


Sparkling Water!

H2O & Scala & Spark
Spark is an up and coming new big data technology; it’s a whole lot faster andeasier than existing Hadoop-based solutions. H2 O does state-of-the-art MachineLearning algorithms over Big Data – and does them Fast. We are happy toannounce that H2 O now has a basic integration with Spark – Sparkling Water!
This is a “deep” integration – H2 O can convert Spark RDDs to H2 O DataFrames andvice-versa directly. The conversion is fully in-memory and in-process, anddistributed and parallel as well. This also means H2 O has a (nearly) fullintegration with Scala as well – H2 O DataFrames are full Scala Collectionobjects – and the basic foreach collection calls naturally run distributed andparallel also.
A few months back we announced the start of this initiative: Sparkling Water = H2O + Spark
In that post we went for the quickest integration solution possible: separateprocesses for Spark and H2 O, with a Tachyon bridge. While this worked, itrequired fully 3 copies of all data: a Spark copy, a Tachyon bridge copy, andan H2 O copy – and the data passed through process boundaries repeatedly. Withthis work we need only the Spark and H2 O copies, the data is only copied once,and does not cross a process boundary. It’s both faster and uses less memory.
Scala integration is being showcased before Spark integration simply because weneed to understand H2 O’s Scala integration before we can understand H2 O’s Sparkintegration.
H2O’s Scala API
As always, the code is open source and available on github. This code is allin 0xdata’s “h2o-dev” repro – a clean-slate dev friendly version of H2 O. As ofthis writing, h2o-dev has all the core h2o logic, and about 50% of the machinelearning algos (and the rest should appear in a month).> https://github.com/0xdata/h2o-dev/
The basic scala wrappers are here:> https://github.com/0xdata/h2o-dev/tree/master/h2o-scala/src/main/scala/water/fvec/DataFrame.scala
https://github.com/0xdata/h2o-dev/tree/master/h2o-scala/src/main/scala/water/fvec/MapReduce.scala
And some simple examples here:> https://github.com/0xdata/h2o-dev/blob/master/h2o-scala/src/test/scala/water/BasicTest.scala
The idea is really simple: a Scala DataFrame extends an H2 O Javawater.fvec.Frame object.scalaThe Scala type is a
class DataFrame private ( key : Key, names : Array[String], vecs : Array[Vec] )
extends Frame(key,names,vecs)
with Map[Long,Array[Option[Any]]] {
Map[Long, Array[Option[Any]]] – a map from Long rownumbers to rows of data – i.e. a single data observation. The observationis presented as an Array of Option[Any] – array elements are features in theobservation. H2 O fully supports the notion of missing elements or data – andthis is presented as a Scala Option type. Once you know a value is not“missing” – what exactly is it’s type? H2 O Vecs (columns) are typed to holdone of these types:- a Number (Java double conceptually, but any of boolean, byte, char, int, float, long, double) – a String – a Factor/Enum (similar to interned Strings that are mapped to small dense integer values) – a Timestamp (stored internally as milliseconds since the Unix Epoch) – a UUID
A DataFrame can be made from a Spark RDD or an H2 O Frame directly or from a CSV file:
val df1 = new DataFrame(new File("some.csv"))
Column subsets (a smaller dataframe) can be selected via the column name:scala
val df2 : DataFrame = df2('a_column_header,'age,'id)
You can do a basic foreach:scalaAnd this will run distributed and parallel across your cluster!
df2.foreach( case(x,age,id) => ...use x and age and id... )
The code for foreach is very simple:scala
override def foreach[U](f: ((Long, T)) => U): Unit = {
new MRTask {
override def map( chks : Array[Chunk] ) = {
val start = chks(0)._start
val row = new T(chks.length)
val len = chks(0).len
(0 until len).foreach{ i =>
(0 until chks.length).foreach{ col => row(col) = if( chks(col).isNA0(i) ) None else Some(chks(col).at0(i)) }
f(start+i,row)
}
}
}.doAll(this)
}
More complicated examples showing e.g. a scala map /reduce paradigm will follow later.
