







Introducing TabH2O

An advanced foundation model for tabular data — outperforming classical ML approaches, delivering accurate predictions in seconds with no training, tuning, or feature engineering required.
A Foundation Model for Tabular Data
Tabular data powers some of the most critical decisions in business — credit scoring, demand forecasting, clinical trials, fraud detection. Yet building a good model for a new dataset still requires significant effort: feature engineering, model selection, hyperparameter tuning, and weeks of iteration.
Foundation models transformed NLP and computer vision by training a single model that generalizes across tasks. TabH2O brings that same paradigm to tabular data. Pretrained on millions of synthetic datasets with diverse statistical structures, TabH2O performs in-context learning — it reads your labeled data, learns the patterns, and makes predictions, all in a single step. No feature engineering. No gradient updates. No tuning. Just data in, predictions out.
0
HYPERPARAMETERS TO TUNE
#1
VS TRADITIONAL ML (300 TASKS)
<3s
PREDICTION TIME ON 15,000 ROWS
1 line
CURL OR A FEW LINES OF PYTHON
Architecture: Three-Stage Transformer
TabH2O processes tabular datasets through three specialized transformer stages. Each stage handles a different granularity of the data — from individual features, to rows, to the entire dataset — enabling the model to learn complex patterns across any schema.
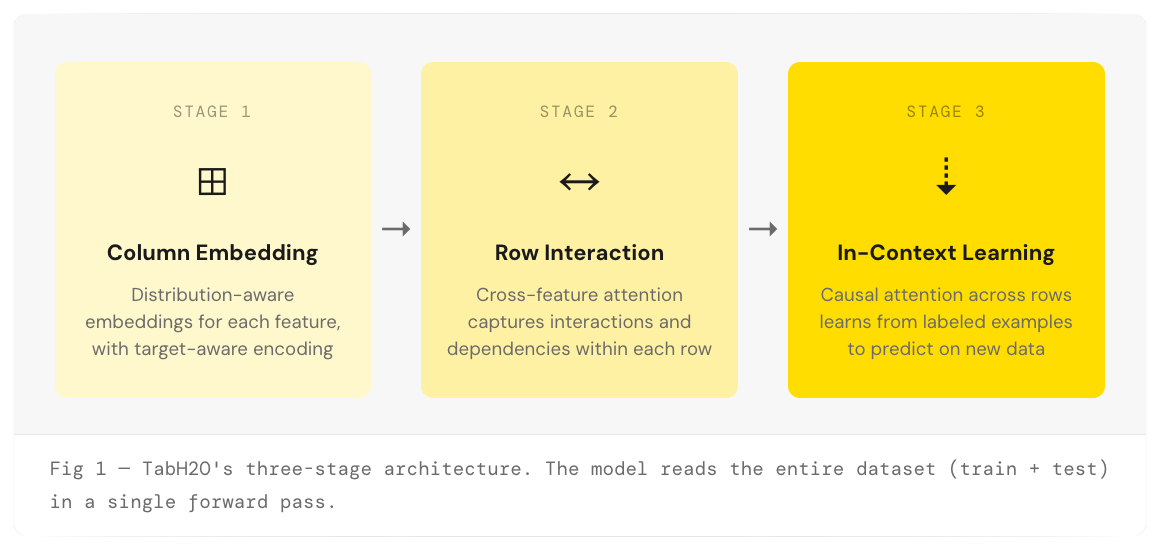
What Makes This Architecture Special
Unlike traditional ML models that train on a single dataset, TabH2O was pretrained on millions of synthetically generated tabular datasets spanning diverse causal structures — from simple linear relationships to complex nonlinear interactions, multi-dimensional dependencies, and irrelevant noise dimensions.
Multiple Tasks
