







Comprehensive Guide to Image Classification using H2O Hydrogen Torch
In this article, we will learn how to build state-of-the-art models in computer vision and natural language processing within a couple of minutes using H2O Hydrogen Torch.
Introduction to H2O Hydrogen Torch
H2O Hydrogen Torch (HT) aims to simplify building and deploying deep learning models for a wide range of tasks in computer vision (CV) and natural language processing (NLP). HT is a no-code graphical user interface (GUI) to build and train state-of-the-art (SOTA) deep learning models easily. The framework is developed by Kaggle Grandmasters and renowned data scientists across the world. HT allows both experienced and novice data scientists to build deep learning models efficiently without any prior knowledge of deep learning frameworks. All you need is H2O AI Cloud .
What can I do with H2O Hydrogen Torch?
Let’s look at some HT use cases for computer vision and natural language processing.
Image Classification (CV)
Classifying an image into a set of classes:
- Dog vs cat
- Identify digits from images
Image Regression (CV)
Predicting a continuous value from an image:
- Identifying the age of a person
- Predict the house price from an image
Object Detection (CV)
Classifying an object in an image along with its position:
- Detect whether chest X-Rays contain pneumonia and draw a bounding box around the area of the disease
- Detect vehicles from the traffic or drone cameras
- Detect required pieces during the assembly processes
Semantic Segmentation (CV)
Identifying the exact shape of an object in an image along with its class:
- Background removal for online meetings
- System for self-driving cars
Instance Segmentation (CV)
The objective of instance segmentation is almost similar to semantic segmentation. The only difference between Semantic and Instance Segmentation is that “semantic segmentation treats multiple objects of the same class as one but instance segmentation treats them as different”. For example:
- Virtual background for more than one person
- Segment lanes and vehicles from a camera
Image Metric Learning (CV)
Identifying the similarity between the images:
- Face recognition
- Search for the images of similar objects in the database
Text Classification (NLP)
Classifying text into different classes:
- Identifying the sentiment of a text (Sentiment Analysis)
- Predicting the tags of an article
Text Regression (NLP)
Predicting a continuous value from text:
- Predict a movie rating from a review
- Predict the degree of popularity of a text
Text Sequence to Sequence (NLP)
Text Sequence to Sequence refers to solving Sequence to Sequence problems. These problems deal with sequences i.e. both input and output consist of a text. For example:
- Machine translation
- Text summarization
Text Token Classification (NLP)
Classifying each word in a text:
- Named entity recognition
- Part-of-speech tagging
Text Metric Learning (NLP)
Identifying the similarity between the text:
- Finding out the duplicate queries on a forum
- Identifying similar documents for a search query
Step-by-Step Tutorial
Okay, it is time to try out HT. You can follow this tutorial and build your first HT deep learning model.
Step 1 – Get Access to Hydrogen Torch
Step 1.1 – Request a demo of H2O AI Cloud
Step 1.2 – Sign in
Step 1.3 – Visit APP STORE

Step 1.4 – Search for Hydrogen Torch
Step 1.5 – Select H2O Hydrogen Torch and then click Run
Step 1.6 – When the instance is ready, click Visit and you will see the HT interface.
Step 2 – Import Dataset
Now let’s go through different options for uploading datasets to HT.
Step 2.1 – Select the import dataset
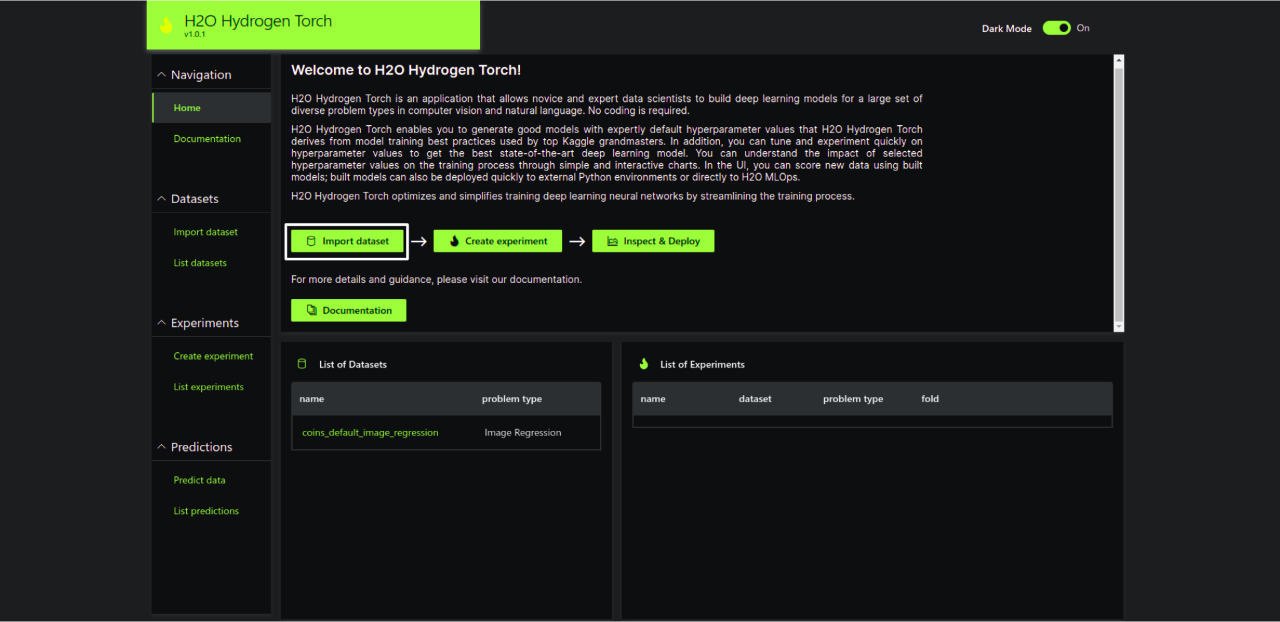
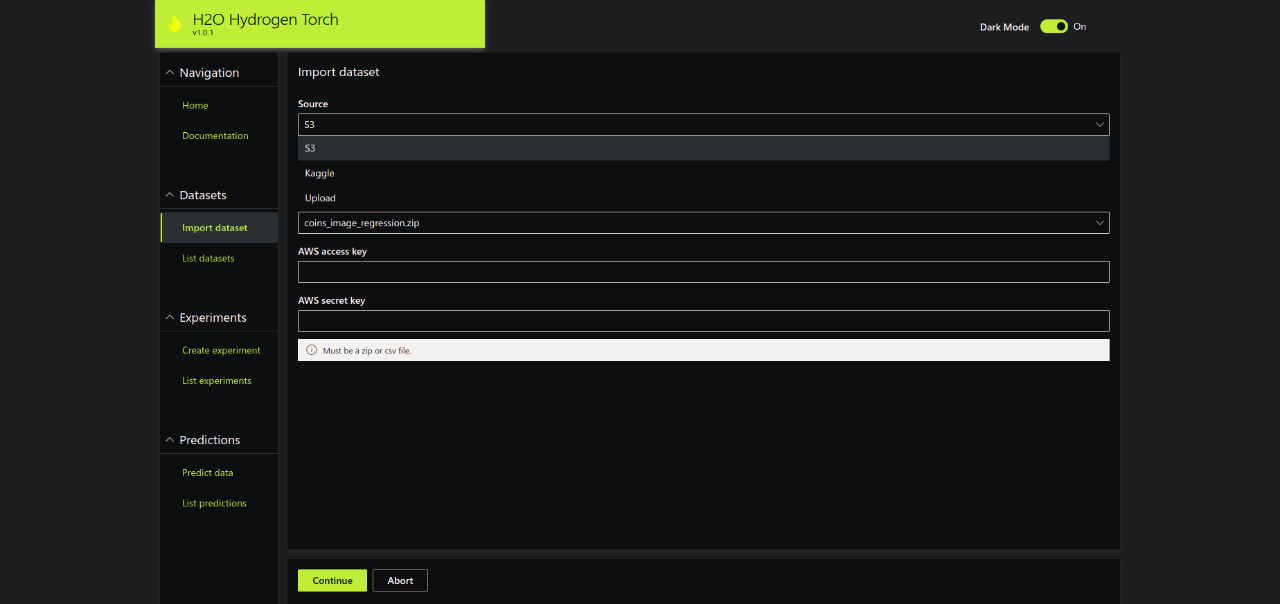
Step 2.2 – Choose the dataset source. It supports 3 options: S3, Kaggle and Upload.
