







Using Sentiment Analysis to Measure Election Surprise
Sentiment Analysis is a powerful Natural Language Processing technique that can be used to compute and quantify the emotions associated with a body of text. One of the reasons that Sentiment Analysis is so powerful is because its results are easy to interpret and can give you a big-picture metric for your dataset.
One recent event that surprised many people was the November 8th US Presidential election. Hillary Clinton, who ended up losing the race, had been given chances ranging from a 71.4% (FiveThirtyEight ), to a 85% (New York Times ), to a >99% chance of victory (Princeton Election Consortium ).

/u/Stuck_In_the_Matrix

We examined five political subreddits to gauge their reactions. Our first target was /r/hillaryclinton , Clinton’s primary support base. The number of comments reached a high starting at around 9pm EST, but the sentiment gradually fell as news came in that Donald Trump was winning more states than expected.
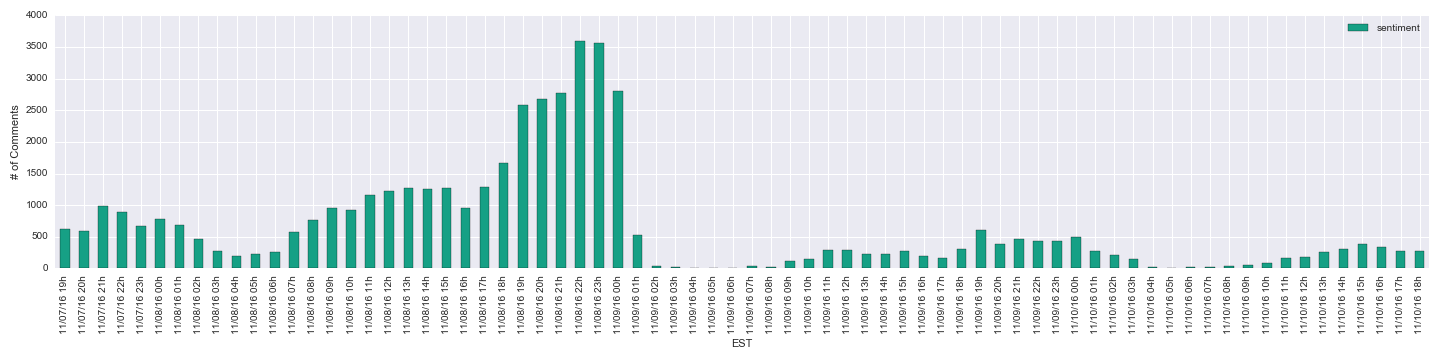

/r/SandersforPresident/r/Political_Revolution


On /r/The_Donald (Donald Trump’s base), the results were the opposite.
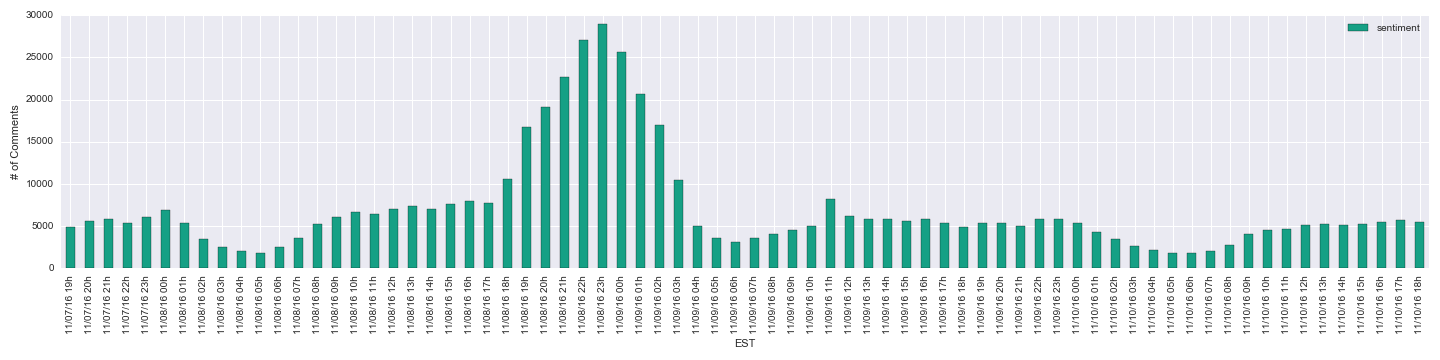

There are also a few subreddits that are less candidate- or ideology-specific: /r/politics and /r/PoliticalDiscussion . /r/PoliticalDiscussion didn’t seem to show any shift, but /r/politics did seem to become more muted, at least compared to the previous night.
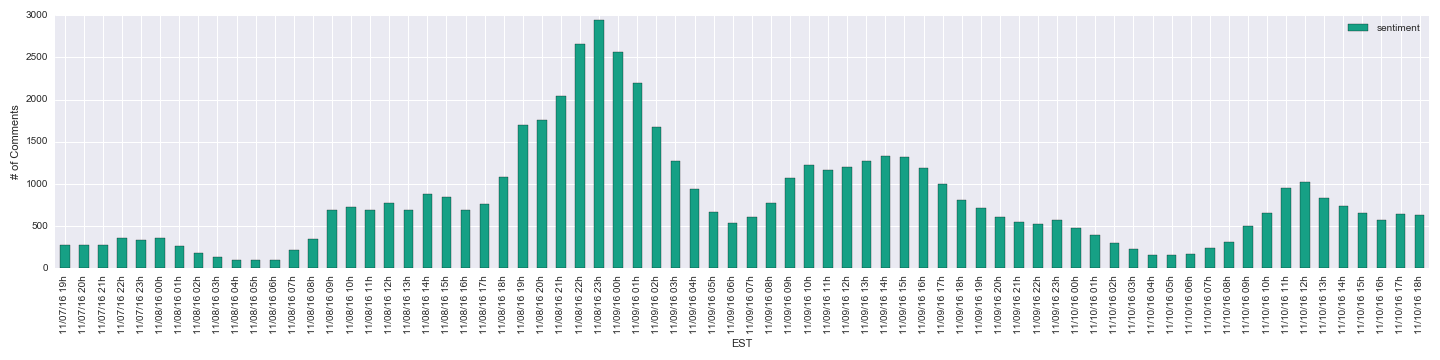


/r/politics: Mean Sentiment Score per Hour
- Reddit political subreddits experienced a sizable increase in activity during the election results
- Subreddits differed in their reactions to the news along idealogical lines, with pro-Trump subreddits having higher positive sentiment than pro-Clinton subreddits
What could be the next steps for this type of analysis?
- Can we use these patterns to classify the readership of the comments sections of newspapers as left- or right-leaning?
- Can we apply these time-series sentiment analyses to other events, such as sporting events (which also includes two ‘teams’)?
- Can we use sentiment analysis to evaluate the long-term health of communities, such as subreddits dedicated to eventually-losing candidates, like Bernie Sanders?







