







AI for Smarter Manufacturing
Code 3
Manufacturing is a centuries old industry and has seen significant changes dating back to the first Industrial Revolution in the late 18th century. The use of conveyor belt assembly lines to replace assembly workers, newer precision robot technologies to further reduce manufacturing time, advances in ERP, historian databases, storage and computing technologies for efficient part ordering, plant monitoring and supply chain management are just a few examples of disruption that this industry has seen.
Over the recent decades, the manufacturing industry has evolved into a variety of different types depending on the vertical:
- Electronics and device manufacturing
- Food production, packaging and processing plants
- Medical device manufacturing
- Semiconductor test equipment manufacturing
- Heavy manufacturing (automotive, etc).
Although each of the above are in very different markets, the challenges that each of them face are fairly similar. They all require the following at a minimum:
- Failure predictability of machines
- Optimization of the productivity of the equipment
- In-depth product yield analysis
- Optimal routing of raw material to the manufacturing plant, of finished goods to delivery locations, with minimal product waste in transit and at the least cost possible.
- Achieve the perfect balance between supply and demand to reduce inventory cost
- Customer usage statistics and market feedback on product quality
Now, to say that these are all difficult to achieve would be an understatement. Let’s take an example.
Predicting machine failure requires historical data points of past failures, near failures, maximum time between failures (MTBF), correlations between the various sensors deployed in a machine along with external data such as weather, maintenance logs and so on. Once you have the requisite data, a data scientist would need to accomplish a few key steps:
| # | Description of Step | Examples |
|---|---|---|
| 1 | The data scientist would need a way to extract the right features or combine a few of these variables to generate a new feature that help with developing the model. | A feature, in this case, could be the physical characteristics of the sensors embedded in the machinery (simpler), or a weighted combination of temperature variation and frequency of incoming sensor data (derived). |
| 2 | The data scientists would have to select a machine learning framework and pick a set of algorithms and models that might work best in this scenario, out of the several thousand models that the data science community has written thus far. | PyTorch, XGBoost, TensorFlow, sklearn, Pandas and H2O are a few well-known libraries and frameworks (a.k.a. open source repositories) of ML models. Each library is a rich set of models developed by the community over the recent years. |
| 3 | They would then have to tune the parameters of the model to overcome over- or underfitting. | The individual weights on statistical functions, depth of a decision tree, number of trees, to help predict machine failure in exactly the stipulated time. |
| 4 | This would then lead to a discussion on how the model should be deployed on the target. | Deploying the model on the machine itself along with the runtime environment or a nearby gateway device where the data from other machines is also collected, or in the central datastore (in the cloud or on-premises data warehouse). |
As you can imagine, a seemingly simple problem can easily be perceived as a very complex task to accomplish.
This is where a platform like the H2O Driverless AI can come handy.
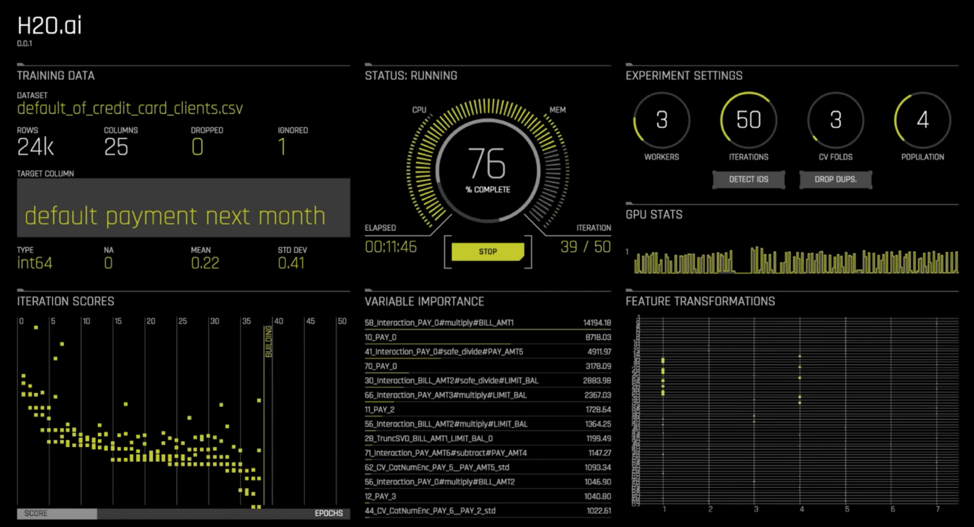
H2O Driverless AI is a leading-edge platform that automates all of the above steps, resulting in drastic reduction in time taken from start of the project all the way to the point when a business can glean and review real-time actionable insights.
Again, let’s take an example set of steps to describe how the data scientist can accomplish all of this within the platform:
- After they bring the relevant training data on the platform via a simple CSV upload or through one of our cloud or HDFS connectors, they would select the target column or variable to be predicted. In this case, this would perhaps be something like “Time to failure in less than 4 days”.
- They would then select the accuracy, time and interpretability parameters that the platform should use in order to decide the extent of compute the user wants it to do before showing the final results.
- Depending upon the dataset, the user also gets the flexibility to use GPUs for faster compute, instead of CPUs.
- They would then ask Driverless AI to build the model. At that point, the platform will take a few minutes to iterate over potentially 1000s of models (not exaggerating here!!), tune the hyperparameters of the model to fit into the criteria of accuracy provided earlier and conclude on the importance of the variables in decreasing order. As the platform works on the dataset, all of this would be visible to the user on the UI itself.
- Finally, once the model is ready, there are several deployment options to choose from. If they already have Java runtime libraries setup in the target environment, they could use the POJO or MOJO files that the platform provides as an output – particularly for on-premises or edge deployments. Alternatively, this can be deployed in the AWS Sagemaker, or just simply create a RESTful endpoint with an API key and a model ID for a web application to access it.
The benefits of using the Driverless AI platform go well beyond the above-mentioned descriptions. The algorithms and scorers are built by the H2O.ai’s data science community and curated by the Kaggle Grand Masters at H2O.ai. Moreover, with the new concept of BYO Recipes introduced in Driverless AI, the extent of flexibility and extensibility that the platform provides goes beyond the imagination.
For more information, please refer to the AI in Manufacturing solution brief, or check out some of successful customer stories in manufacturing here .