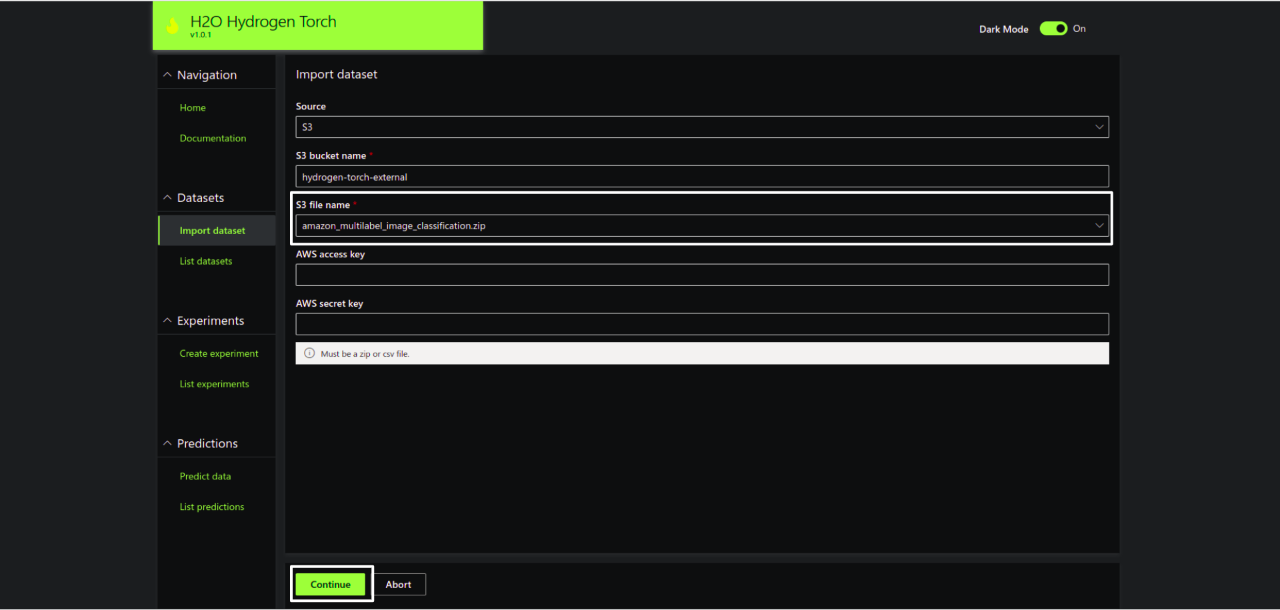
Step 2.3 – Import Amazon Image Classification Dataset
By default, HT provides access to different datasets stored on a public S3 bucket called hydrogen-torch-external. In this tutorial, let’s work on a multi-label image classification problem based on the Amazon image dataset. The dataset consists of satellite images of size 256×256. Each image is tagged into multiple classes like rain forest, agriculture, rivers, towns/cities and so on. The dataset is very noisy and ambiguous. Satellite Imagery Analysis helps in understanding Deforestation and Human Encroachment in the forest. The ultimate objective of the problem is to build an image classifier for tracking the human footprint and thereby reduce deforestation with immediate action.
Amazon Image Classification Dataset

In order to import the Amazon dataset, select amazon_multilabel_image_classification.zip and click continue as shown below:
Step 2.4 – Have a look at the default settings for this dataset and click continue again
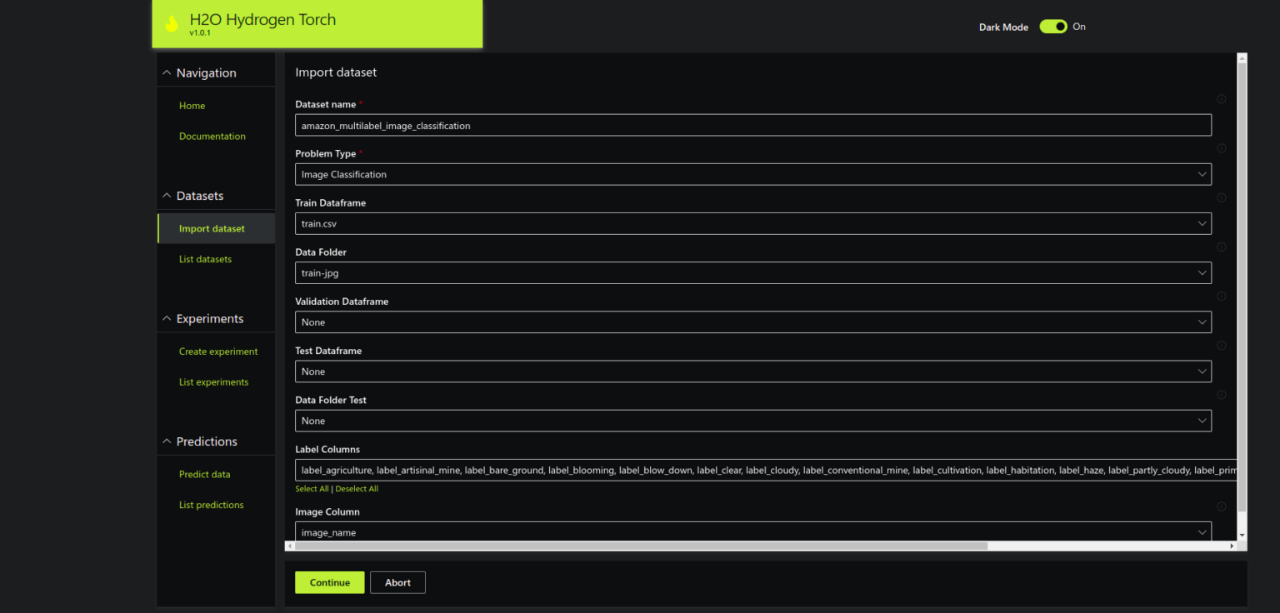
Step 2.5 – You should be able to see a list of imported datasets along with their metadata.
