




H2O LLM DataStudio: Streamlining Data Curation and Data Preparation for LLMs related tasks

A no-code application and toolkit to streamline data preparation tasks related to Large Language Models (LLMs)
H2O LLM DataStudio is a no-code application designed to streamline data preparation tasks specifically for Large Language Models (LLMs). It offers a comprehensive range of preprocessing and preparation functions such as text cleaning, text quality detection, tokenization, truncation, and the ability to augment the dataset with external and RLHF datasets. The processes and workflows include: question-answer datasets, instruction-response datasets, continue pertaining, human bot conversations etc.

The importance of cleaned data in NLP downstream tasks after fine-tuning lies in its ability to improve the reliability, performance, and ethical considerations of the models. The benefits include – Enhanced Model Performance, Reduced Bias and Unwanted Influences, Consistency and Coherence, Improved Generalization, Ethical Considerations, User Experience, and Trust.
To ensure the quality of datasets is met, one of the first steps in building your own LLM or working with LLMs is the data preparation process. It starts with the ingestion of datasets from various sources, tailored to serve a specific purpose such as continued pretraining, instruct tuning, chatbot development, or RLHF protection. This is followed by an intensive data cleaning stage, where subpar data segments are meticulously identified and eliminated, ensuring the removal of potential noises such as lengthy sequences of spaces or anomalous characters that could disrupt subsequent analysis or modeling efforts. In the pursuit of data quality assurance, a strict data quality checking procedure needs to be implemented, employing advanced techniques like BLEU/METEOR/similarity or RLHF reward models to detect and filter out data of inferior quality. Further refining measures, including length-based filtering to distinguish between concise and extensive answers, and profanity checks to maintain data appropriateness, needs to be applied at this step. This comprehensive process needs to be mapped out in a multi-step workflow, providing a clear visualization of each phase. Upon completion of these refinement procedures, the polished data can be exported in user-preferred formats, facilitating seamless integration with other tools such as the fine-tuning studio.
H2O LLM DataStudio is equipped with all these procedures and provides a smooth experience to users in preparing the datasets for LLM Fine tuning and other related tasks.
Supported Workflows
LLM DataStudio supports a wide range of workflows and task types, offering the necessary tools to simplify and streamline your data preparation efforts. This includes:
- Question and Answer: These datasets comprise contextual information, questions, and their corresponding answers. The application’s features enable the creation of well-structured datasets, vital for training models that can accurately respond to user queries based on the given context.
- Text Summarization: This workflow focuses on datasets containing articles and their associated summaries. The LLM DataStudio tools facilitate the extraction of essential information from the articles, enabling the creation of concise summaries encapsulating key points. These prepared datasets can be used to train text summarization models capable of generating succinct and informative summaries from lengthy text.
- Instruct Tuning: Datasets containing prompts or instructions and their respective responses. These datasets are critical for training models that can comprehend and adhere to given instructions and accurately respond to user prompts.
- Human-Bot Conversations: This workflow involves datasets comprising multiple dialogues between human users and chatbots. These datasets are pivotal for training models that can understand user intents and provide appropriate responses, leading to enhanced conversational experiences.
- Continued PreTraining: For this workflow, LLM DataStudio assists in preparing datasets with extensive texts for further pretraining of language models. The dataset preparation process focuses on organizing long text data, enabling the language models to learn from a wide range of linguistic patterns. This contributes to improved language understanding and generation capabilities.
Key Techniques
LLM DataStudio supports a multitude of functions to facilitate the preparation of datasets for various task types. The primary goal is to structure data optimally for maximal model performance. Here is an overview of the key functions available:
- Data Object: Allows input of datasets for all task types.
- Data Augmentation: Enables the mixing or augmentation of multiple datasets together for all task types.
- Text Cleaning: Offers a range of cleaning methods to clean text data for all task types.
- Profanity Check: Identifies and removes texts containing profanity, applicable for question and answer, instruct tuning, human-bot conversations, and continued pretraining tasks.
- Text Quality Check: Checks and filters out any low-quality texts for question and answer, instruct tuning, human-bot conversations, and continued pretraining tasks.
- Length Checker: Filters the dataset based on user-defined minimum and maximum length parameters for all task types.
- Valid QnA: Calculates the similarity score and filters the dataset based on a similarity threshold specifically for question and answer tasks.
- Pad Sequence: Enables the padding of sequences based on a maximum length parameter for all task types.
- Truncate Sequence by Score: Allows truncation of the sequence based on a score and max length parameter, required for all task types.
- Compression Ratio Filter: Filters text summarization data by comparing the compression ratio of the summaries.
- Boundary Marking: Adds start and end tokens at the boundaries of the summary text, specifically for text summarization tasks.
- Sensitive Info Checker: Identifies and removes any texts containing sensitive information, critical for instruction tuning tasks.
- RLHF Protection: Appends datasets to facilitate RLHF for all task types.
- Language Understanding: Checks the language of text, allows filtering based on user inputs or threshold, beneficial for all task types.
