







From Kaggle Grand Masters’ Recipes to Production Ready in a Few Clicks
Introducing Accelerated Automatic Pipelines in H2O Driverless AI
At H2O, we work really hard to make machine learning fast, accurate, and accessible to everyone. With H2O Driverless AI, users can leverage years of world-class, Kaggle Grand Masters experience and our GPU-accelerated algorithms (H2O4GPU ) to produce top quality predictive models in a fully automatic and timely fashion.
In our most recent release (version 1.1), we are going one step further to streamline the deployment process with MOJO (M odel O bJ ect, O ptimized). Inherited from our popular H2O-3 platform, MOJO is a highly optimized, low-latency scoring engine that is easily embeddable in any Java environment. With automatic pipeline generation in Driverless AI, users can go from automatic machine learning to production ready in just a few clicks. This blog post illustrates the usage of MOJO in Driverless AI with a simple example.
Easing the Pain Points in a Machine Learning Workflow
In a typical enterprise machine learning workflow, there are many things that could go wrong due to human errors, bad data science practices, different tools/infrastructure, incompatible code, lack of testing, versioning, communication and so on.
Driverless AI is our solution to ease those pain points in the second half of the workflow (i.e., creative feature engineering , model building, and deployment). We strongly believe that most organizations can benefit from automatic machine learning pipelines. A recent PayPal use-case shows that Driverless AI can help produce top quality predictive models with significant time and cost savings.
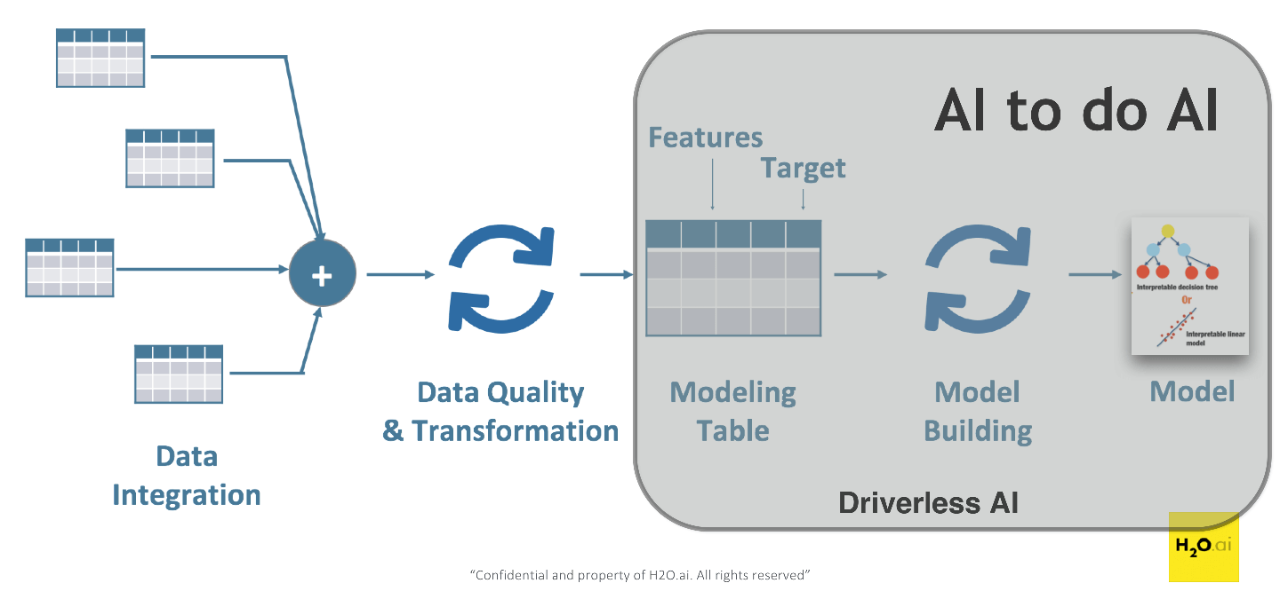
With Driverless AI, we are trying to mimic what top data science teams would do when they need to develop a new machine learning pipeline. Below are the four key areas of focus:
- Exploratory Data Analysis (EDA) with Automatic Visualizations (AutoViz)
AutoViz allows users to gain quick insights from data without the laborious tasks of creating individual plots. It shows users the most interesting graphs automatically based on statistics, and it is designed to work on large datasets efficiently. The mastermind behind AutoViz is our Chief Scientist, Professor Leland Wilkinson of “ The Grammar of Graphics” fame. - Automatic Feature Engineering and Model Building