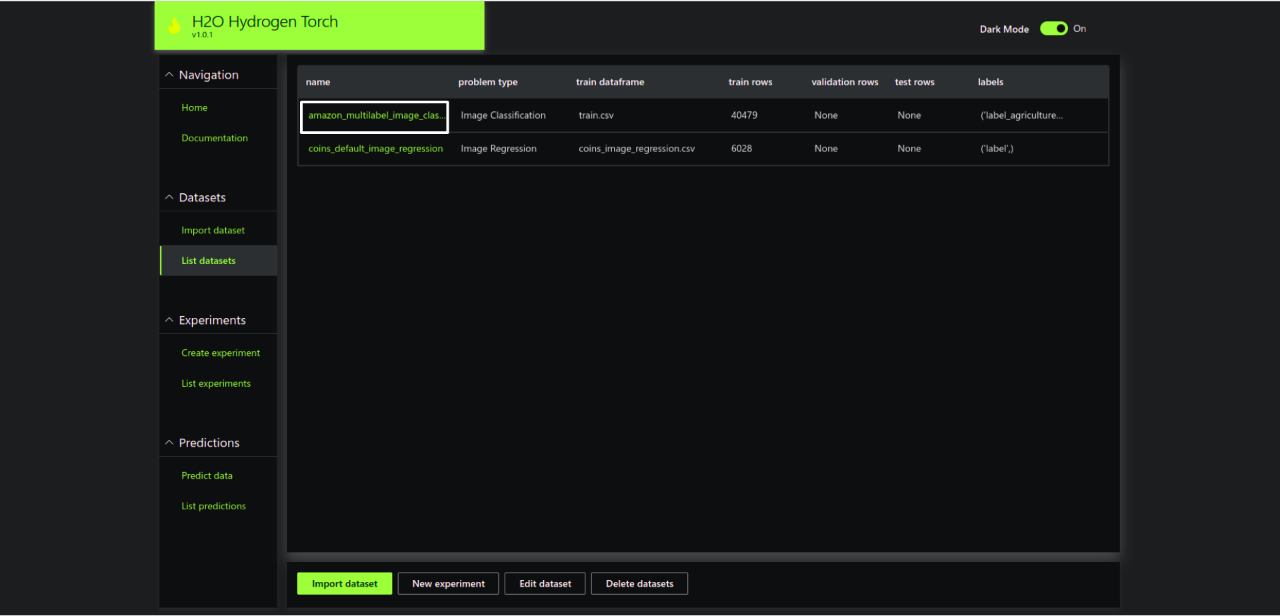
Step 2.6 – Click amazon_multilabel_image_classication and explore the dataset
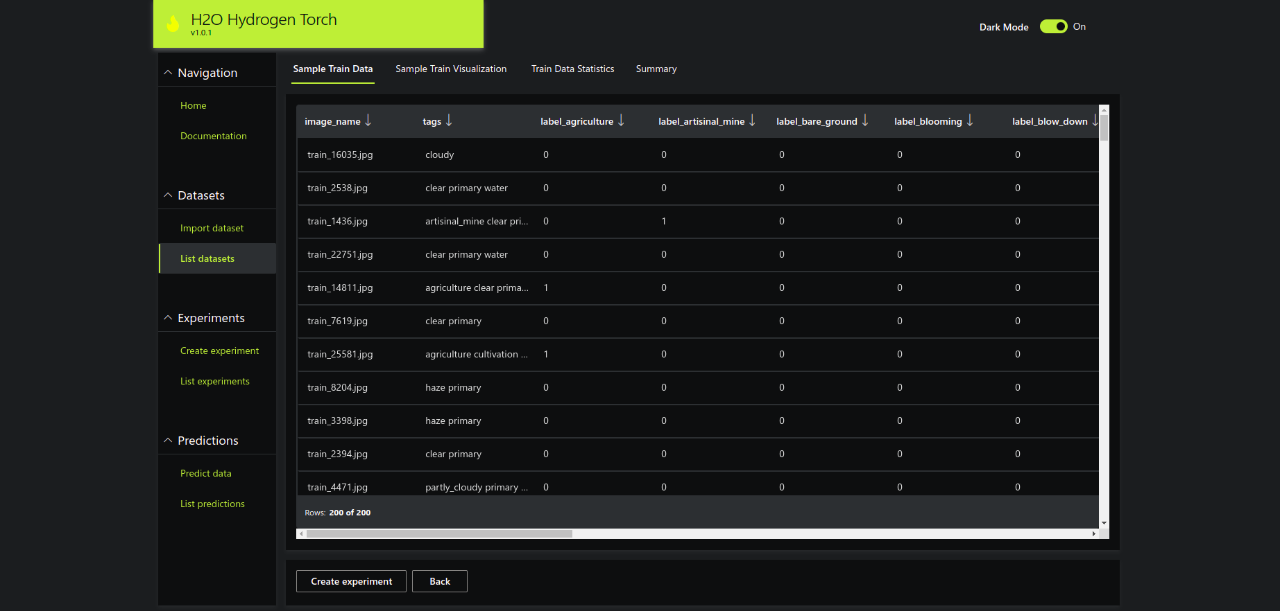
Image Name and Metadata
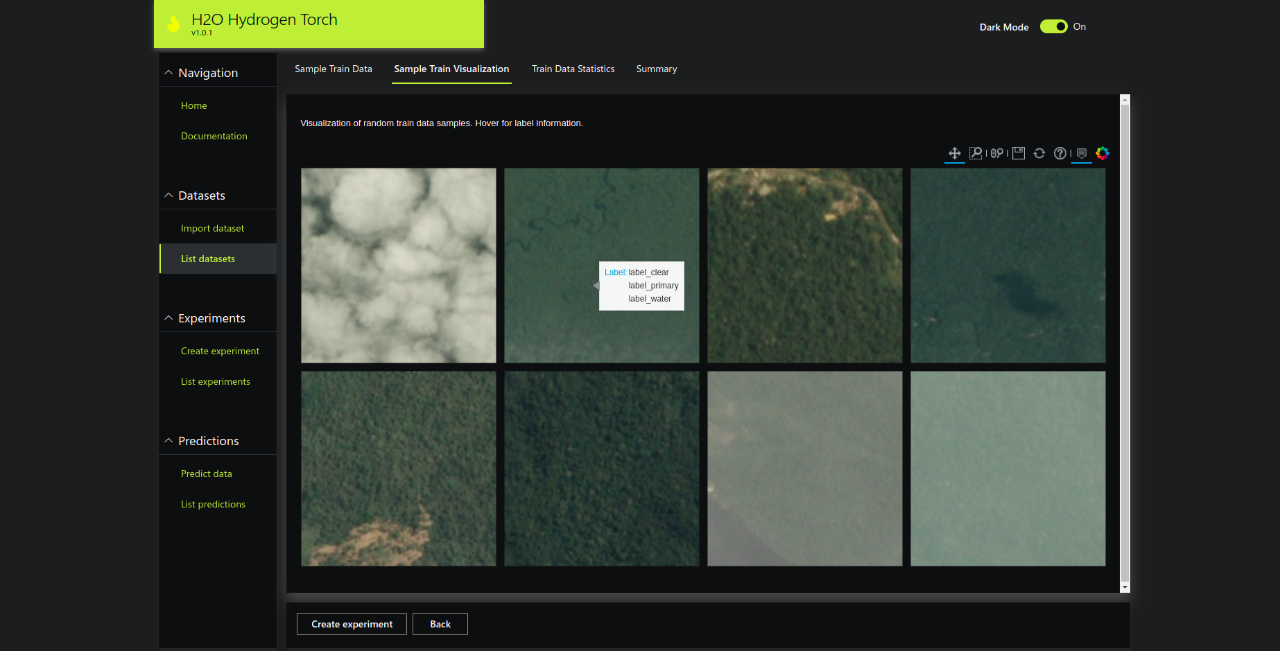
Training Data Visualization
