







H2O Integrates with Snowflake Snowpark/Java UDFs: How to better leverage the Snowflake Data Marketplace and deploy In-Database
One of the goals of machine learning is to find unknown predictive features, even hidden from subject matter experts, in datasets that might not be apparent before, and use those 3rd party features to increase the accuracy of the model.
A traditional way of doing this was to try and scrape and scour distributed, stagnant data sources on the web and cross your fingers you would see some performance gain when doing model validation. An example of this would be scraping stock prices or GDP prices to see if the economy had an effect on things. One potentially better solution was Snowflake’s Data Marketplace, which allowed people to more easily share up-to-date datasets, but the requirement to work in SQL made it troublesome.
Today, we are excited to announce integrations with Snowflake’s Snowpark and Java UDFs, Snowflake’s new developer experience. This essentially opens up access to Snowflake’s Data Marketplace to data scientists and developers, now allowing 3rd party unique datasets that can help improve model accuracy and deliver better business outcomes to be included in their often standard notebook based programming approaches.
Snowpark is a client-side library that pushes client-side logic into Snowflake. Within a Virtual Warehouse, Java User Defined Functions (UDFs) can be run that contains your choice of code.
Snowflake’s new feature Snowpark enables the data in Snowflake to be available as a dataframe using Scala, and the Java UDF feature allows Java code to be executed as a user defined function (UDF) within the Snowflake environment. Meaning once we trained our model on our data plus the 3rd party data we like in the Snowflake marketplace, we can import the model into where the data lives for an easier path to deployment. For the data scientist, this opens up an amazing opportunity to use familiar H2O.ai tools and models, but use the power and scaling of the Snowflake platform.
To show an example, we will discuss how to use the Snowflake Data Marketplace to access a dataset from a company, Infutor Data Solutions, that has shared demographic data, and we want to use that with our existing dataset (to predict loan defaults with LendingClub data) in Snowflake.
The first step is to create a table based on the Infutor dataset. Then, we will average some columns and group them, so that they can be used.
val DataMarketPlaceDF = session.sql("CREATE or REPLACE TABLE DataMarketPlacePropertyAverage AS SELECT STATE, ROUND(avg(PROP_VALCALC),0) as PROP_VALCALC FROM Infutor_AV10424_TOTAL_DEMOGRAPHIC_PROFILES_100 GROUP BY State;")The Snowflake marketplace data can then be used as a reference table. We can use the Snowpark API to create this reference table:
val PropertyAverageDF = session.table("DataMarketPlacePropertyAverage")
PropertyAverageDF.show()
println("Number of rows created at State level: %s",PropertyAverageDF.count())Snowpark makes it simple to join the two tables:
// Create Dataframe with Lending Club Data
val LendingDF = session.table("LENDINGCLUB")
LendingDF.show()
// Join Dataframes based on State
val enrichedDF = LendingDF.join(PropertyAverageDF,
LendingDF.col("ADDR_STATE") === PropertyAverageDF.col("STATE"))The table will now contain the average property value for each row in the original table. All of these operations occur in Snowflake, so scaling and the time to complete this operation is very fast.
The next step is to save this new dataframe and invoke Driverless AI training:
// Save new Dataframe to table and start training
enrichedDF.write.mode(SaveMode.Overwrite).saveAsTable("LENDINGCLUBwithPropertyAverage")
println("Calling Training with new Table")
val training = session.sql("select H2OTrain('Build --Table=LENDINGCLUBwithPropertyAverage --Target=BAD_LOAN --Clone=Yes --Modelname=riskmodelPropertyAverage.mojo')")
training.show()This operation uses another unique Snowflake feature, Snowflake External Functions, which enables a table to be used with Driverless AI. The result is a model that is built using the advanced feature engineering and modeling capabilities offered by Driverless AI.
Once the model is trained, it is automatically deployed. It is available within the Snowflake environment, and we are now able to use the model directly in Snowflake using the Snowpark and Java UDF features.
