


The H2O.ai Wildfire Challenge Winners Blog Series - Team PSR


Note : this is a community blog post by Team PSR – one of the H2O.ai Wildfire Challenge winners.
This blog represents an experience we gained by participating in the H2O wildfire challenge. We need to mention that competing in this challenge is like a journey in a knowledge pool. For a person who is willing to get the knowledge of building AI solutions, this covered the whole end-to-end process. The rules applied throughout this competition had always pushed us to be more creative. From the stage of collecting data, we got the freedom to think about the sources, models, and technologies to use in our solution.
The Team (PSR)
The Team PSR started from three young individuals who were working in the same workplace at the Dialog- University of Moratuwa Mobile communications research laboratory , Sri Lanka.
- Shamil is a Software Engineer who recently started working at H2O.ai and a graduate in Electronics and Telecommunication Engineering. He has a passion for developing AI solutions and some of his solutions can be found in his LinkedIn profile.
- Pasan is a Research Engineer working at Dialog – UoM Research lab and a graduate in Mechatronics and Robotics Engineering. He is passionate about creating full-stack solutions from hardware, and firmware to frontend.
- Ranush is also a Research Engineer working at Dialog – UoM Research lab and a graduate in Electrical and Electronic Engineering. He has a strong bond with single board computers (SBCs) and Robotics throughout the years.
Motivation
The main task of the competition was to provide a solution for numerous organizations that are working toward preventing or reducing the wildfire (bushfire) occurrence. For our solution, we have developed a proof of concept (POC) AI application to predict the severity of wildfire on a given date and location. The application provides prediction using relevant geo-location’s weather data on the required date. I would like to share our solution along with our experience in three areas: data pre-processing, model training, and predictions.
Data Pre-processing
Since we got the chance to collect data on our own, we went through multiple existing datasets. In the end, what we thought was to create one dataset by combining data from two sources. One set of data we collected from Kaggle which contains 1.88 million US Wildfires. In order to collect weather data relevant to those geo-locations, we accessed NASA Langley Research Center online tool.