Statistics
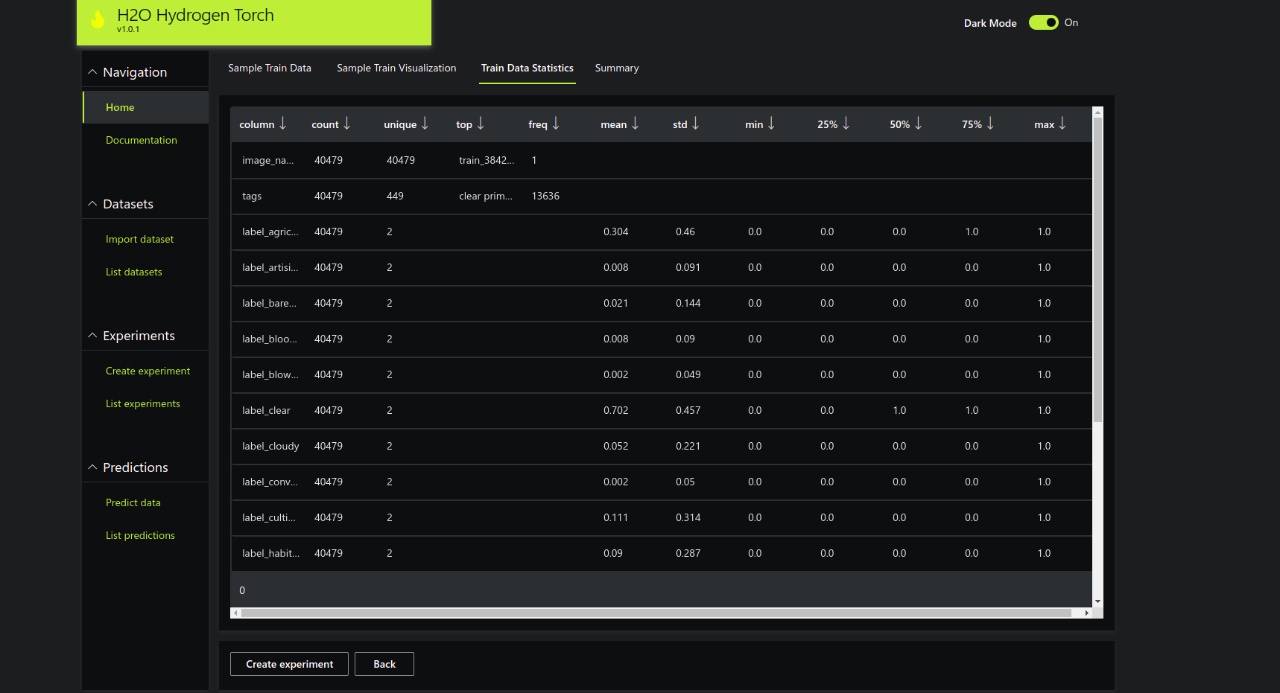
Summary
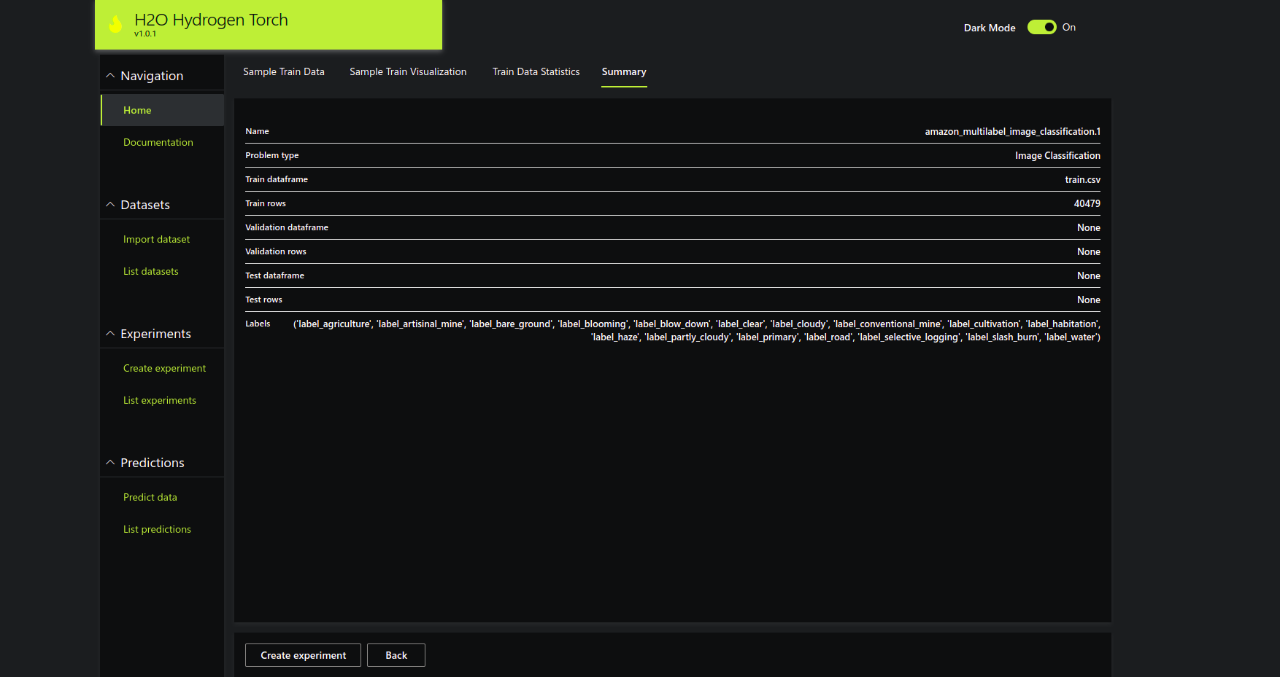
Step 3 – Create an Experiment
We can now build a deep learning model with the Amazon dataset. First, we need to create an experiment.
