





What are we buying today?
Note : this is a guest blog post by Shrinidhi Narasimhan .
It’s 2021 and recommendation engines are everywhere. Be it online shopping, food, music, and even online dating, the race to provide personalized recommendations to the user has many contenders. The technology of giving users what they need based on their buying strategies or digital interactions is indeed powerful and is slowly becoming omnipresent. Naturally, I have been curious about exploring this area for quite some time. Having had the opportunity to be a grant recipient of the Kaggle BIPOC Program 2021 , I decided to take it up as a deliverable for the program.
The purpose of the project is to provide personalized product recommendations to each user based on their purchase history. After doing a fair bit of research, I decided to implement Collaborative Filtering for the same. Collaborative filtering employs the past interactions between users and items to make intelligent predictions about what product the user might like. I decided to use Matrix Factorization Algorithm for it owing to its popularity.
What is Matrix Factorization?
Simply put, Matrix Factorization is a technique used to decompose or ‘factorize’ a single matrix into two equivalent matrices whose product will give you the original matrix. In order to model our recommendation problem as a matrix factorization one, we need the interaction between the users and items into a single matrix. This matrix contains all the users as rows and all the products as columns, with the product ratings as the matrix values.
In a nutshell, the algorithm predicts the values for the entries labelled ‘?’ based on the products already rated by the user. The model has been built using H2O.ai’s GPU package , which is optimized for GPU and thus provides faster processing than sklearn.NMF library.
Preparing the Dataset
Using the Amazon Reviews Dataset , the reviews and metadata of different product categories are combined and prepared for model building. While splitting the input dataset into the training set and test set, we have to keep in mind that the unique list of users and products in the test set is a subset of those in the training data, since the matrix factorization algorithm will not offer any predictions for new users (i.e., those users whose purchase history isn’t available) or new products (i.e., those products not purchased or rated by any user in the training data).
Model Building
Using RMSE as an evaluation matrix, the model has been tuned for different combinations of the hyperparameters (No. of components, lambda, max_iters) to select the combination that provides the least error. Then the model was fit on the complete set of observations (both train and test) using the aforementioned best combination of hyperparameters.
The dataset being a long-tailed one, the model gave nearly satisfactory results with some margin of error. Adding more training data, such that each user had more historical data (i.e., more purchases across different categories) will help the algorithm learn better and provide more relevant recommendations.
Building the Web App
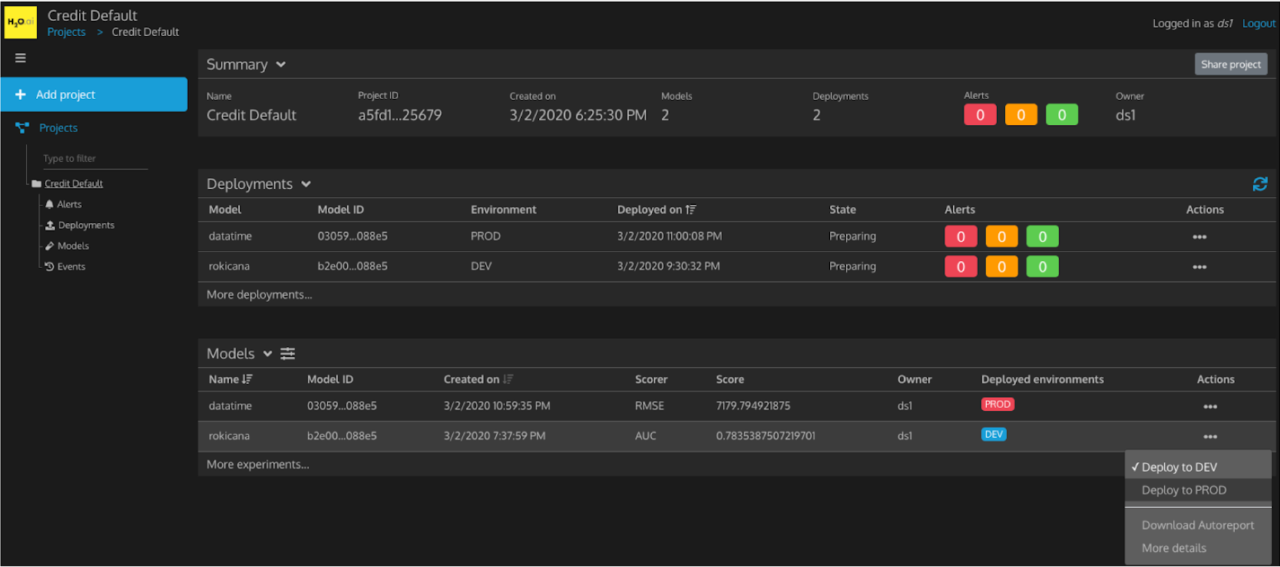
The final product of the project is a web application built using Wave by H2O.ai . It’s a simple dashboard that displays the user’s purchase history on the left and the top 10 product recommendations specific to each user on the right. User selection can be done using a simple dropdown populated with around 50 users. Here’s a short demo of the app:
One of the perks of using Wave is that it helps me build real-time web applications using simple Python code. Since I don’t have much experience with front-end technologies, I was a bit apprehensive about learning a new front-end technology in much less time. So, with their crisp and informative documentation, Wave makes the process very straightforward. It also helped me gain insights into deploying an ML model into production, the process, and the challenges therein.
What’s Next?
With a working pipeline in place, there are a number of implementations that can be explored. Apart from incorporating more data while training, it will be interesting to explore models that can truly capture both behaviour as well as extract useful information like similarity. Some of the other improvements could be:
- Implementing Matrix Factorization algorithm using SVD, Gradient Descent
- Exploring other evaluation metrics like Mean Average Prediction
- Trying other algorithms like content-based filtering, boosting or a hybrid model.
- Understanding the influence of additional data like product reviews along with product recommendations on user’s buying behaviour.
- Exploring the relevancy of the model’s recommendations to the user by incorporating a feedback loop.
The goal is to build highly intelligent systems which are capable of evolving with time and provide a smooth user experience.
About the Author
Shrinidhi is a data science enthusiast with a strong background in Computer Science. She enjoys coding and has worked on trading algorithms and risk management applications in the fintech domain. Apart from her newfound zeal for Kaggling, she loves reading and music. She is an amateur guitarist. Her interests include Deep Learning , NLP, and Robotics. You can reach out to her on LinkedIn and Github .