The dataset collected from Kaggle contains multiple columns that are not related to our concept. Therefore, at the very beginning, we filtered out unwanted columns except for columns like severity, geo locations, discovery date, etc. Thereafter the basic preprocessing steps were done to clear missing data and to create a meaningful dataset.
The next task was to add weather data columns to our dataset. To automate the process of collecting weather data for relevant dates and geo-locations, we used a data scraping method with the help of Selenium web-driver.
Data balancing was our next challenge. Since the wildfire dataset only contains data with some severity values, there was a need to expand our dataset with zero severity values. This allows the model to learn about occurrences where wildfires haven’t been recorded. We made an assumption that when a wildfire incident has been recorded, it will be followed by zero severity (i.e. no incident) at the same location for three months.
Wildfire Model Building & Training
The dataset was added to the H2O Driverless AI to determine the best suitable model and parameters. We set up H2O Driverless AI to run machine learning experiments. The goal is to predict the FIRE_SIZE (“the severity of wildfire”) based on different features from our wildfire dataset. H2O Driverless AI automatically took care of complex features engineering and model tuning. The following results have been obtained.
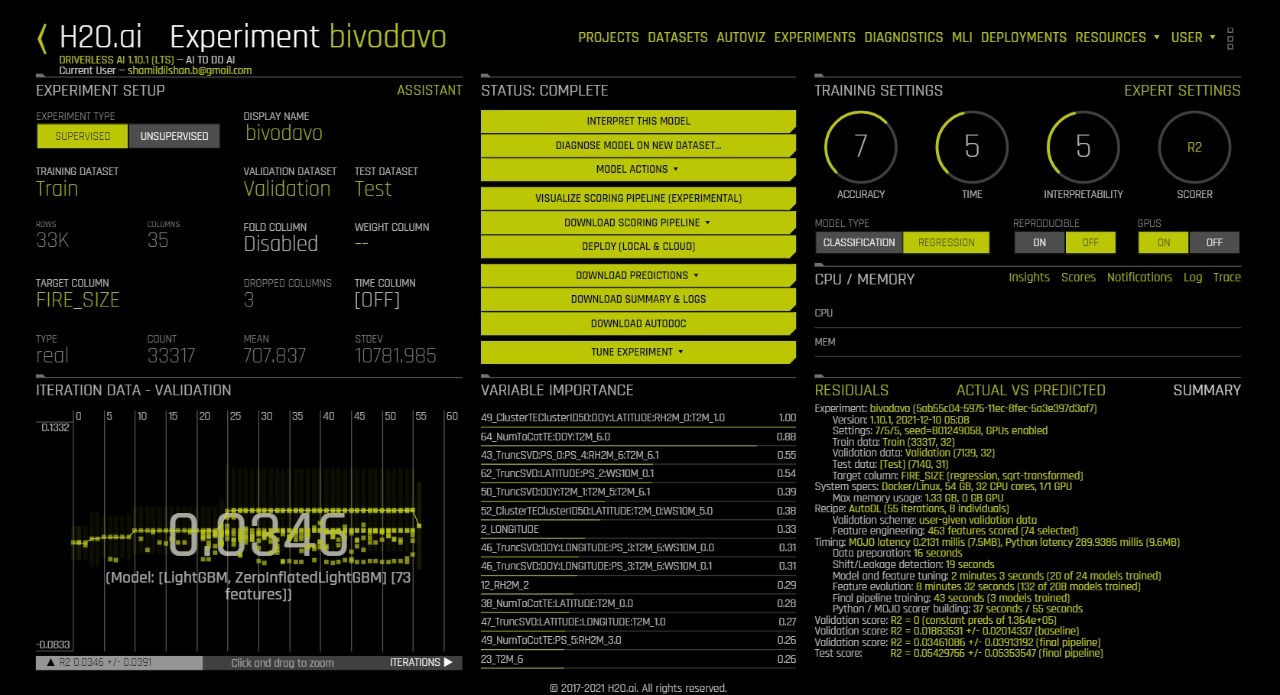
“Autodoc” was generated at the end of the experiment to identify the performance results for each model. The document results were used to determine the best model and its hyper-parameters. The best model that was considered for the model building was “LightGBM”.
The model used in the application is LightGBM which is a fast-processing algorithm. The selected model is a gradient boosting framework that makes use of tree-based learning algorithms. This algorithm grows vertically which means leaf-wise. It chooses the leaf with large loss or grows, to lower down more in the next step. One of the perspectives of choosing LightGBM as our final model is its lightness. It takes less memory to run, can deal with a large amount of data, and give good accuracy of results.
Application
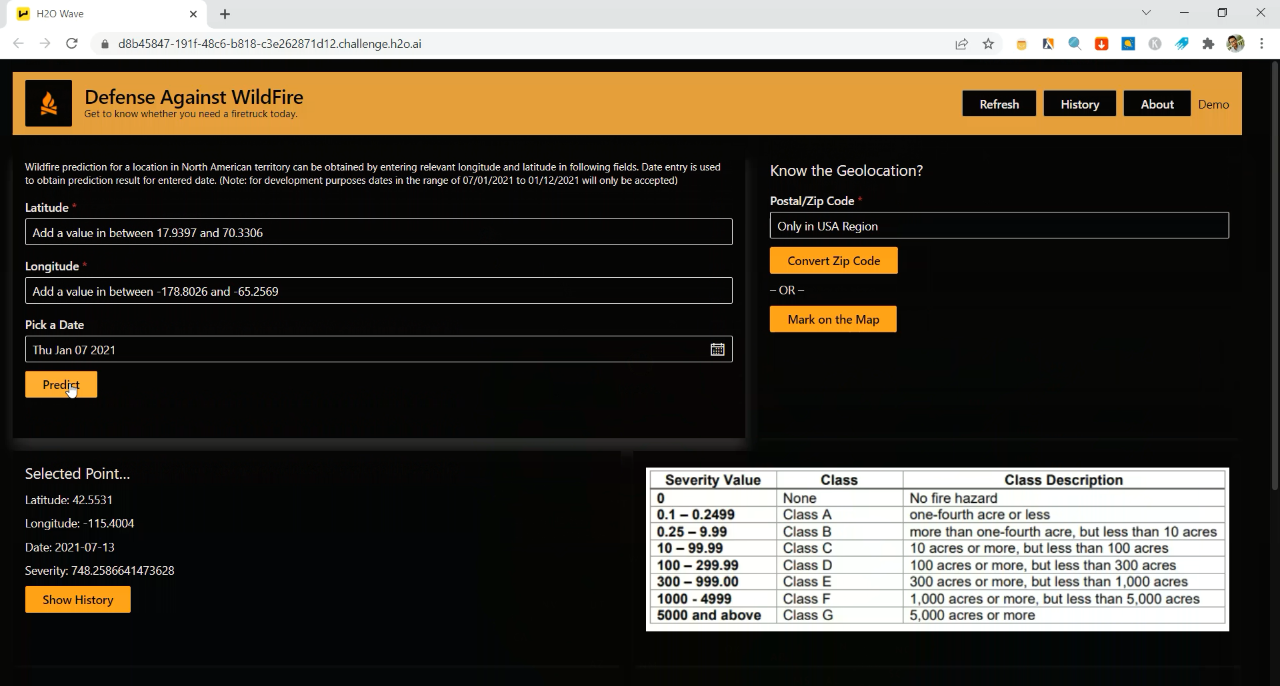
In order to predict wildfire at a specific location, the application requires latitude, longitude or the Zip code (in USA) from the user.