Step 3.1 – Create an experiment with the Amazon dataset
Any new experiment in HT is populated with some default hyperparameters based on the problem type. These are good default values that should work across a variety of different datasets and are handy for new users.
Creating a New Experiment
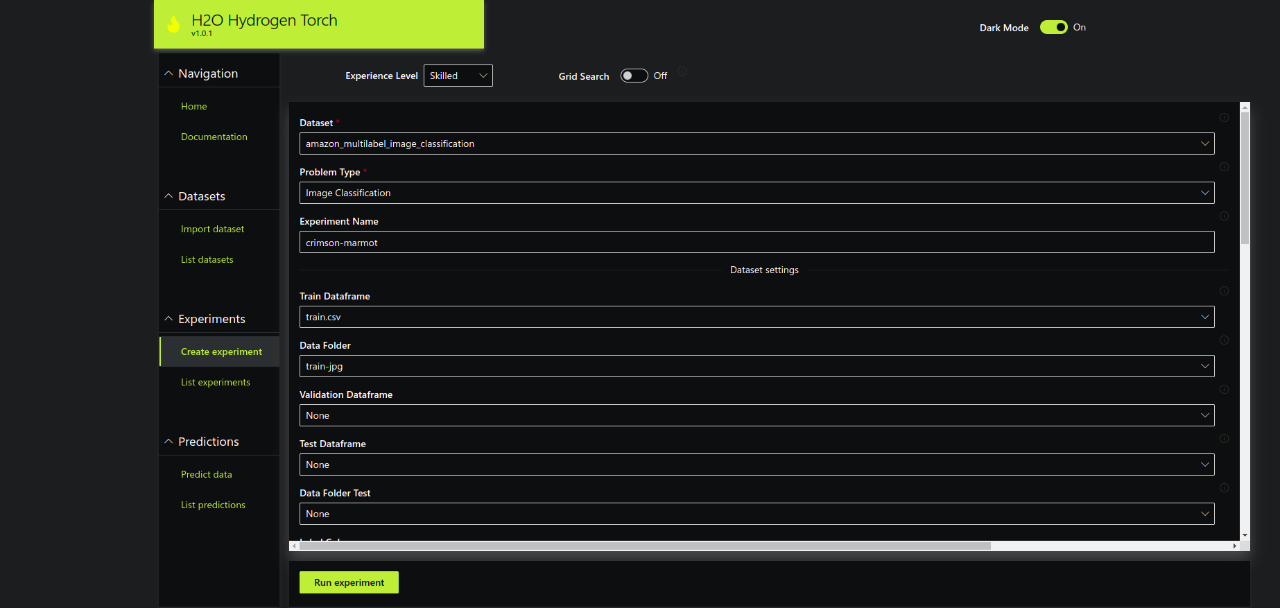
You can do A LOT MORE than relying on the default hyperparameters in HT. By selecting different Experience Level settings, you can get access to more settings and have full control of your deep learning model configuration WITHOUT writing any code. Below are a few examples:
Adjusting Image Input Settings, Network Architecture, and Training Settings
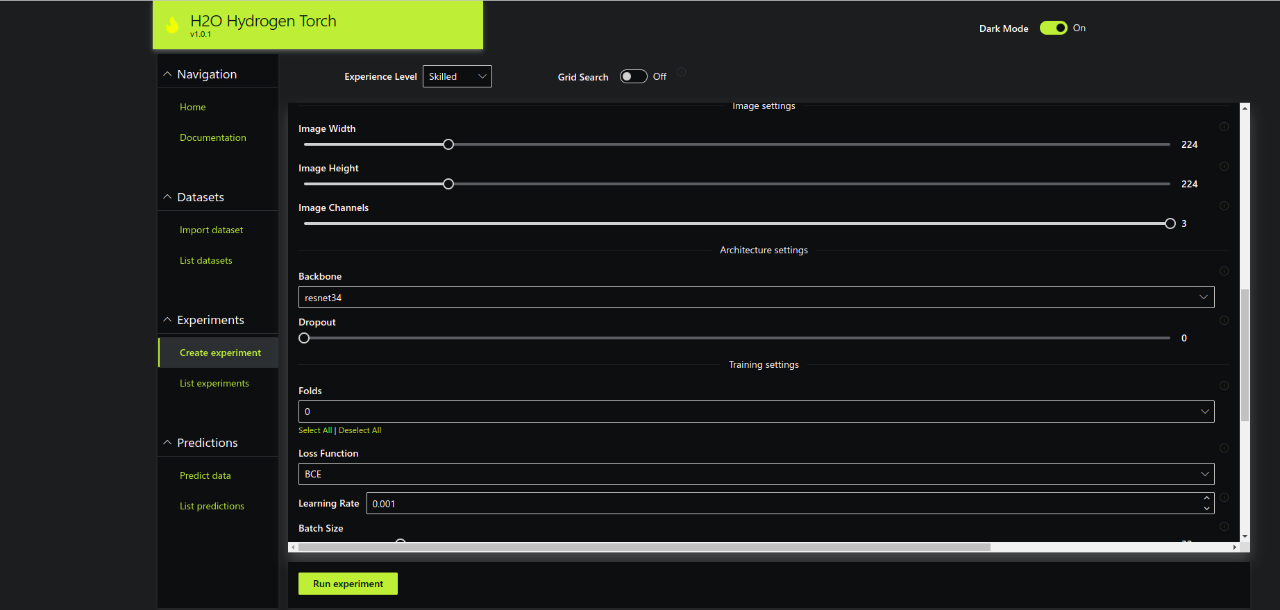
Selecting Different Metrics and Thresholds for Training
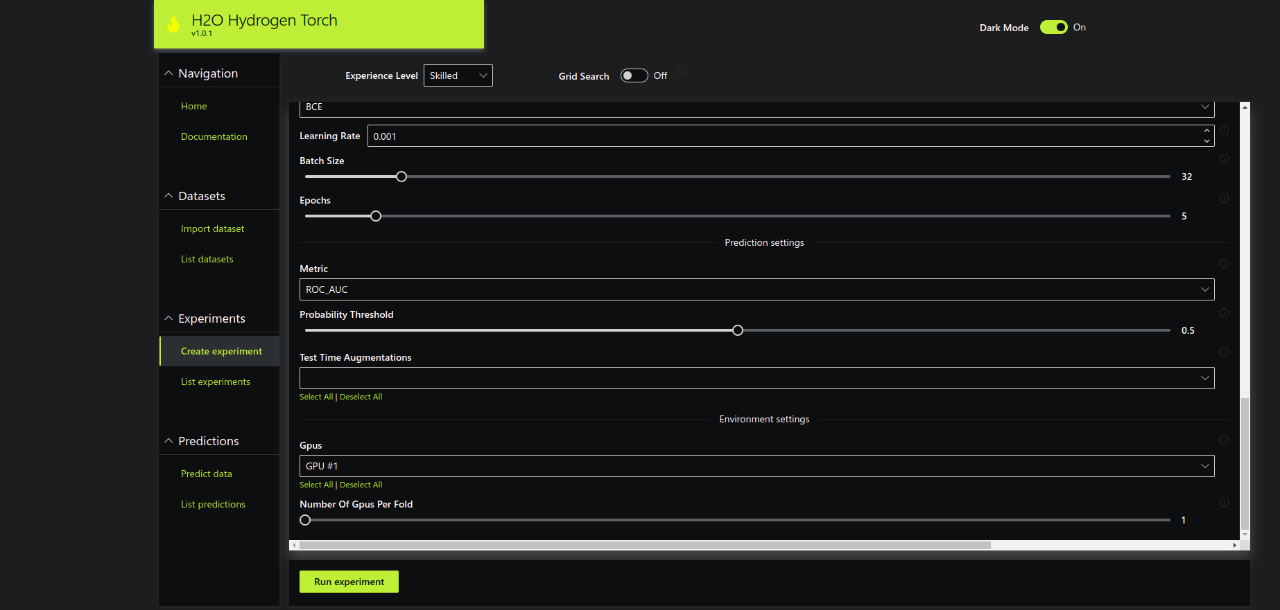
Step 3.2 – Run Experiment
Once you are happy with the experiment settings, click Run experiment. You will be able to find the new experiment from the List experiments tab. You can click Refresh to look at the latest status of the experiment.