// call the model using SQL until Java UDF is auto deployed, then use session.table()
val resultDF = session.sql("SELECT id, H2OPredictN('Modelname=riskmodel.mojo', LOAN_AMNT, TERM, INT_RATE, INSTALLMENT, EMP_LENGTH, HOME_OWNERSHIP, ANNUAL_INC, VERIFICATION_STATUS, ADDR_STATE, DTI, DELINQ_2YRS, INQ_LAST_6MNTHS, PUB_REC, REVOL_BAL, REVOL_UTIL, TOTAL_ACC ) as H2OPrediction, H2OPredictPV('Modelname=riskmodelPropertyAverage.mojo', LOAN_AMNT, TERM, INT_RATE, INSTALLMENT, EMP_LENGTH, HOME_OWNERSHIP, ANNUAL_INC, VERIFICATION_STATUS, ADDR_STATE, DTI, DELINQ_2YRS, INQ_LAST_6MNTHS, PUB_REC, REVOL_BAL, REVOL_UTIL, TOTAL_ACC ) as H2OPredictionWithPropertyValue from lendingclub")
resultDF.show()The model executes and makes predictions in Snowflake. The key theme here is: the data does not leave the Snowflake environment, and it automatically scales with the size of the warehouse you’ve selected.
What is nice is that the Snowpark Scala and Java UDF code is all auto-generated for the Data Scientist.
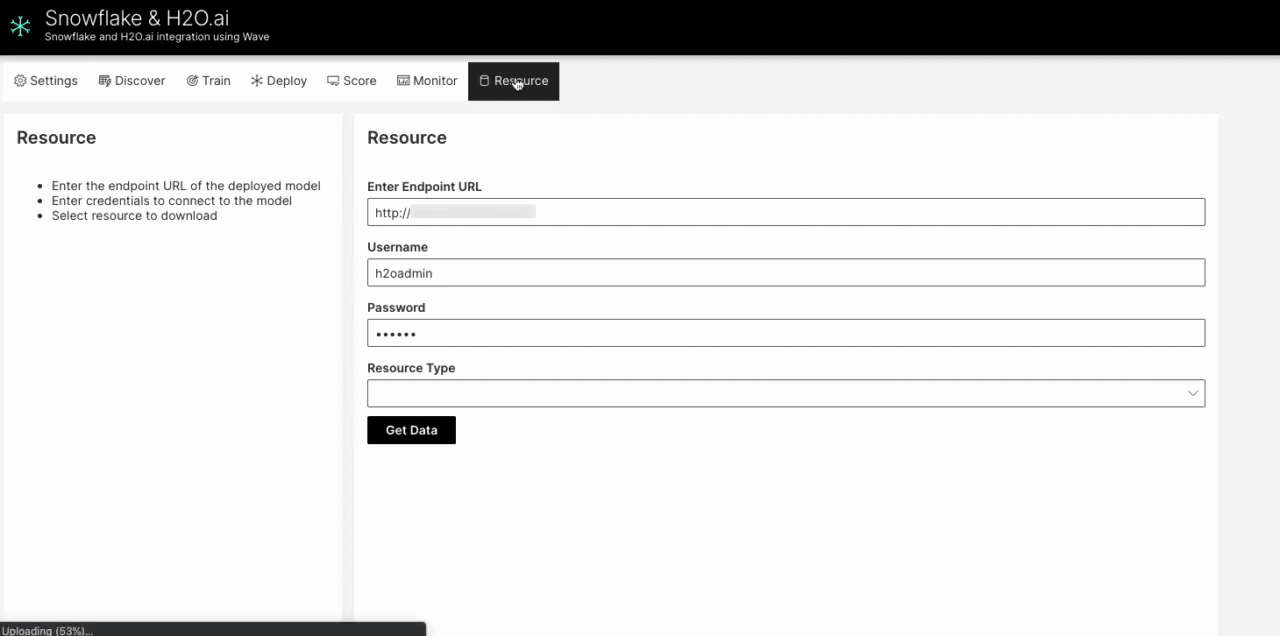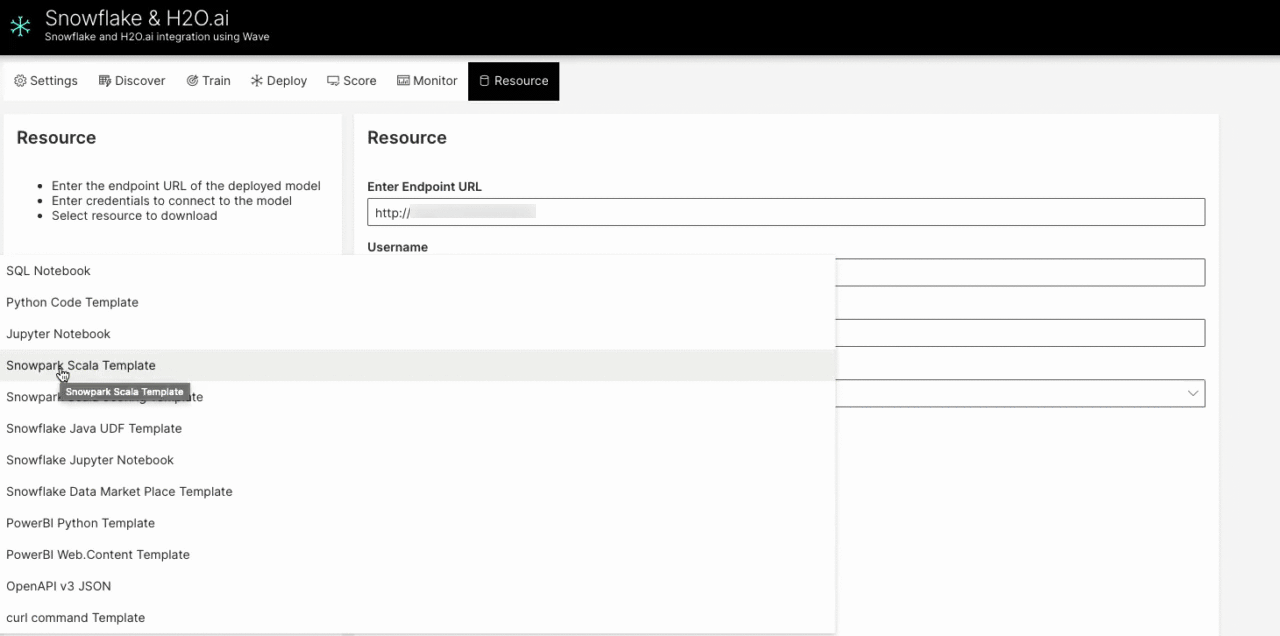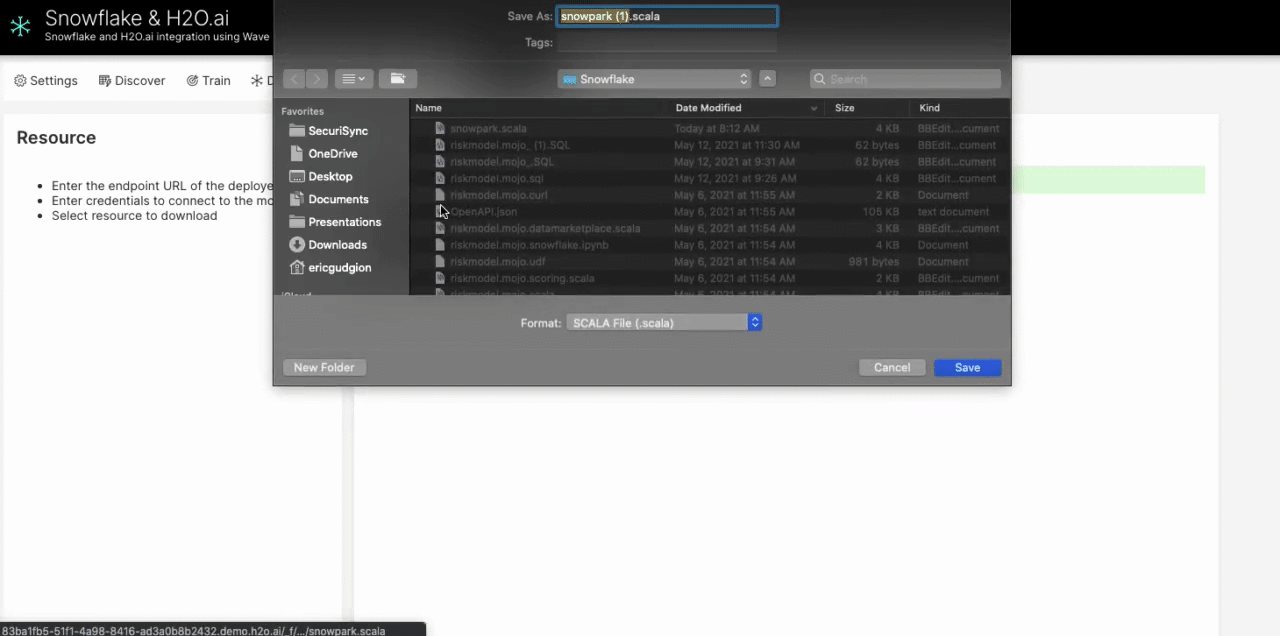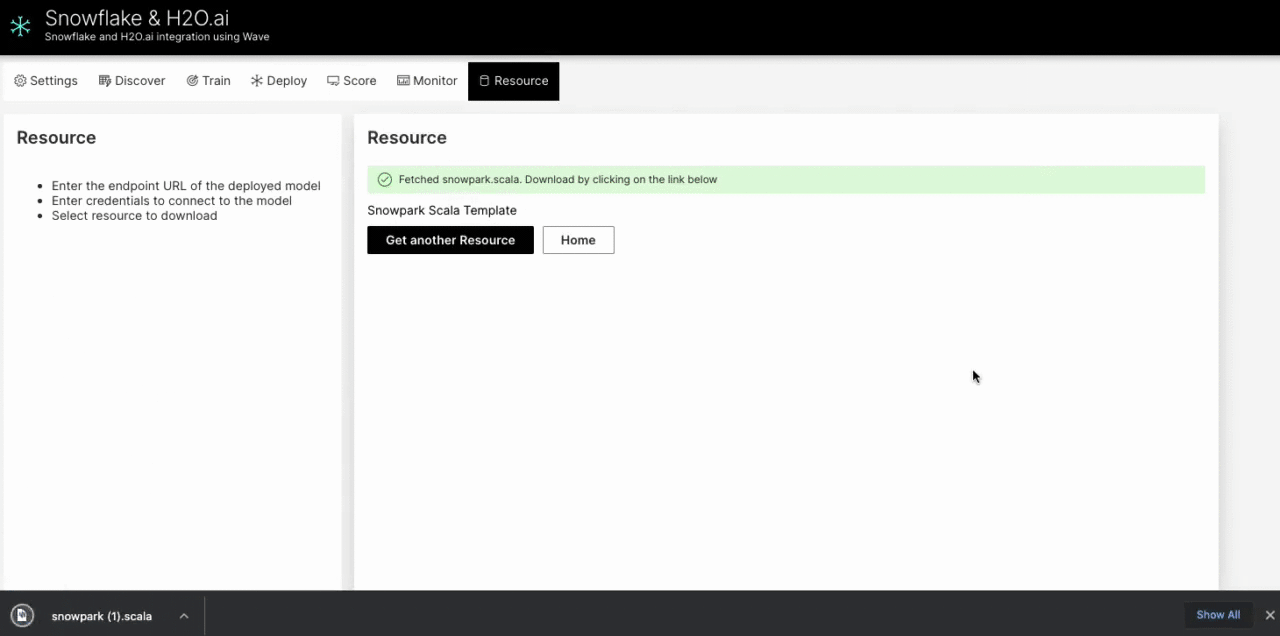
Using the Infutor data, we were able to improve the model’s accuracy and score at scale within the Snowflake environment.
About the Authors

Eric Gudgion
Eric is a Senior Principal Solutions Architect at H2O.ai and works with customers on deploying machine learning models into production environments.

Miles Adkins
Miles is a Partner Sales Engineer at Snowflake and leads the joint technical go-to-market for Snowflake’s machine learning and data science partners.