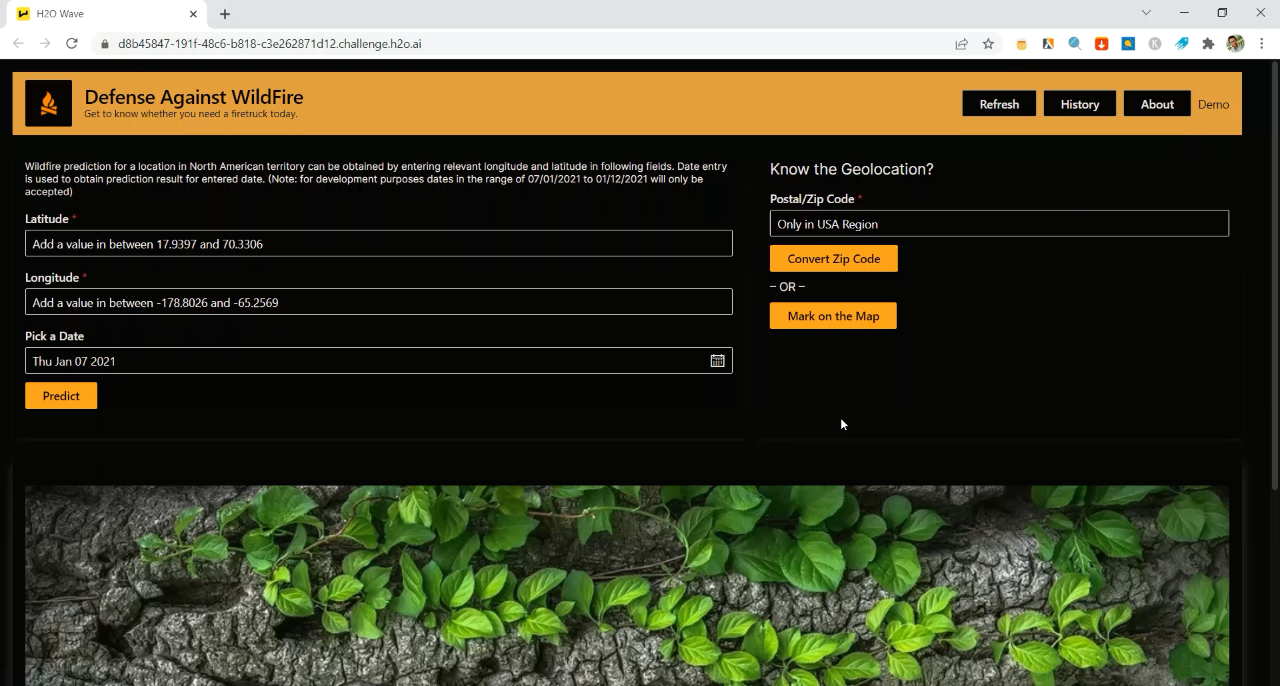
Features of the Application
The AI application was built using H2O Wave 0.20.0. Here are some of the features that are useful for wildfire prediction:
- Zip/ Postal code conversion to the geo-coordinates
- Click on the map and read the geo-coordinates of the point
- Storing prediction history
- Exception handling

Prediction from the Application
Demonstration video: Link
As the user provides the necessary values, the AI application fetches the relevant weather data (i.e. weather data for the past 7 days from the specific date) as new inputs. The weather data is then fed into the wildfire prediction model (from H2O Driverless AI). The model output is the severity value which ranges from zero (i.e. no risk of a wildfire) to 5000+ as shown in the following table.
The Key Takeaways
The wildfire challenge has taught us a number of things which need to be considered when it comes to deploying an AI-based solution:
- Preparing the dataset and accounting for potential biasing issues when training the dataset.
- Being innovative in creating the pipeline for data gathering and model training.
- Designing UI/UX in a way users can easily navigate and understand the application.
Other than that, it taught us how can we use H2O tools like Driverless AI, Wave and AutoDoc to simply create a complete AI solution.