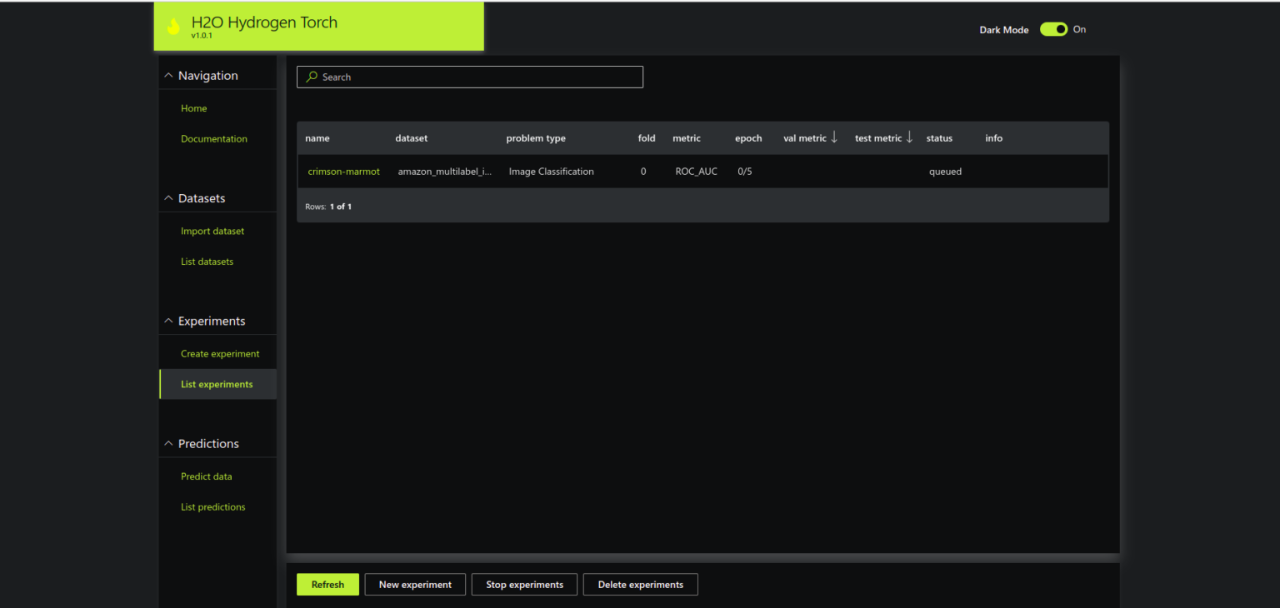
Step 3.3 – Get insights from the experiment
There are a few tabs that you can explore during and after the experiment. Simply click the name of the experiment and you will see different tabs of results as shown below.
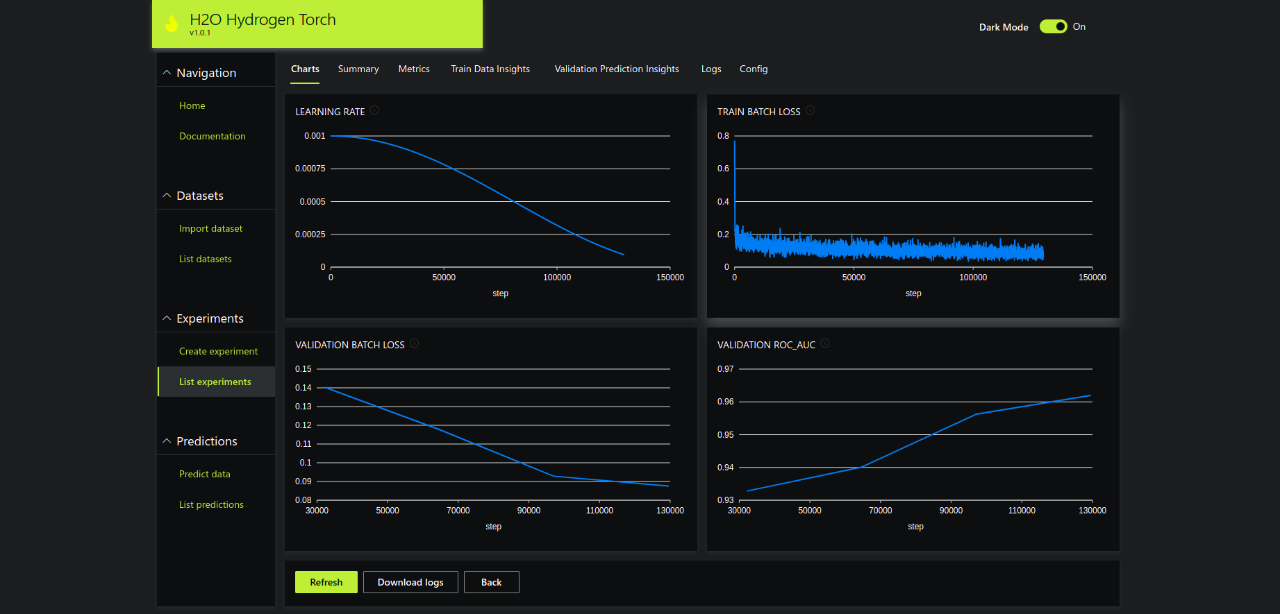
Charts: Model Training Progress
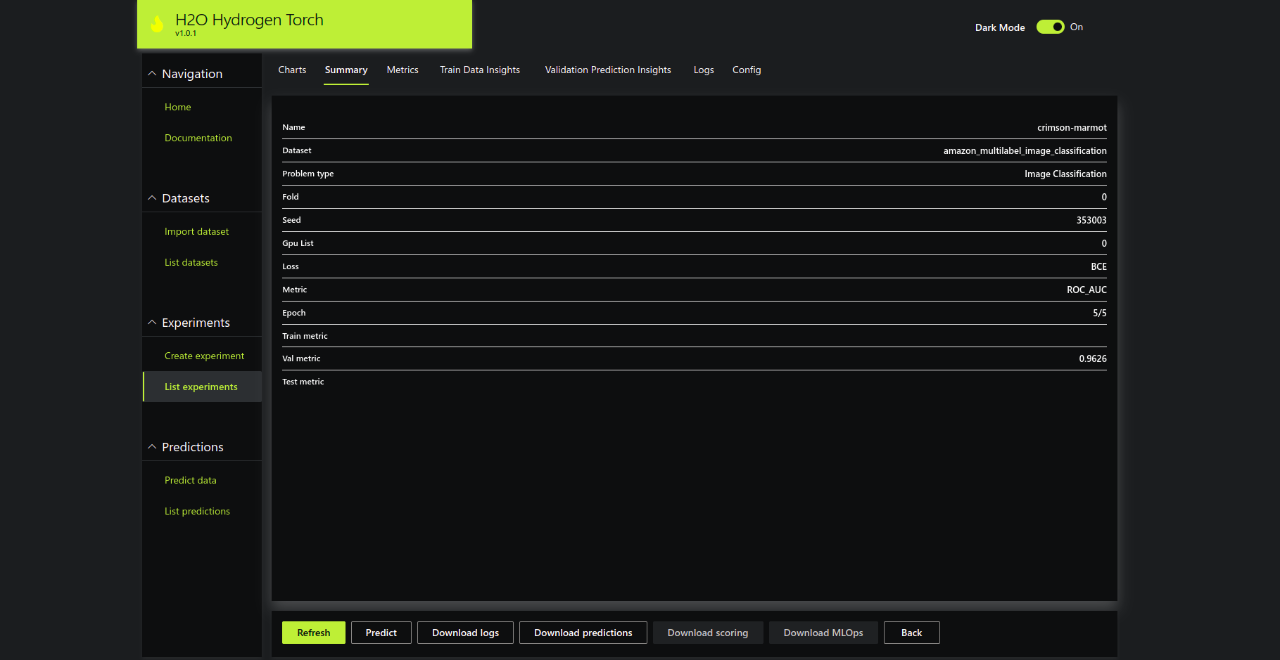
Summary of the Experiment
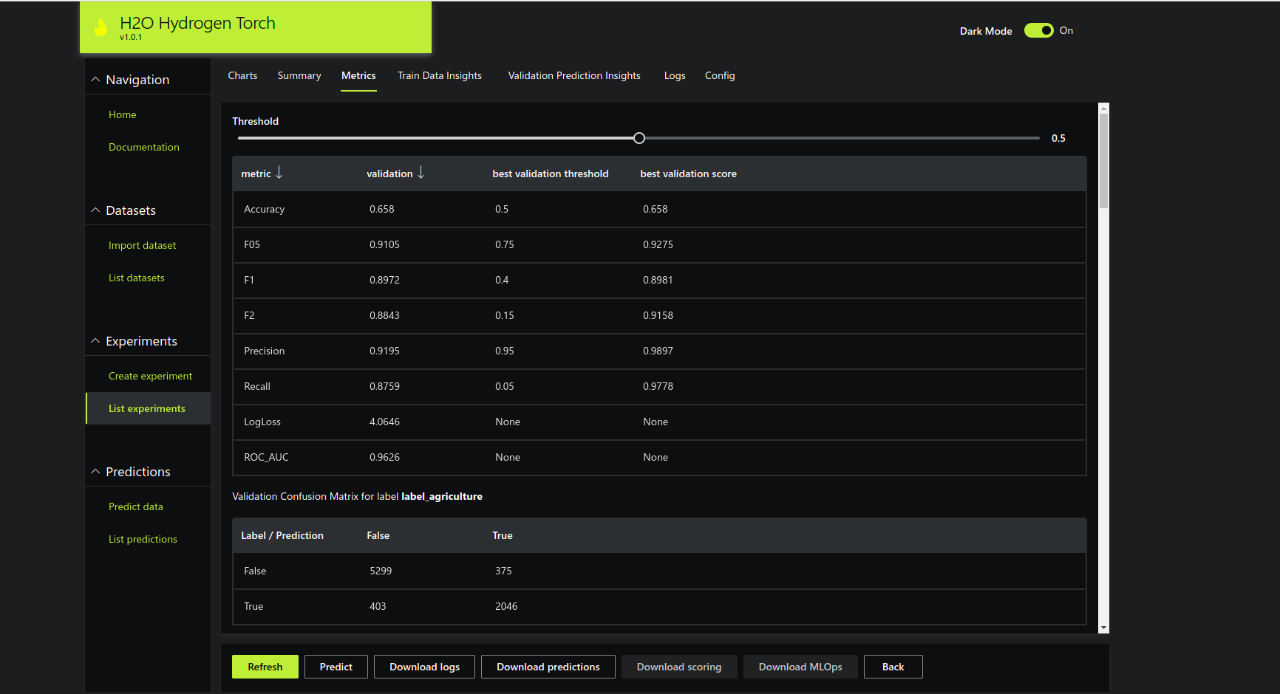