We call this part of Driverless AI “ Kaggle Grand Masters in a Box”. It is essentially the best data science practices, tricks and creative feature engineering of our Kaggle Grand Masters translated into an artificial intelligence (AI) platform. In other words, it is AI to do AI. On top of that, we make the automatic machine learning process insanely fast on Nvidia GPUs. Our users can benefit from quick turnaround time and top quality predictive models that one would expect from the Kaggle Grand Masters themselves. - Machine Learning Interpretability (MLI)
In Driverless AI, we have implemented some of the latest ML interpretation techniques (e.g., LIME, LOCO, ICE, Shapely, PDP, etc.), so our users can go from model building to model interpretation in a seamless fashion. These techniques are crucial for those who must explain their models to regulators or customers. The masterminds behind MLI are my colleagues Patrick Hall, Navdeep Gill, and Mark Chan. Watch their talk about MLI in Driverless AI here. - Automatic Pipelines Generation – The Focus of this Blog Post
Model deployment remains one of the most common and complex challenges in data analytics. Inherited from our popular H2O-3 platform, MOJO is a well-tested, robust technology that is being used by our users and customers at enormous scale. Let me illustrate the MOJO usage with a simple example below.
Credit Card Example
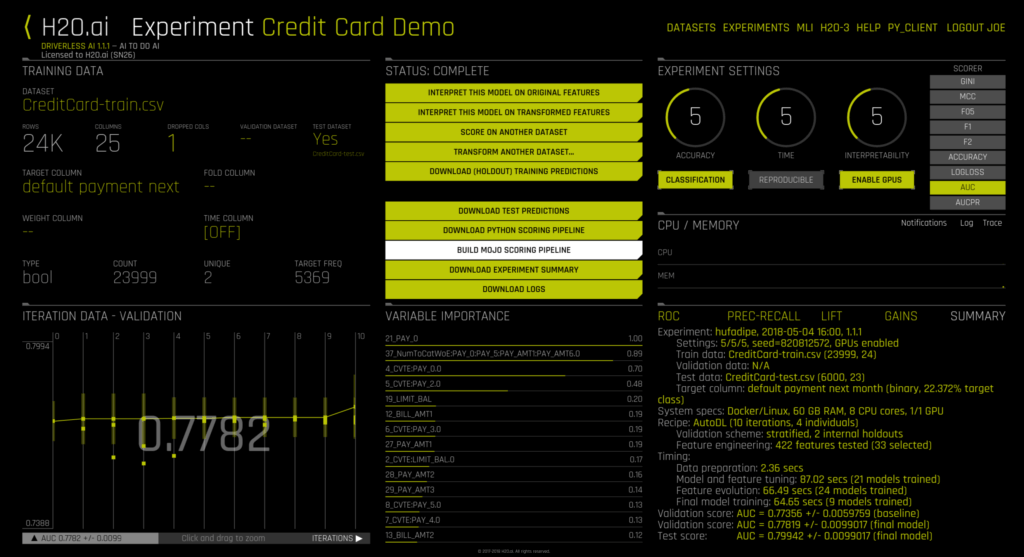
Like many other Driverless AI demos that you may have seen before at H2O World or our webinars, I am going to use the credit card dataset from the UCI machine learning repository for the MOJO example. Let me fast-forward the process to the end of a Driverless AI experiment and focus on the new MOJO options. From version 1.1.0, users have the option to build and download MOJO for fast, low-latency scoring. Here is a step-by-step walkthrough:
Step 1: Build a MOJO Scoring Pipeline
After the experiment, click on the newly available option BUILD MOJO SCORING PIPELINE . The build process is automatic and it should be done within a few minutes.
