






H2O.ai Tops GAIA Leaderboard: A New Era of AI Agents

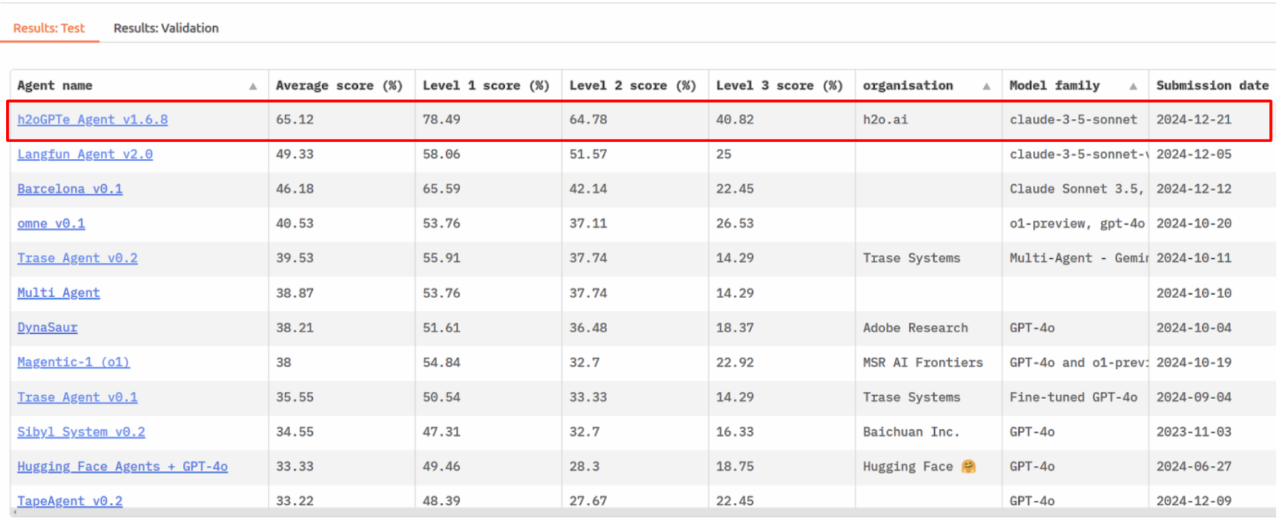
We're excited to announce that our h2oGPTe Agent has achieved the top position on the GAIA (General AI Assistants, https://arxiv.org/abs/2311.12983) benchmark leaderboard (https://huggingface.co/spaces/gaia-benchmark/leaderboard), with a remarkable score of 65% - significantly outperforming other major players in the field. This achievement marks an important milestone in our journey toward building more capable and practical AI systems.
GAIA players
Humans achieve about 92% accuracy on the GAIA questions, some being quite challenging. AI labs have submitted to the GAIA benchmark, including with Magentic-1 by Microsoft, Langfun Agent by Google, Hugging Face Agents, and many others related to research on agents by Princeton et al. GPT-4 with relevant tools achieves about 15%, Hugging Face Agent achieves 33%, Microsoft Research achieves 38% using the OpenAI o1 model or 32% with GPT-4o, while Tianqiao & Chrissy Chen Institute using o1-preview with omne achieves 41%. Lately, Google’s Langfun Agent achieved 49%. Enterprise h2oGPTe Agent achieves 65%, a substantial leap.
Understanding GAIA: Benchmark for Real-World AI Capability
GAIA was created by Meta-FAIR, Meta-GenAI, HuggingFace, and AutoGPT teams to stress the limits of LLMs, which at the time (about a year ago) the co-author Yann LeCun noted that “current auto-regressive LLMs don't do very well.” The GAIA benchmark stands apart from other AI benchmarks by focusing on real-world tasks that require a combination of reasoning, multi-modality handling, and tool use proficiency. Unlike narrower benchmarks such as the ARC Prize (https://arcprize.org/arc, which focuses primarily on abstract visual pattern recognition), GAIA evaluates AI on their ability to handle practical tasks that businesses actually need.
