Grandmaster Series: The inspiring journey of the ‘Beluga’ of Kaggle World 🐋
In conversation with Gábor Fodor: A Data Scientist at H2O.ai and a Kaggle Competitions’ Grandmaster.
In this series of interviews, I present the stories of established Data Scientists and Kaggle Grandmasters at H2O.ai , who share their journey, inspirations, and accomplishments. These interviews are intended to motivate and encourage others who want to understand what it takes to be a Kaggle Grandmaster.
In this interview, I shall be sharing my interaction with Gábor Fodor , better known as Beluga in Kaggle world. He is a Kaggle Competitions Grandmaster and a Data Scientist at H2O.ai . Gabor, who hails from Hungary, holds a master’s degree in Mathematics as well as Computer Engineering and has around ten years of experience in the Data Science domain. He joined Kaggle nine years ago and since then has made quite a mark there. His best global rank is 4th for competitions and 7th for notebooks.
Here is also a link to Gábor’s recent interview at CTDS.show where he discusses his 10th place solo gold in Cornell Birdcall competition on Kaggle
Here is an excerpt from my conversation with Gábor:
Q: You have a background in Mathematics. How did the transition from academia to industry happen?
Gábor: Doing a Master’s in mathematics with a stochastics major certainly provided a strong background (discrete math, probability theory, statistics, stochastic processes, etc.), although the courses mainly focused on theory. Fortunately, I was free to take some additional courses, and as a result, I got to learn about programming & data mining as well.
During my final year, I had a chance to intern as a Data Mining trainee in the telco industry. It was quite interesting to retrain and improve the old drifted churn models. However, the most valuable part was that I had direct access to their data warehouse, and I could learn and practice SQL with real-world data and business problems. After the internship, I stayed at the company and became a full-time data analyst. Since then, I have had a chance to work in different industries working on varied types of business problems.
Q: How did you get interested in Machine Learning?

Gábor : I immensely enjoyed my data mining courses. My first data mining competition was in 2009, and it was quite fun. Then I found Kaggle and got addicted forever. At that time, I already had a full-time job and just started a new master’s in computer science, so finding time for new Kaggle challenges was not always easy. But the learning opportunity was enormous, and I could not resist trying to solve those unique data-driven problems.
Q: How hard is it to become a Kaggle Grandmaster? What initially attracted you to Kaggle, and When did the first win come your way?
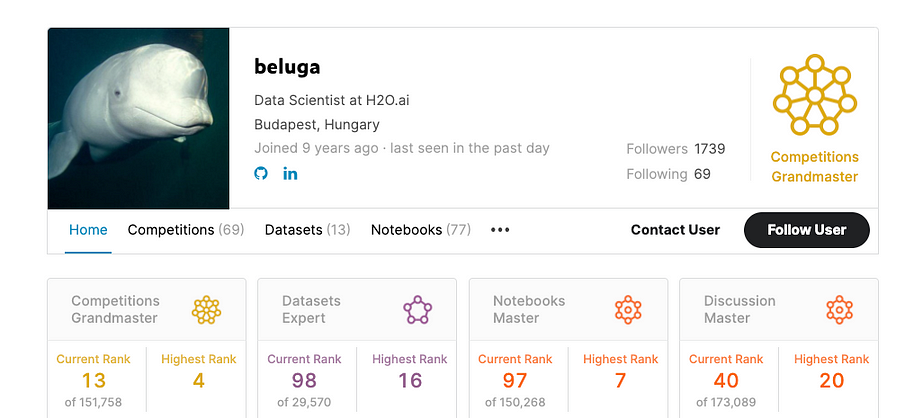
Gábor : Reaching a Grandmaster’s status in competitions is undoubtedly demanding. One needs five gold medals in different competitions, and at least one has to be a solo gold. It requires a lot of effort and hard work to earn gold in every competition, for instance, him .
My first competition win came in 2013. It was a small research competition with 81 teams. The task was to recognize bird species in audio recordings. We only had a few hundred audio files for training at that time, and we did not have all the comfortable deep learning tools. I was able to win the competition with template matching on the spectrograms and using random forests only.
The competitions became a bit more difficult since the good old days as the Kaggle community grew. Nowadays, it is hard to find competitions with less than a thousand teams.
Q: As a Data Scientist at H2O.ai, what are your roles, and in which specific areas do you work?

Gábor : I just joined H2O.ai in August, and I like the flexibility to work on different projects here. Besides helping customers using H2O Driverless AI during POCs, I also create H2O Wave apps and test new Driverless AI features.
Q: What are some of the best things you have learned via Kaggle that you apply in your professional work at H2O.ai?
Gábor : I hear way too often that in Kaggle competitions, participants fight over the 4th decimals on the leaderboard, and the differences are not significant. Well, there are much bigger victories (e.g., in the recently finished Lyft Motion Prediction competition where Philipp and his team won by 8% improvement over the second team). Even if the race is much closer, you have to turn all the rocks and squeeze every possible gain from your features and models. In my experience, that also teaches you how to get a robust baseline model fast.
The other criticism that I hear is that the competitions reward overfitting and data leaks. While I agree that data leaks could be a significant issue, and I did have to exploit them to win competitions, overfitting is not rewarded at Kaggle. Quite the opposite! During the competition, you don’t receive feedback about the final test set. I saw (and have experienced) quite brutal shake-ups where only the best validation strategies and most stable models survived. Data leaks are quite common in the real world too. When you see a — too good to be true- AUC result, you should start to think immediately about the cause. Seeing all the possible data leaks in previous Kaggle challenges helps to debug the machine learning pipeline quicker.
Q: If you were to team up with grandmasters at H2O.ai, who would they be and why?
Gábor : Good question  . I recently created the membership network of the Kaggle team at H2O.ai. While we are mostly in a largely connected ecosystem, I did not team up directly with anyone before. I can’t pick a single person as we have so many talented kagglers but probably will team up with some of them in 2021.
. I recently created the membership network of the Kaggle team at H2O.ai. While we are mostly in a largely connected ecosystem, I did not team up directly with anyone before. I can’t pick a single person as we have so many talented kagglers but probably will team up with some of them in 2021.
Q: The Data Science domain is rapidly evolving. How do you manage to keep up with all the latest developments?

Gábor : I think it is impossible to keep up with everything. Besides the fun, I like Kaggle competitions because they show what tools work the best for specific problems. You can learn a lot just by reading the competition winning solutions. But trying to apply those tips and tricks in the next competition will teach you a lot more.
There is quite a few stuff to catch up for me regarding Natural Language Processing or Reinforcement Learning. Fortunately, the team at H2O.ai has experts in every field.
On the other hand, it also means that the tools are getting better. In the recent Cornell Birdcall Competition, I could train models with a few hundred code lines with PyTorch . Or look at Driverless AI; with a few clicks, you could solve all sorts of supervised machine learning problems.
Q: A word of advice for the Data Science aspirants who have just started or wish to start their Data Science journey?
Gábor : Don’t be afraid to start and prepare for the long run. The community is enormous and willing to share. If you already learned the basics and want to get your hands dirty, I can only recommend participating in Kaggle competitions.
There are personally a lot of takeaways from this interaction. Firstly, Data Science is an area where one needs to be self-motivated and eager to learn at every stage. Secondly, there is always so much to learn from every machine learning competition, even if you perform well or not. The important thing is to identify your weak points and work on them while leveraging your strengths. In the end, the community around you is always ready to help, and the flourishing Kaggle community is a testimony to that fact.