WaterWorks – Flowing Data between Spark and H2O
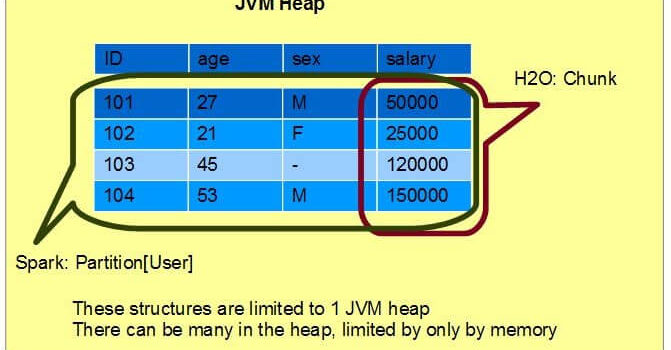
Let’s turn to Spark now, and show H2 O and Spark working together. Spark RDD’sand H2 O Frames are similar – but not equal – ways to manage large distributeddata. Basically RDDs are a collection of blocks (Partitions) of rows, andFrames are a collection of columns, aligned in rows and broken up in Chunks.Sort of a blocks-vs-stripes thing.
H2 O represents data in columns (Vecs in H2 O lingo) vertically stripedacross the cluster; a Frame is a collection of columns/Vecs. Vecs, in turn,are broken up into Chunks – and the Chunks are carefully aligned in the JVMheaps such that whole rows of data (all the columns in a Frame) align.
Spark represents data in RDDs (Resilent DistributedDataset) -a Collection of elements. Each RDD in broken up in turn into Partitionsblocked across the cluster; each Partition holds a subset of the Collection ascomplete rows (or observations in data-science parlance).
H2 O Frames, Vecs and Chunks can represent any primitive Numeric type, Strings,timestamps, and UUIDs – and support the notion of a missing value. RDDs canrepresent a collection of any Scala or Java object. If we limit the objects tocontaining fields that H2 O represents then we can build a simple mappingbetween the two formats.
For our example we’ll look at a collection of Users:scala
class User(
id: Long,
age: Option[Short],
sex: Option[Boolean],
salary: Int
)
In Scala, this is typed as RDD[User], and we’ll have 1 User object per realUser, blocked in Partitions around the cluster. In H2 O, DataFrames naturallyhold all numeric types and missing values in a column format; we’ll have 4columns each holding a value for each user again distributed in Chunks aroundthe cluster. Here’s a single Partition hold 4 users, and showing 4 Chunks (oneper column):

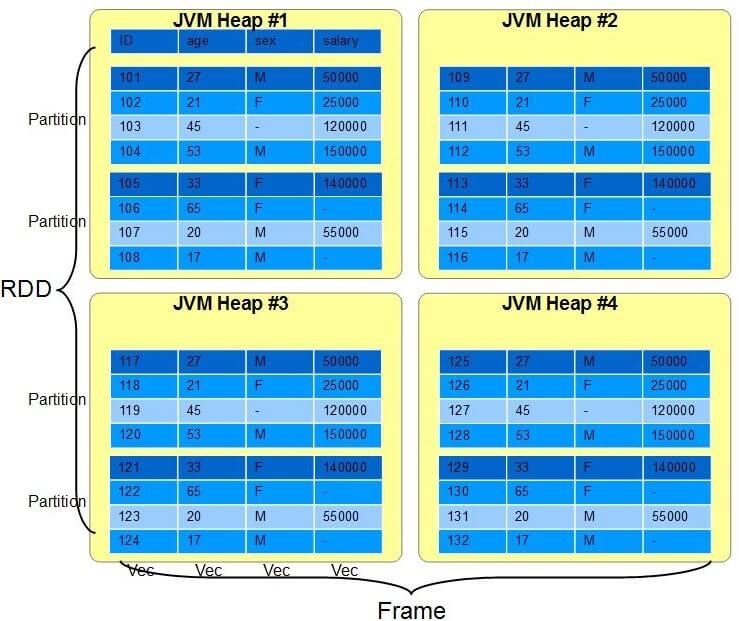
Here’s 4 JVM heaps holding all 32 users. There are 8 partitions (two per JVM)and 32 Chunks in 4 Vecs striped around the cluster:
An Example: Back and Forth between H2O and Spark
Here’s a simple Scala example; we’ll assume we have the 4-node Sparkling Watercluster above and a CSV (or Hive) file on disk. We’ll use a simple Userdatafile featuring just a unique id, the user’s age, sex and salary. From justthe age and sex we’ll try to predict the typical salary using DeepLearning .