TabH2O handles classification, regression, time series forecasting, clustering, anomaly detection, missing value imputation and more.
Memory-Efficient Inference
Various memory optimization techniques allow TabH2O to handle datasets with up to 500K rows on a single GPU.
Fits Any Industry
Pretrained on millions of diverse synthetic datasets, TabH2O generalizes to any unseen real-world data without need for fine-tuning.
Benchmark Results
We evaluated TabH2O v1 on TALENT, a comprehensive tabular benchmark spanning 300 classification and regression tasks curated by independent researchers. We chose TALENT over alternatives like TabArena for three reasons: scale (300 tasks vs. 51 gives far more statistical power), independence (TabArena is co-maintained by the AutoGluon team), and robustness (no single difficult dataset can swing the leaderboard). Models are ranked per task; lower average rank is better.
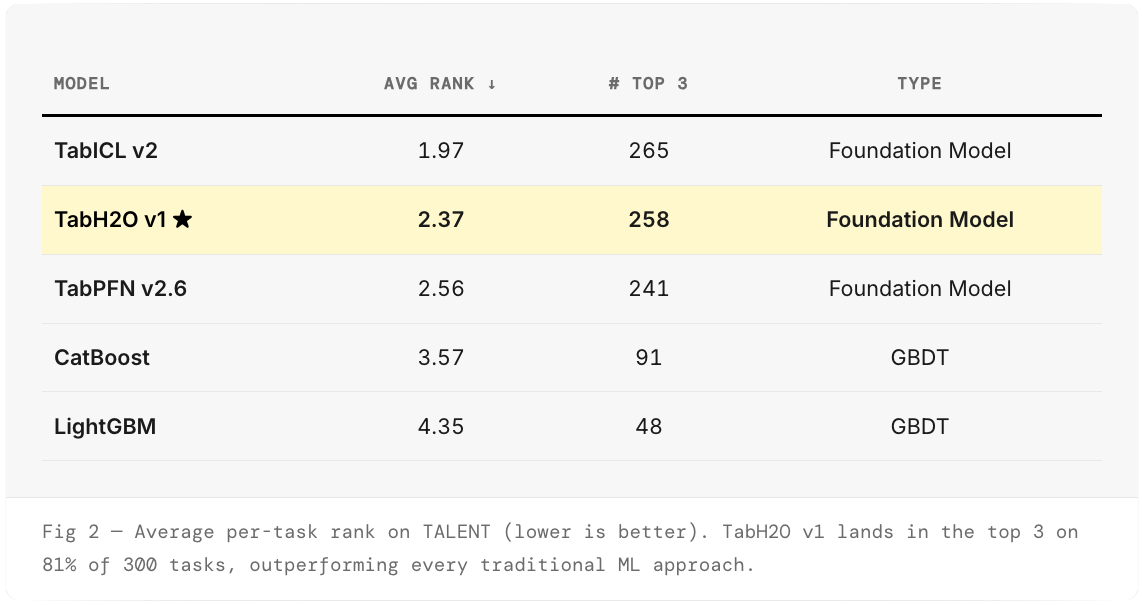
Average Rank
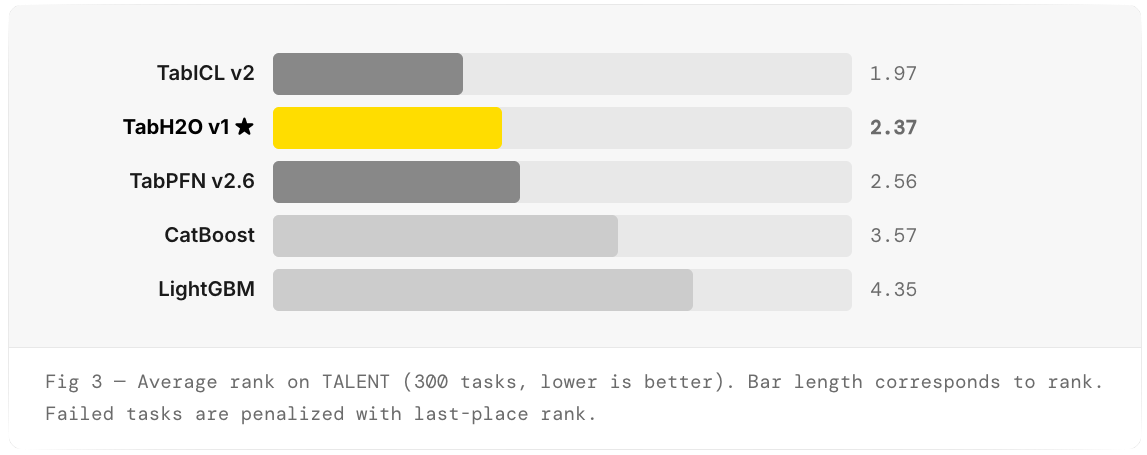
Key takeaway: TabH2O v1 outperforms every traditional ML approach — tuned CatBoost, LightGBM — across all 300 TALENT tasks, with zero hyperparameter tuning. Where GBDTs need per-dataset tuning and AutoML systems require significant compute budgets, TabH2O delivers superior predictions out of the box.
Predictions in Seconds
Traditional ML has a hidden tax: before you get a single prediction, you pay for training, cross-validation, and hyperparameter search. On a typical TALENT task, tuned CatBoost takes nearly 10 minutes end-to-end. TabH2O has no training step. Send your data, get predictions back — the entire operation is a single forward pass through a pretrained transformer.
For the vast majority of real-world datasets — think customer churn, fraud signals, sales forecasting — you'll have results in under three seconds. Larger datasets take longer, but even 50,000-row jobs finish in about 20 seconds.