- Data Deduplication: Calculates text similarity within the dataset, and removes text based on a duplicate score threshold for all task types.
- Toxicity Detection: Calculates toxicity scores for text objects and filters according to the threshold, beneficial for all task types.
- Output: Converts the transformed dataset to an output object such as JSON, applicable for all task types.
No Code Web Interface
Create a project, ingest datasets, define the workflow – select the techniques to be applied to the datasets:
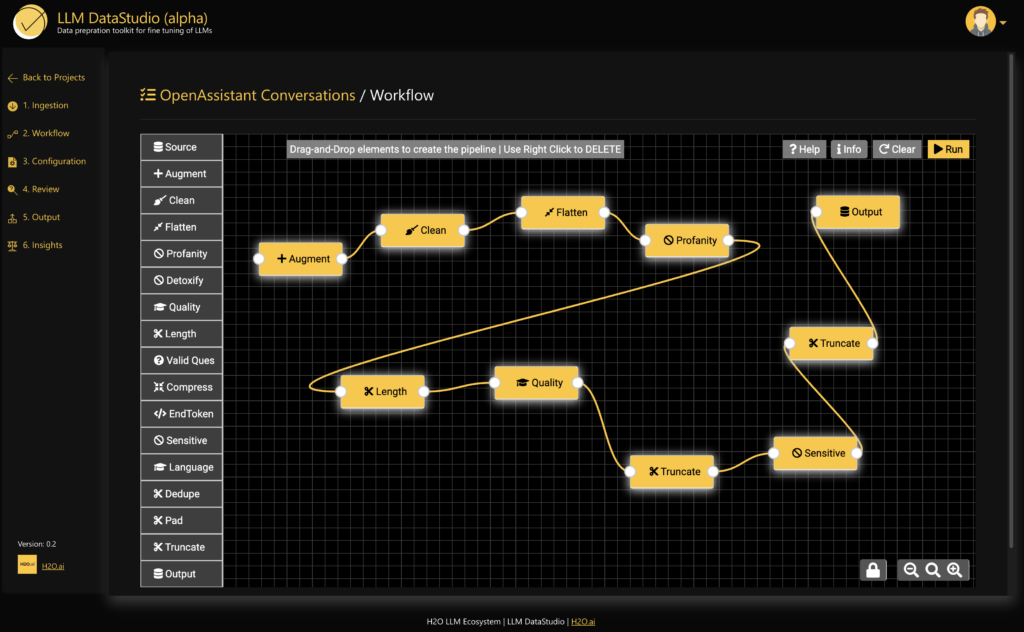
Configure each element accordingly with different user inputs such as cleaning thresholds, text grade thresholds, profanity thresholds, etc.
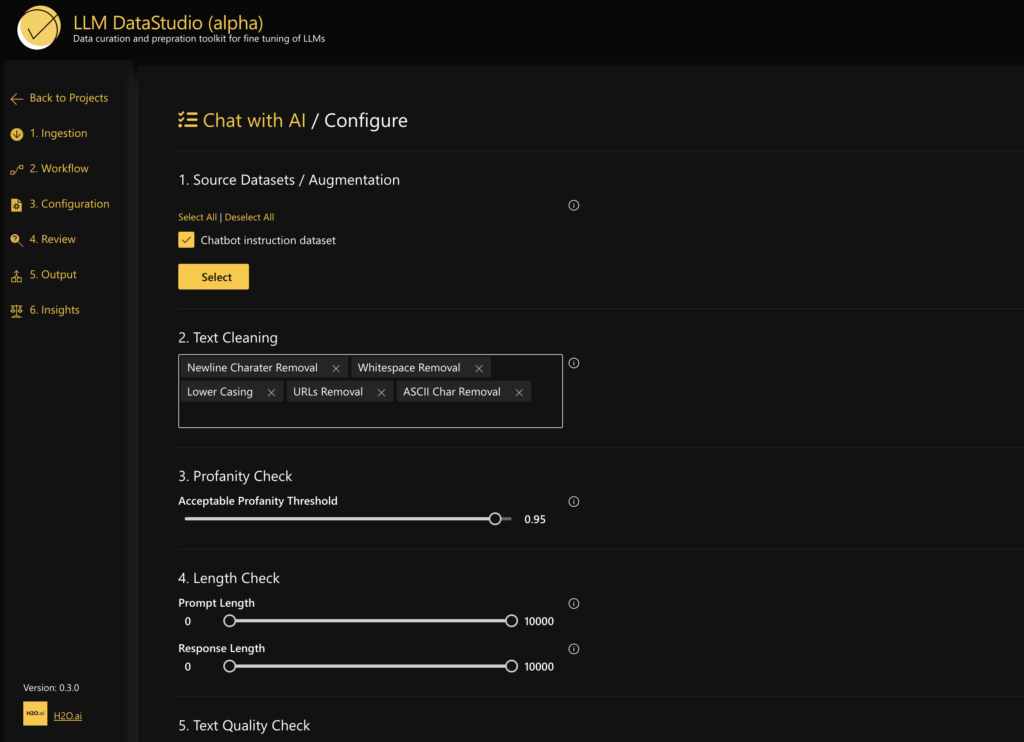
Final output, comparison, and insights in a desired format:
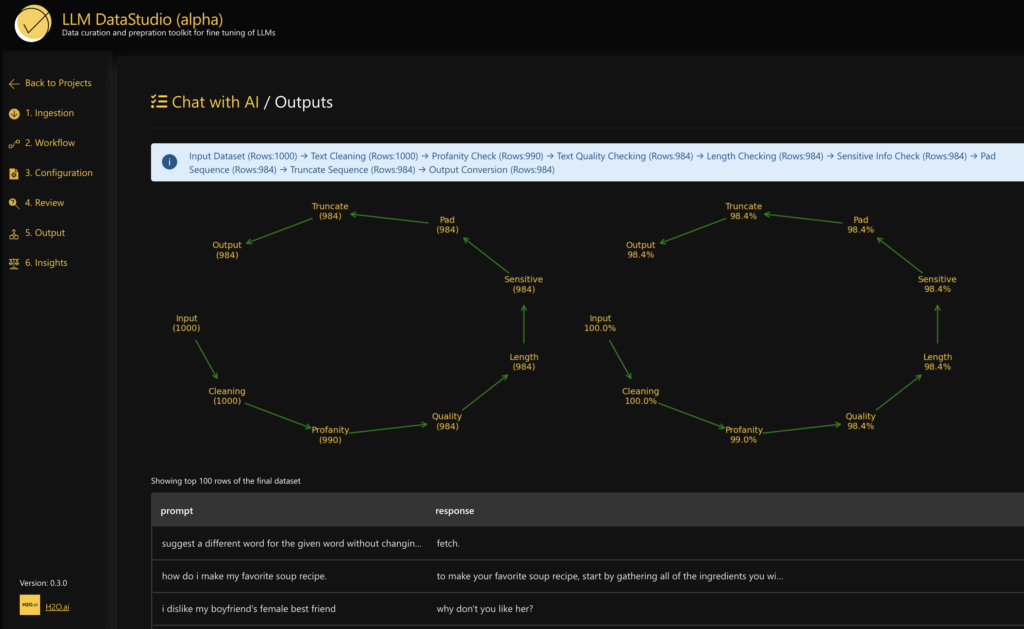
The no-code interface can be used as a web application in H2O Cloud, or it can be run as an API, used as CLI, or a Python package. LLM DataStudio also offers the API to work directly with Python. The necessary steps include:
- Import the data studio package
- Define the config for the project
- Call the prepare_dataset function
Following is an example of using llm-data-preparation for a Question Answering type project.
# Import modules
from datastudio
import prep import pandas as pd
# Initializing configuration
cfg = {
"type": "qa",
'config': {
'augmentation': [],
"text_clean": {
"cols": [],
"funcs": ["new_line","whitespace","urls","html"]
},
'length_checker': {
'max_answer_length': 10000,
'max_context_length': 10000,
'max_question_length': 10000,
'min_answer_length': 0,
'min_context_length': 0,
'min_question_length': 0
},
'padding': {'max_length': '600'},
'profanity_checker': 0.3,
'quality_checker': {'max_grade': 30, 'min_grade': 15},
'relevance_checker': 0.15,
'truncate': {'max_length': '10000', 'ratio': 0.15}
