







Automatic Feature Engineering for Text Analytics - The Latest Addition to Our Kaggle Grandmasters' Recipes
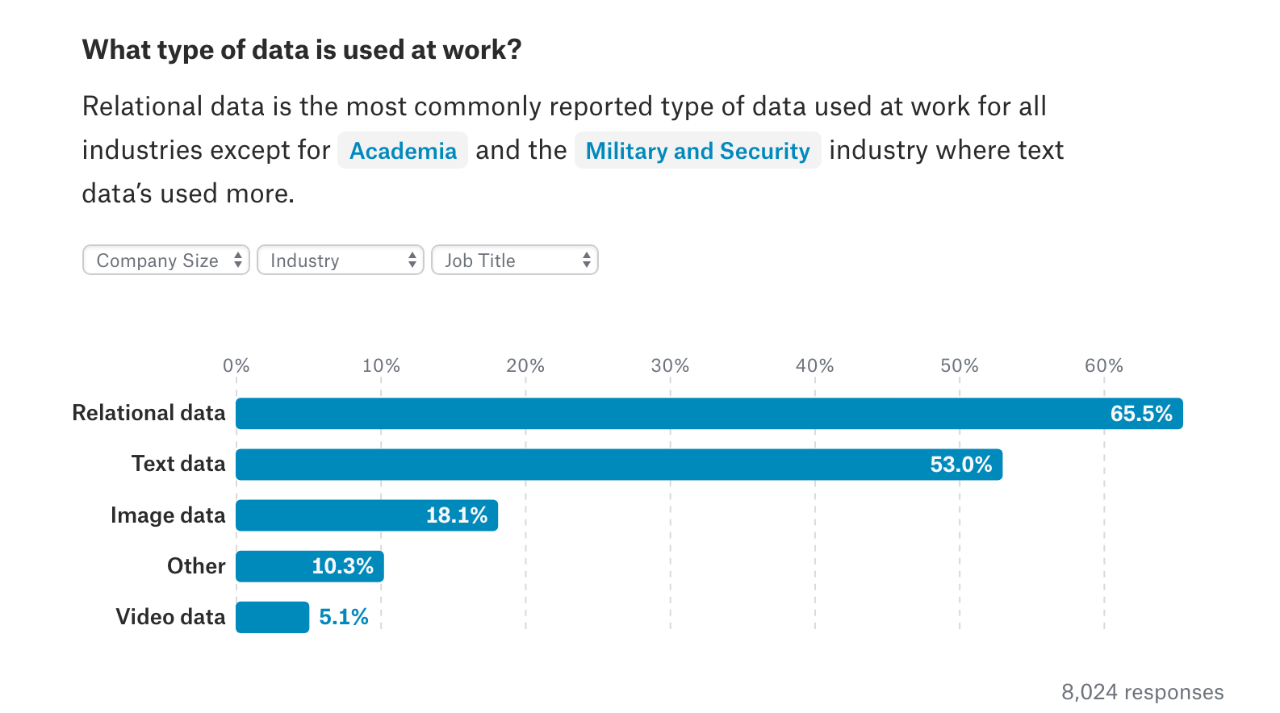
According to Kaggle’s ‘The State of Machine Learning and Data Science ’ survey , text data is the second most used data type at work for data scientists. There are a lot of interesting text analytics applications like sentiment prediction, product categorization, document classification and so on.
In the latest version (1.3) of our Driverless AI platform, we have included Natural Language Processing (NLP) recipes for text classification and regression problems. Our platform has the ability to support both standalone text and text with other numerical values as predictive features. In particular, we have implemented the following recipes and models:
– **Text-specific feature engineering recipes**:
– TFIDF, Frequency of n-grams
– Truncated SVD
– Word embeddings
– **Text-specific models to extract features from text**:
– Convolutional neural network models on word embeddings
– Linear models on TFIDF vectors