How It Works: From Data to Predictions
TabH2O is designed to be as simple as a single API call. Under the hood, the model performs sophisticated in-context learning — but the complexity is completely abstracted away. Send your labeled and unlabeled data, get predictions back.

Auto-preprocessing handles the messy parts of real-world data: categorical encoding, missing value imputation, outlier detection, and feature normalization. In-context learning (ICL) is what makes the rest possible. Rather than fitting model weights to your dataset, TabH2O reads your labeled training rows directly as input — they become the context for the transformer. The model attends to those examples and predicts on held-out test rows in a single forward pass. No gradient updates, no training loop, no overfitting risk from small samples.

The TabH2O API
TabH2O is available as a hosted API with a generous free tier. Get started in minutes — no GPU, no dependencies, no setup. Just a single HTTP request.
A Single curl Request Or a Few Lines of Python
curl -X POST https://tabh2o.h2oai.com/api/v1/predict \
-H "Authorization: Bearer YOUR_API_KEY" \
-F file=@data.csv \
-F target_column=purchased \
-F task=classificationimport requests
API_KEY = "YOUR_API_KEY"
# Upload a CSV where rows with empty target get predicted
response = requests.post(
"https://tabh2o.h2oai.com/api/v1/predict",
headers={"Authorization": f"Bearer {API_KEY}"},
files={"file": ("data.csv", open("data.csv", "rb"))},
data={
"target_column": "purchased",
"task": "classification",
},
)
print(response.json())Free API Access
TabH2O is free to use. Sign up, get an API key, and start making predictions. Need higher limits for production? Contact us.

When to Use TabH2O
TABH2O V1 CAPABILITIES
- Best-in-class accuracy — outperforms tuned GBDTs and AutoML across 300 benchmark tasks
- Classification and regression — any number of classes for classification, predictions and confidence intervals for regression
- Time series forecasting — send historical data with a time column, get future predictions with confidence intervals
- Heterogeneous data — mixed numeric and categorical features handled automatically
- Zero configuration — no feature engineering, no hyperparameter tuning, no model selection required
COMING NEXT
- >500K training rows — extended context support for even larger datasets
- Anomaly detection — identify outliers and unusual rows without labeled examples
- Clustering — unsupervised grouping of similar rows, no target column needed
- Missing value imputation — fill gaps in your dataset using learned patterns, works on both numeric and categorical columns
- Interpretability tools — feature importance and prediction explanations
- Fine-tuning — adapt the foundation model to your domain for even better accuracy
Getting Started
1. Sign up at tabh2o.h2oai.com using your LinkedIn or Google account.
2. Get your API key from the dashboard — it's instant and free.
3. Make your first prediction — a single curl request is all it takes:
curl -X POST https://tabh2o.h2oai.com/api/v1/predict \
-H "Authorization: Bearer YOUR_API_KEY" \
-F file=@data.csv \
-F target_column=purchased \
-F task=classificationThe response includes predictions, class probabilities, and metadata. Only task-relevant fields are returned:
{
"predictions": ["Yes", "No"],
"probabilities": [[0.82, 0.18], [0.35, 0.65]],
"metadata": { "task": "classification",
"train_rows": 4,
"test_rows": 2,
"time_ms": 1234 }
}Regression and time series return confidence intervals instead of probabilities.
Ready to try it? Head to tabh2o.h2oai.com to get your free API key and start making predictions in minutes. For enterprise deployments, dedicated GPU instances, or on-premise installations, contact our sales team.