The benchmark includes 466 carefully crafted questions across three difficulty levels, testing:
Web browsing and information synthesis
Multi-modal understanding (text, images, audio)
Code execution and data analysis
File handling across various formats
Complex reasoning and planning
GAIA evaluates how well AI systems help users accomplish real tasks - from data analysis to document processing to complex research questions. These questions tend to be more challenging than can be answered by standard “code interpreter” tools by OpenAI and others.
Example questions:
Level 1: What was the actual enrollment count of the clinical trial on H. pylori in acne vulgaris patients from Jan-May 2018 as listed on the NIH website?
Level 2: According to https://www.bls.gov/cps/, what was the difference in unemployment (in %) in the US in june 2009 between 20 years and over men and 20 years and over women?
Level 3: In July 2, 1959 United States standards for grades of processed fruits, vegetables, and certain other products listed as dehydrated, consider the items in the 'dried and dehydrated section' specifically marked as dehydrated along with any items in the Frozen/Chilled section that contain the whole name of the item, but not if they're marked Chilled. As of August 2023, what is the percentage (to the nearest percent) of those standards that have been superseded by a new version since the date given in the 1959 standards?
Answering level 1 questions requires about 5 steps for a human and up to 1 tool, but can challenge AI visual acuity. Level 2 questions require 5-10 human steps and any tools, while level 3 questions require humans up to 50 steps and any number of tools.
Why GAIA Matters for Business
The business implications of GAIA performance are substantial. As Microsoft CEO Satya Nadella recently pointed out (https://youtu.be/a_RjOhCkhvQ), we're moving from an era of standalone SaaS applications to AI agents that can orchestrate multiple tools and data sources. This shift has profound implications for how businesses will operate in the future.
Nadella notes that traditional SaaS applications are essentially "CRUD databases with business logic," but in the AI agent era, "the business logic is all going to these AI agents." These agents won't be limited to single applications - they'll work across multiple repositories and databases, orchestrating complex workflows that previously required multiple specialized tools and human intervention.
Our Approach: Simplicity and Adaptability
Our success on GAIA stems from a deliberately streamlined approach that prioritizes adaptability over complexity. As Noam Brown of OpenAI (https://youtu.be/OoL8K_AFqkw?t=1693, a creator of o1) insightfully points out: "You don't want to be in a position where the model capabilities improve and suddenly the models can just do that thing out of the box and now you've wasted six months building scaffolding or some specialized, you know, agentic workflow that now the models can just do out of the box."
The latest reasoning models like OpenAI o1 and o3 are milestones in raw intelligence, but their cost is still prohibitive for complex agentic workflows. A balance of small specialized models, fast large models, and slow reasoning models is currently optimal. We use a combination of a few standard models for audio-visual understanding and reasoning to achieve our results, using a primary model of Anthropic’s Sonnet 3.5 with prompt caching for a cost-effective approach.
Key aspects of our approach include:
Streamlined Architecture:
Single agent whose accuracy scales with model capabilities
Minimal scaffolding, no orchestration, no explicit memory management
Code-first agent within code execution environment allowing adaptability
Simple integration of tools without complex multi-agent orchestration
No fine-tuning of foundational models required
Modular Tools
Tools connected through simple inputs and outputs
LLM makes autonomous decisions without rigid orchestration
Modular design allows easy addition of new capabilities
Robust Guardrails
User input validation
LLM output verification
Code execution safety
File transfer security
Enterprise h2oGPTe
Enterprise h2oGPTe is a platform for document question-answering via RAG, model evaluation, document AI, and agents. Current agent tools include:
Python and Bash code execution
Web browsing
Web search via Google or Bing
Multi-modal understanding (text, images, audio) via OCR, caption, vision, and transcription models
File handling across various formats
Data science modeling and forecasting (including with DriverlessAI)
Image generation
Wolfram Alpha search
Wikipedia search
Multi-file code editing via Aider
Advanced reasoning via OpenAI o1 or Qwen QwQ
Some robust functionality is implicit without specific tools, such as PDF report generation.