A Typical Example: Sentiment Analysis
Let us illustrate the usage with a classical example of sentiment analysis on tweets using the US Airline Sentiment dataset from Figure Eight’s Data for Everyone library . We can split the dataset into training and test with this simple script . We will just use the tweets in the ‘text’ column and the sentiment (positive, negative or neutural) in the ‘airline_sentiment’ column for this demo. Here are some samples from the dataset:

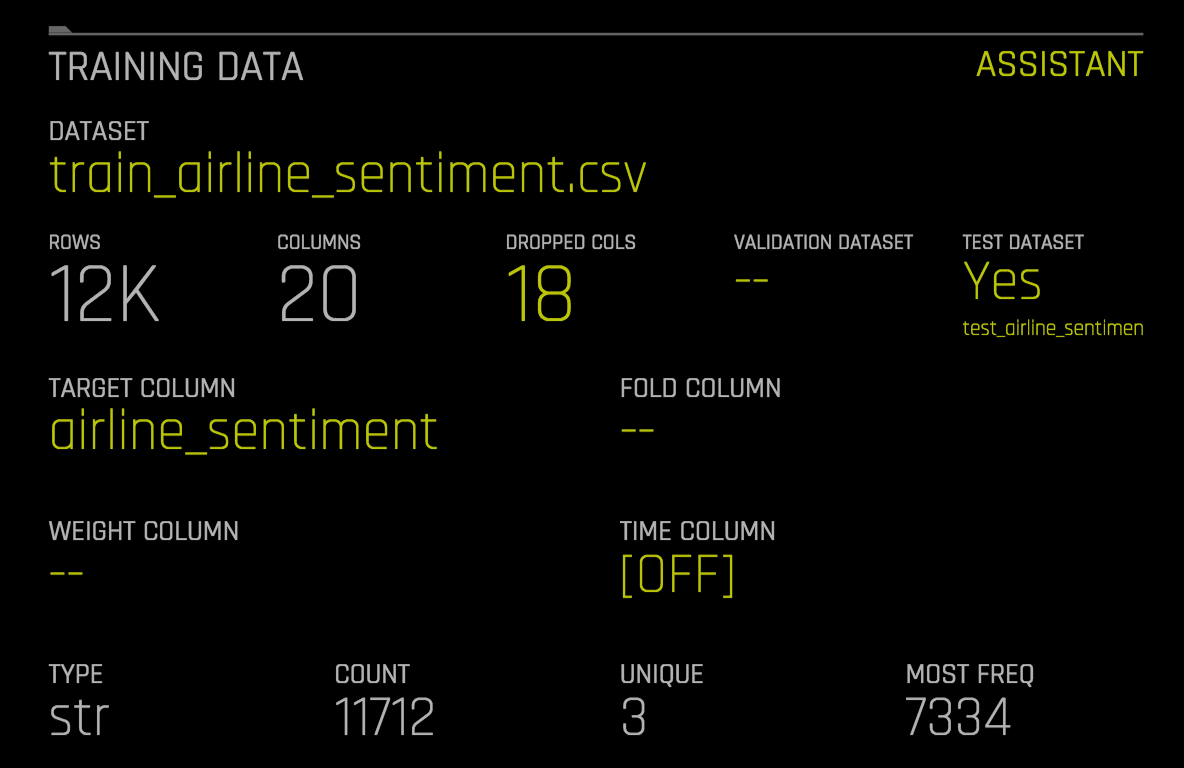
Once we have our dataset ready in the tabular format, we are all set to use the Driverless AI. Similar to other problems in the Driverless AI setup, we need to choose the dataset and then specify the target column (‘airline_sentiment’).
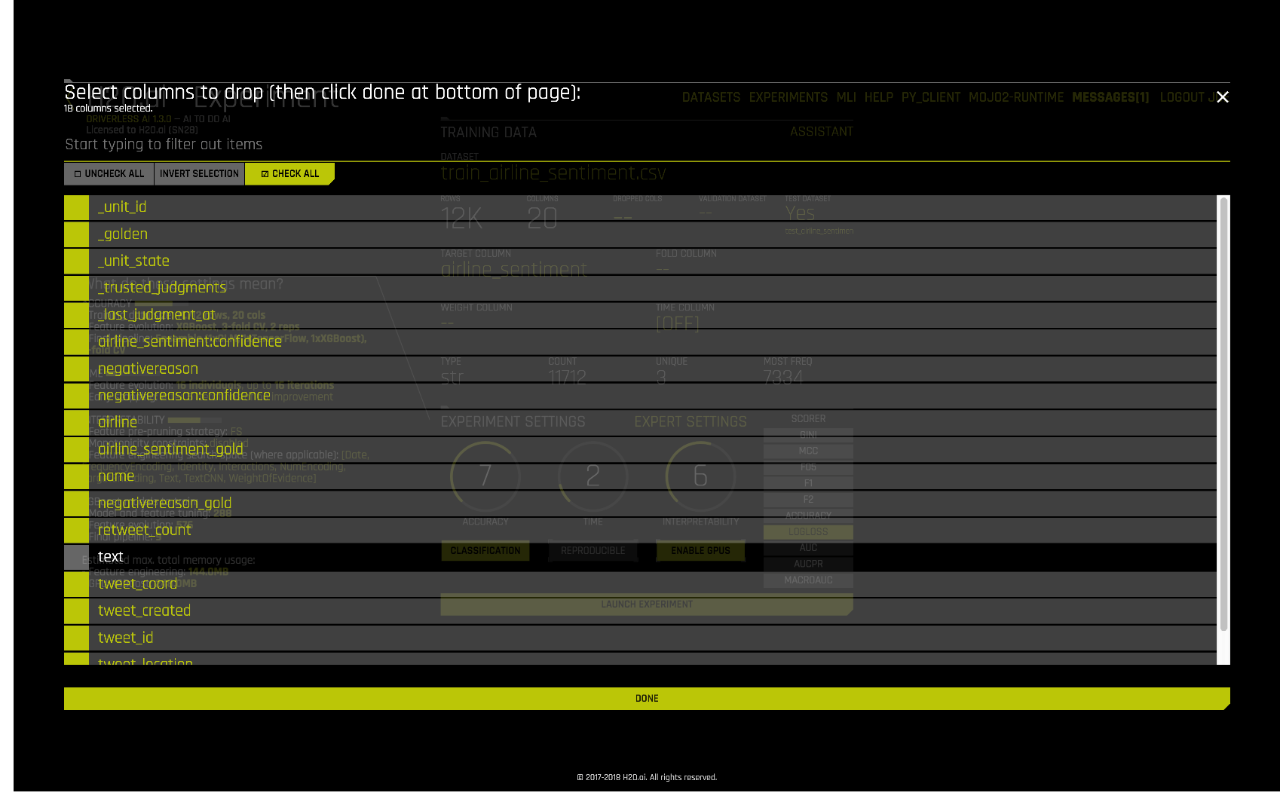
Since there are other columns in the dataset, we need to click on ‘Dropped Cols’ and then exclude everything but ‘text’ as shown below
Next, we will need to make sure TensorFlow is enabled for the experiment. We can go to ‘Expert Settings’ and switch on ‘TensorFlow Models’.