Step 2: Download and Unzip MOJO
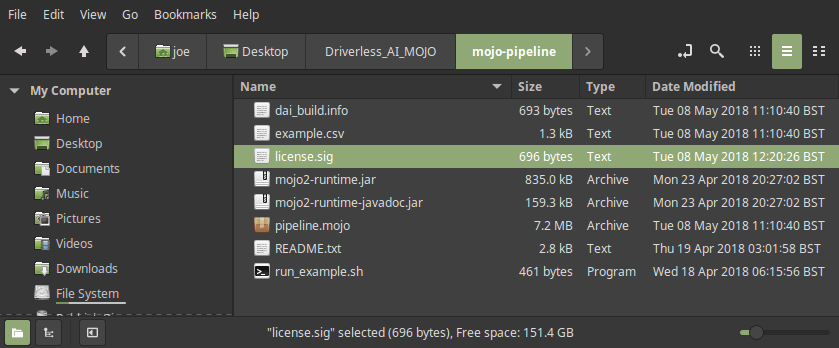
Click on DOWNLOAD MOJO SCORING PIPELINE to download mojo.zip . After unzipping the file, you should be able to see a new folder called mojo-pipeline . The pipeline.mojo and mojo2-runtime.jar in the folder are the two main files you need for the MOJO scoring pipeline.
Step 3: Download Driverless AI License
Another key ingredient for MOJO pipeline is a valid Driverless AI license. You can download the license.sig file (usually in the license folder) from the machine hosting Driverless AI. Put the license file into the mojo-pipeline folder from the previous step.
Optional Step: Install Java 7 or 8
The MOJO scoring pipeline requires Java 8 (or Java 7/8 from version 1.1.2). If you have not installed it, please follow the instructions here .
Step 4: A Simple Test Run
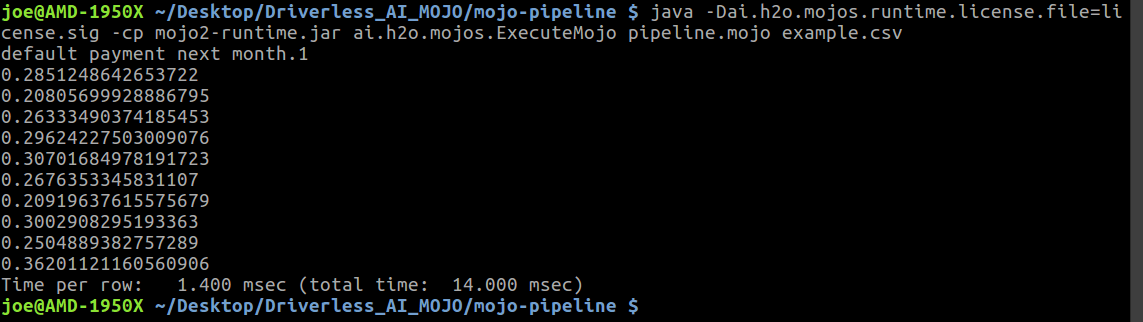
In the mojo-pipeline folder, you will find a small example.csv with some data samples. This dataset can be used for a quick test run. Open the folder in terminal and then run the following command: bash run_example.sh
Alternatively, run the full command like this:
java -Dai.h2o.mojos.runtime.license.file=license.sig -cp mojo2-runtime.jar ai.h2o.mojos.ExecuteMojo pipeline.mojo example.csv
It should return predictions (the probabilities of default payment in this credit card demo) and the time required for scoring each sample. Remember this scoring pipeline includes everything from complex feature transformations based on Kaggle Grand Masters’ recipes to computing predictions from the final model ensemble. With MOJO, our users have a low-latency scoring engine that can make new predictions in milliseconds .
Step 5: Create Your Own Scoring Service
Users can, of course, define and program their own scoring services. For more information, please go through the Compile and Run the MOJO from Java section in our Driverless AI documentation .
Conclusions
This blog post gives a quick overview of the automatic pipelines in Driverless AI. The key benefits for our users are:
- Immediate increase in productivity – eliminating time wasted on human errors, incompatible code, debugging, etc.
- Production ready in a few clicks – seamless integration of complex feature engineering and scoring engine in one MOJO.
- An enterprise-grade, low-latency scoring engine that is easily embeddable in any Java environment.
Don’t take my words for it, sign up for a free 21-day trial and try Driverless AI yourself today .
Until next time,
Note #1 : Two years, numerous H2O models, slide decks, events and #360selfies later, I am finally making a return to blogging. I hope you enjoy reading this blog post.
Note #2 : H2O is going to Budapest again. Come find me, Erin, and Kuba at eRum conference from May 14 to 16. I will be delivering the “Automatic and Interpretable Machine Learning in R with H2O and LIME” workshop with a real, multimillion-dollar Moneyball Shiny app.







