automatically converts text strings into features using powerful techniques like TFIDF, CNN, and GRU. Driverless AI now also includes state-of-the-art PyTorch BERT transformers. With advanced NLP techniques, Driverless AI can also process larger text blocks and build models using all available data and to solve business problems like sentiment analysis, document classification, and content tagging.
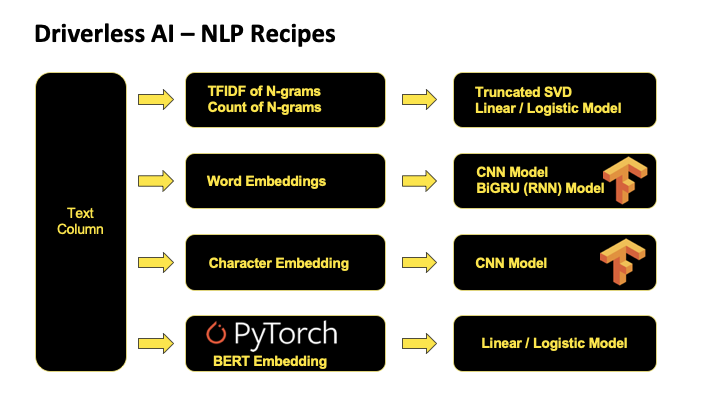
Key Capabilities of Our NLP Recipe
- Frequency of n-grams
- TFIDF of n-grams
- Truncated SVD Features
- Linear models on TFIDF vectors
- Word Embeddings
- Convolutional neural network models on w
- Bi-direction GRU models on word embeddin
- CNN models on character embeddings
- BERT/DistilBERT Transformers
Frequency based features represents the count of each word in the given text in the form of vectors. Frequency based features are created for different n-gram values. The dimensions of the output vectors are quite high. Words / n-grams that occur more number of times will get higher weightage and the ones that are rare will get lesser weightage.
Frequency based features multiplied with inverse document frequency to get TFIDF vectors. The dimensions of the output vectors are high. This also gives importance to the rare terms that occur in the corpus which might be helpful in our classification tasks.
Both TFIDF and Frequency of n-grams result in higher dimension. To tackle this, we use Truncated SVD to decompose the vectorized arrays in lower dimensions. Truncated SVD is a common method to reduce the dimension for text based frequency / tfidf vectors.
In our NLP recipe, we also have linear models on top of n-gram TFIDF / frequency vectors. This capture linear dependencies that are simple yet significant in achieving the best accuracies.
TFIDF and frequency-based models represent counts and significant word information, but they lack semantics of the words in general. One of the popular representations of text to overcome this is Word Embeddings. Word embeddings is a feature engineering technique for text where words or phrases from the vocabulary are mapped to vectors of real numbers. Representations are made in such a way that words that have similar meaning are placed close or equi-distant to each other. For example, words like ‘king’ is closely associated with “queen” in this vector representation.
Although, CNN are primarily used on image level machine learnings tasks their use case on representing text as information in latest research has proven to be quite efficient and faster than compared to RNN models. In Driverless AI, we pass word embeddings as input to CNN models, get cross validated predictions from it and use them as new set of features.
Recurrent neural networks like LSTM and GRU are state of the art algorithms for NLP problems. In Driverless AI, we implement Bi-directional GRU features to both previous word steps and later steps information to predict the current state. For example, in the sentence “John is walking golf court”, a unidirectional model would represent states with represent “golf” based on “John is walking” but not the “court”. Using a bi-directional model, the representation would also account the later representations giving the model more predictive power. Simply, put a Bi-directional GRU model is putting two independent RNN models in one. Taking note of accuracies as well as speed in our experiments, we have decided to take advantage of high speed and almost similar accuracies of GRU architecture compared to its counterpart LSTM.
Natural language processing is complex as the language is hard to understand given small data and different languages. Targeting languages like Japanese, Chinese where characters play a major role, we have character level embeddings in our recipe as well. In character embeddings, each character gets represented in the form of vectors rather than words. Driverless AI uses character level embeddings as input to CNN models and later extract class probabilities to feed as features for downstream models.
BERT pre-trained models deliver state-of-the-art results in natural language processing (NLP). Unlike directional models that read text sequentially, BERT models look at the surrounding words to understand the context. The model are pretrained on massive volumes of text to learn relationships, giving them an edge over other techniques. Using GPU acceleration in H2O Driverless AI, using state-of-the-art techniques has never been faster or easier.
Resources
Watch Industry Experts Making Waves




Natural Language Processing Tutorial
You will learn how to launch a sentiment analysis experiment, walkthrough sentiment analysis experiment settings, NLP Concepts, Driverless AI NLP Recipe and more...
In this tutorial, you will learn how to apply automatic machine learning to build a model to classify customer reviews. You will learn some core NLP concepts and then load a dataset, explore it, run an experiment to build a model and explore the results.