First we load the CSV file into H2 O. H2 O features a fast robust CSV parser whichis able to ingest CSV data at full disk bandwidths across a cluster. We canhandle a wide variety of CSV formats (e.g. Hive is a CSV with ^A/0x01 fieldseparators) and typically automatically infer all column types. Unlike Spark,operations in H2 O are eager not lazy , so the file is loaded and parsedimmediately:scala
// Load an H2O DataFrame from CSV file
val frameFromCSV = new DataFrame(new File("h2o-examples/smalldata/small_users.csv"))
Then we’ll convert to a Spark RDD – like all RDD operations, this conversion islazy ; the conversion is defined but not executed yet:scala
val sc = createSparkContext()
val table : RDD[User] = H2OContext.toRDDUser
And then run an SQL query! SQL is a great way to subselect and munge data, and isone of Spark’s many strengths.scala
table.registerTempTable("user_table") // The RDD is now an SQL table
val query = "SELECT * FROM user_table WHERE AGE>=18" // Ignore underage users
val result = sql(query) // Run SQL query
Then we’ll convert back to an H2 O DataFrame – and run H2 O’s Deep Learning(NeuralNets) onthe result. Since H2 O operations are eager, this conversion triggers theactual SQL query to run just before converting.
// Convert back to H2O DataFrame
val frameFromQuery = H2OContext.toDataFrame(sc,result)
Now it’s time for some Deep Learning . We don’t want to train a Deep Learningmodel using the ID field – since it is unique per user, its possible that themodel learns to spot interesting user features from the ID alone – whichobviously does not work on the next new user that comes along! This problemis calledoverfitting and H2 O’s algorithms all have robust features to avoid it – but in this casewe’ll just cut out the id column by selecting a subset of features to train onby name:scala
val trainFrame = frameFromQuery('age,'sex,'salary)
Deep Learning has about 60 parameters, but here we’ll limit ourselves to setting just a fewand take all the defaults. Also note that sometimes the age or sex informationis missing; this is a common problem in Data Science – you can see it in theexample data. DataFrames naturally support this notion of missing data.However each of the Machine Learning algorithms in H2 O handle missing datadifferently – the exact behavior depends on the deep mathematics in thealgorithms. See this video for an excellent discussion on H2O’s DeepLearning .“`scala// Deep Learning!// – configure parametersval dlParams = new DeepLearningParameters()dlParams.source = trainFramedlParams.response = trainFrame(‘salary)
// Run Deep Learning. The train() call starts the learning process// and returns a Future; the training runs in the background. Calling// get() blocks until the training completes.val dlModel = new DeepLearning(dlParams).train.get“`
At this point we have a Deep Learning model that we can use to make predictionsabout new users – who have not shared their salary information with us. Thosepredictions are another H2 O DataFrame and can be moved back and forth betweenH2 O and Spark as any other DataFrame. Spark and Scala logic can be used to driveactions from the predictions, or just used in further in a deep RDD and H2 Opipeline.
Summary
In just a few lines of Scala code we now blend H2 O’s Machine Learning andSpark’s data-munging and SQL to form a complete ML solution:* Ingest data, via CSV, existing Spark RDD or existing H2 O Frame* Manipulate the data, via Spark RDDs or as a Scala Collection* Model in H2 O with cutting-edge algorithms* Use the Model to make Predictions* Use the Predictions in Spark RDDs and Scala to solve our problems
In the months ahead we will be rounding out this integration story – turningbrand-new functionality into a production-ready solution.
I hope you like H2 O’s new Spark and Scala integration – and always we are veryexcited to hear your feedback – and especially code to help further this goodcause! If you would like to contribute – please download the code from Git andsubmit your pull requests – or post suggestions and questions onh2ostream.
Cliff