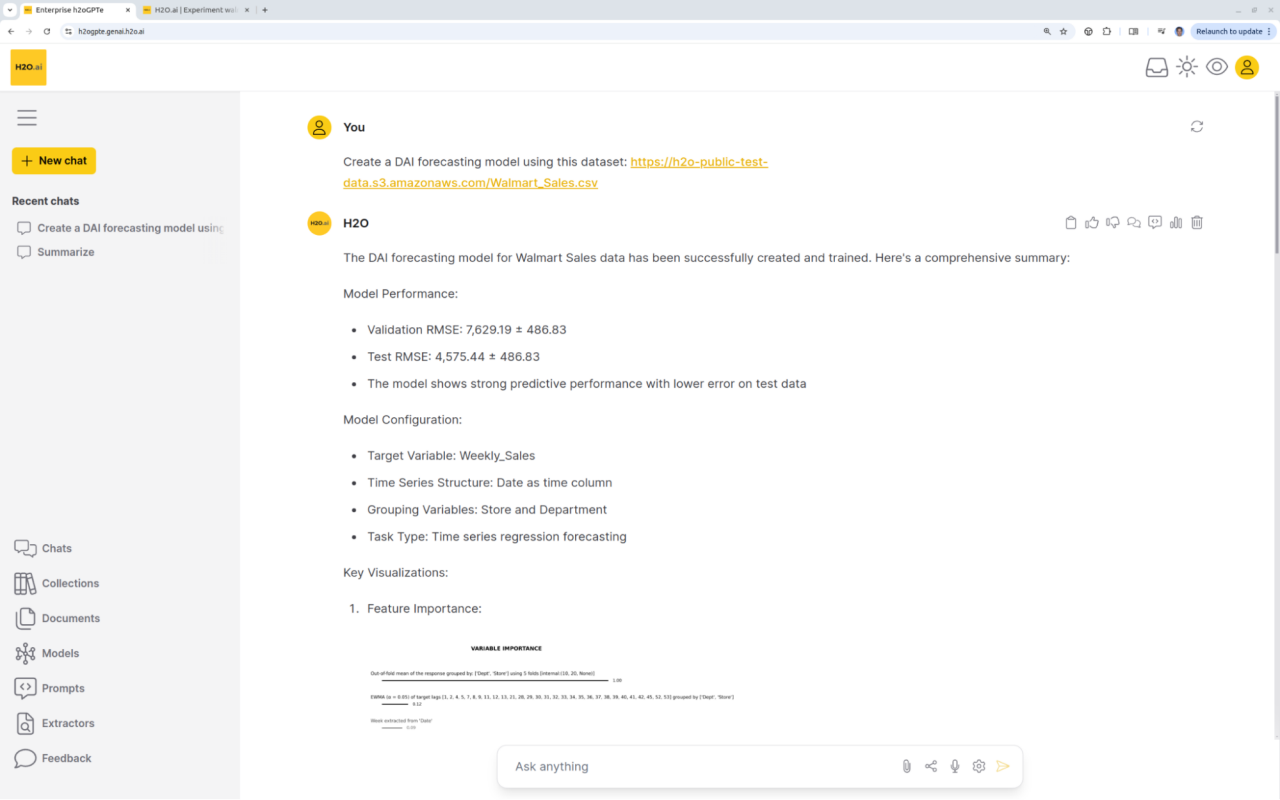
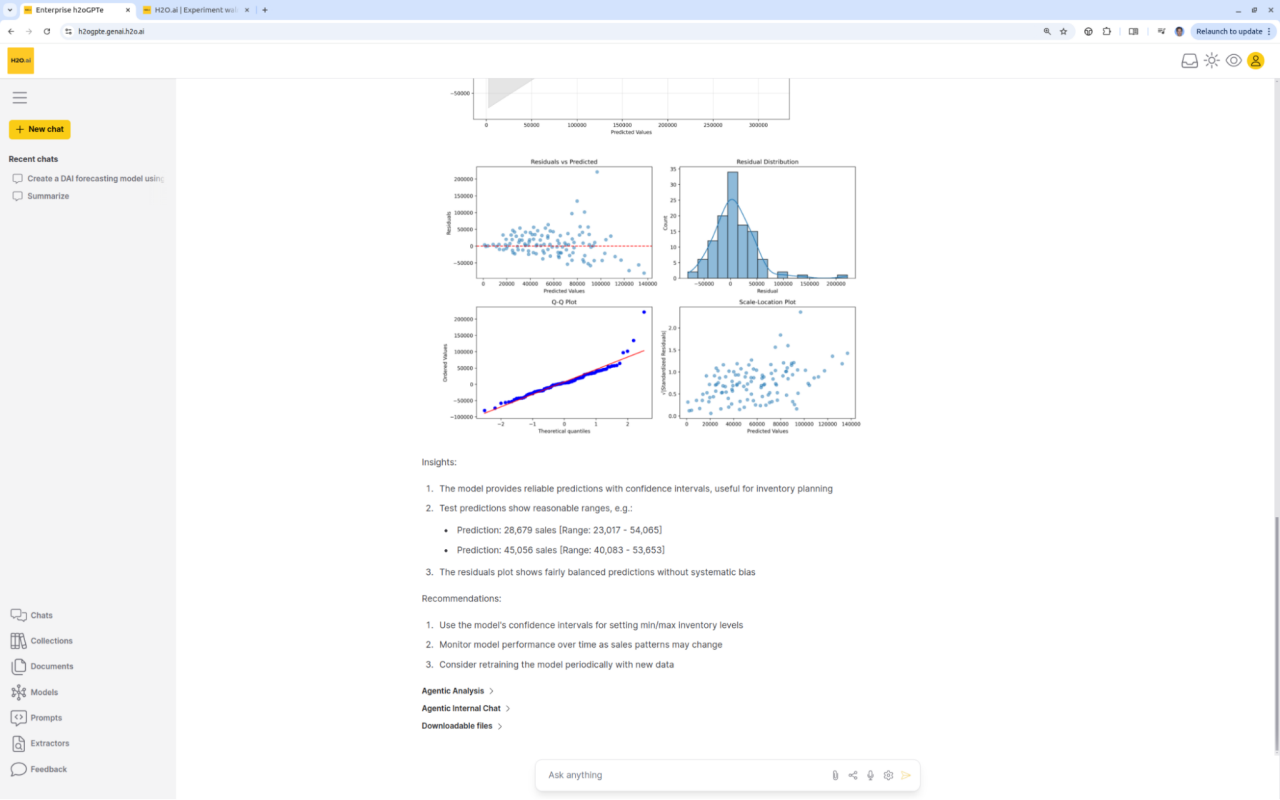
Predictive Analytics meets Generative AI
Enterprise h2oGPTe easily runs DriverlessAI or other machine learning platforms, including for time-series forecasting, from a simple prompt, providing results, insights, and recommendations.
Roadmap
While our current GAIA performance demonstrates leadership in general AI assistance, we're already working on expanding capabilities further:
Showcasing open-source model GAIA results for on-prem solutions
Data Integration (e.g. Teradata and Snowflake connector) and other databases
Custom tools and custom auto-generated agents
The Agentic Future
Our top performance on GAIA represents more than just a technical achievement - it validates our approach to building practical, adaptable AI systems that can truly assist in real-world tasks. As the landscape of AI capabilities continues to evolve rapidly, our focus remains on creating solutions that can naturally incorporate these advancements without requiring constant architectural overhauls.
The future of business software lies not in isolated applications but in intelligent agents that can seamlessly coordinate across tools and data sources. Our success with GAIA demonstrates that we're leading the way in making this future a reality.
Learn more about us at h2o.ai.
Try out our freemium offer that includes agents at https://h2ogpte.genai.h2o.ai/. GAIA benchmarks were run with agent accuracy setting of maximum with majority voting over 3 samples.
h2oGPTe Agents Team: Jonathan McKinney, Fatih Ozturk, Laura Fink, and many others.