},
'datasets': [{
'cols': { 'answer': 'answer', 'context': 'context', 'question': 'question'},
'path': ['input/qna.csv']
}],
'is_hum_bot': 0,
"selected_aug_dataset": 0
}
# Executing pipeline
output_df = prep.prepare_dataset(cfg)
output_df.head()
This script is set up to load a QnA dataset, preprocess and clean the text data, check and filter the data based on length and relevance criteria, and finally, pad and truncate the sequences. The resulting processed data frame is then displayed in the notebook. The final datasets obtained from LLM DataStudio can be pushed to different tools such as H2O LLM Studio for fine-tuning and making your own LLM Models
Conclusion
To wrap up, LLM DataStudio is a fantastic tool that makes preparing data for Large Language Models a lot easier. It’s packed with features like cleaning text, checking data quality, adding more data, and arranging data into a specific format. It’s great at handling many kinds of jobs like creating question-answer pairs, summarizing text, making bots more responsive to instructions, improving bot-human chats, and training language models further. Whether you’re a pro coder or not, anyone can use LLM DataStudio. It’s got a Python API for coders and a no-code web interface for everyone else. What’s more, it’s really careful with data quality and user privacy. It checks for bad words, private information, and repeated data, so users can trust their datasets are high-quality, respectful, and ready for training their language models. In a world where data powers everything, LLM DataStudio is an easy-to-use solution that takes the headache out of preparing data. It changes data preparation from a tough task to an easy, smooth process. For any queries, reach out to our team. Also stay tuned for the next version release with Document to Q:A pair curation capability.