At this point, we are ready to launch an experiment. Text features will be automatically generated and evaluated during the feature engineering process. Note that some features such as TextCNN rely on TensorFlow models. We recommend using GPU(s) to leverage the power of TensorFlow and accelerate the feature engineering process.
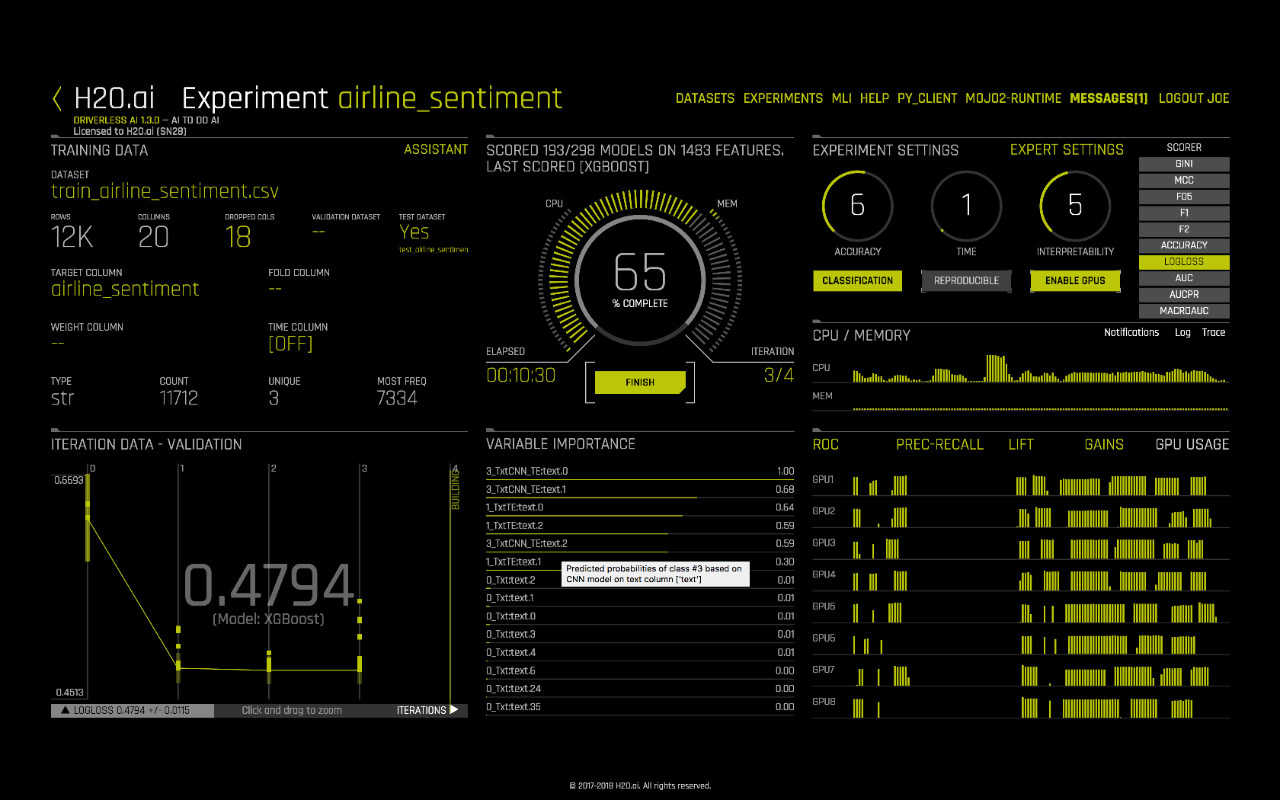
Once the experiment is done, users can make new predictions and download the scoring pipeline just like any other Driverless AI experiments.
Bonus fact #1 : The masterminds behind our NLP recipes are Sudalai Rajkumar (aka SRK) and Dmitry Larko .
Bonus fact #2 : Don’t want to use the Driverless AI GUI? You can run the same demo using our Python API. See this example notebook .
Seeing is believing. Try Driverless AI yourself today. Sign up here for a free 21-day trial license.
Until next time,
SRK and Joe