Metrics and Best Threshold
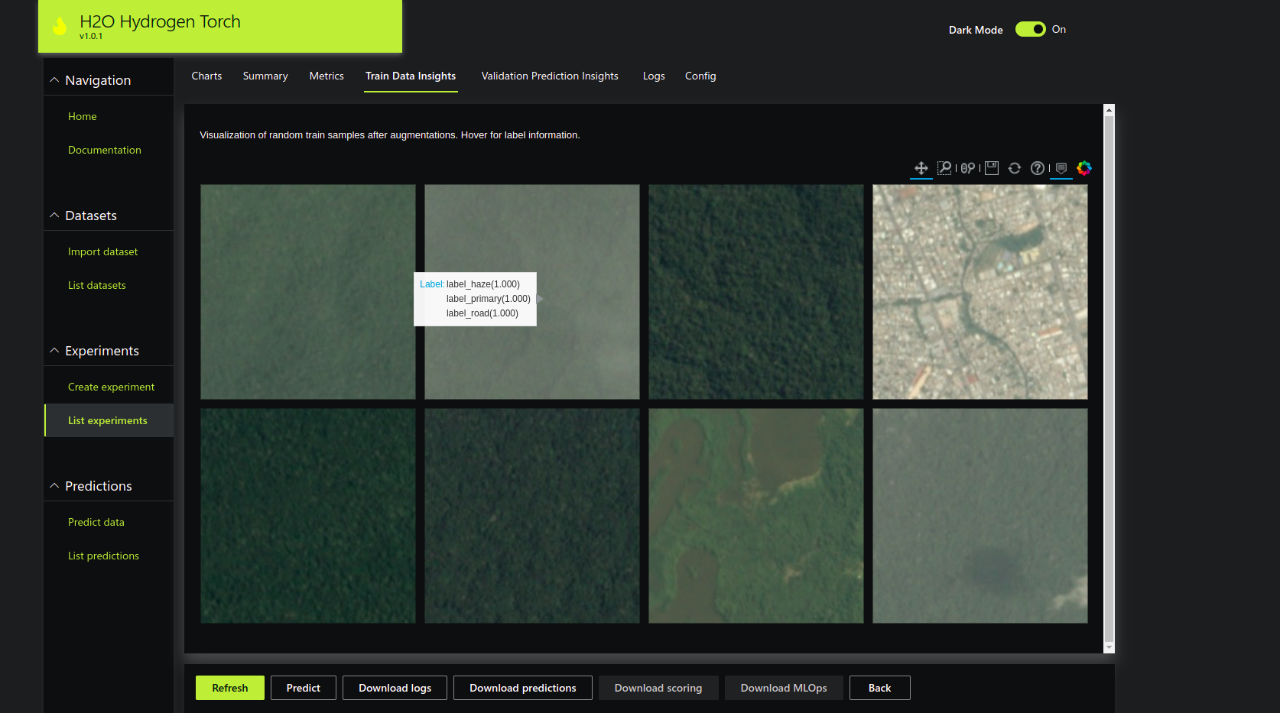
Training Data Insights
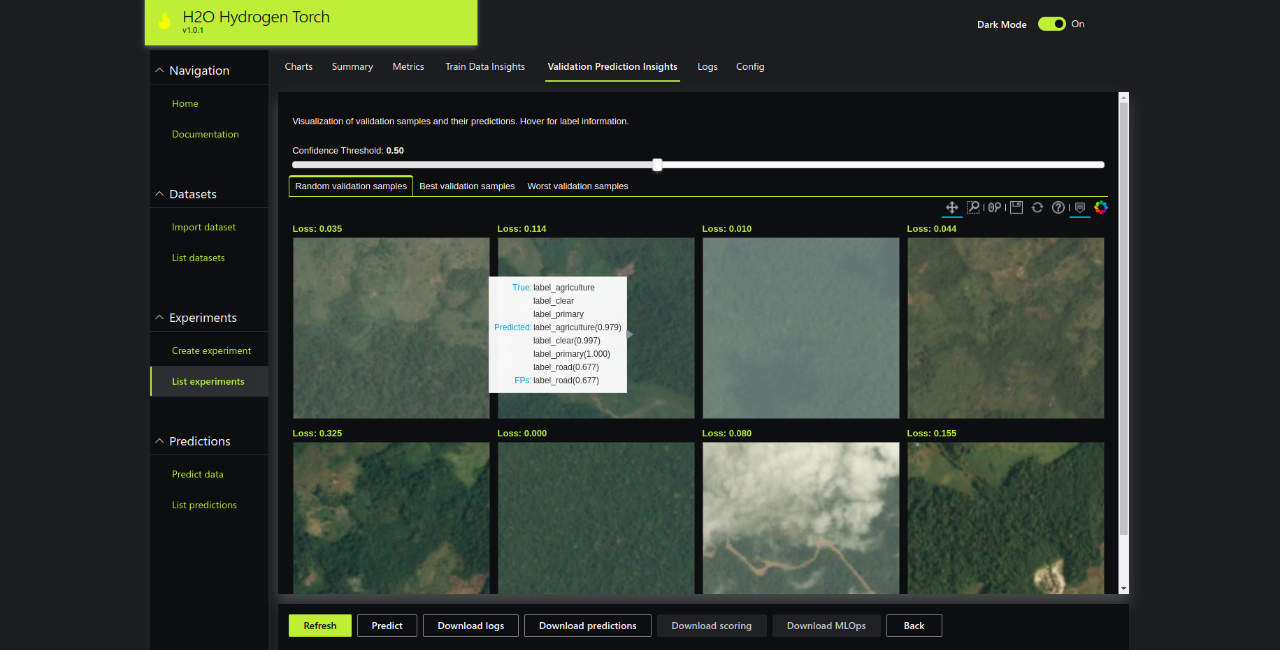
Validation Prediction Insights
Step 4 – Make Predictions
If you have followed all the above steps, you should have trained an image classification deep learning model by now. Let’s use this model to make some predictions.
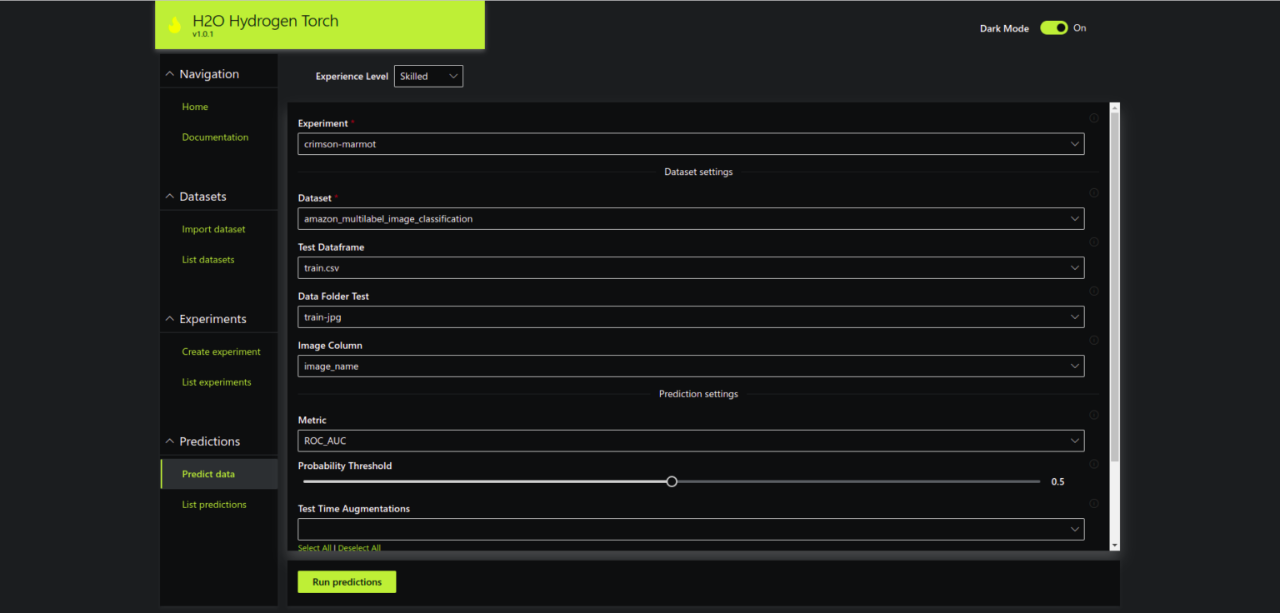
Step 4.1 – Go to Predict data tab
Note: In theory, you should have uploaded a new, unseen dataset for making new predictions. For demonstration purposes, let’s use the same Amazon dataset for now. The main goal here is to walk you through the steps to make new predictions. But do remember that the predictions from the same Amazon datasets are going to be very optimistic as the dataset was used for training.
Select Experiment, Dataset and Metric
Test Prediction Insights
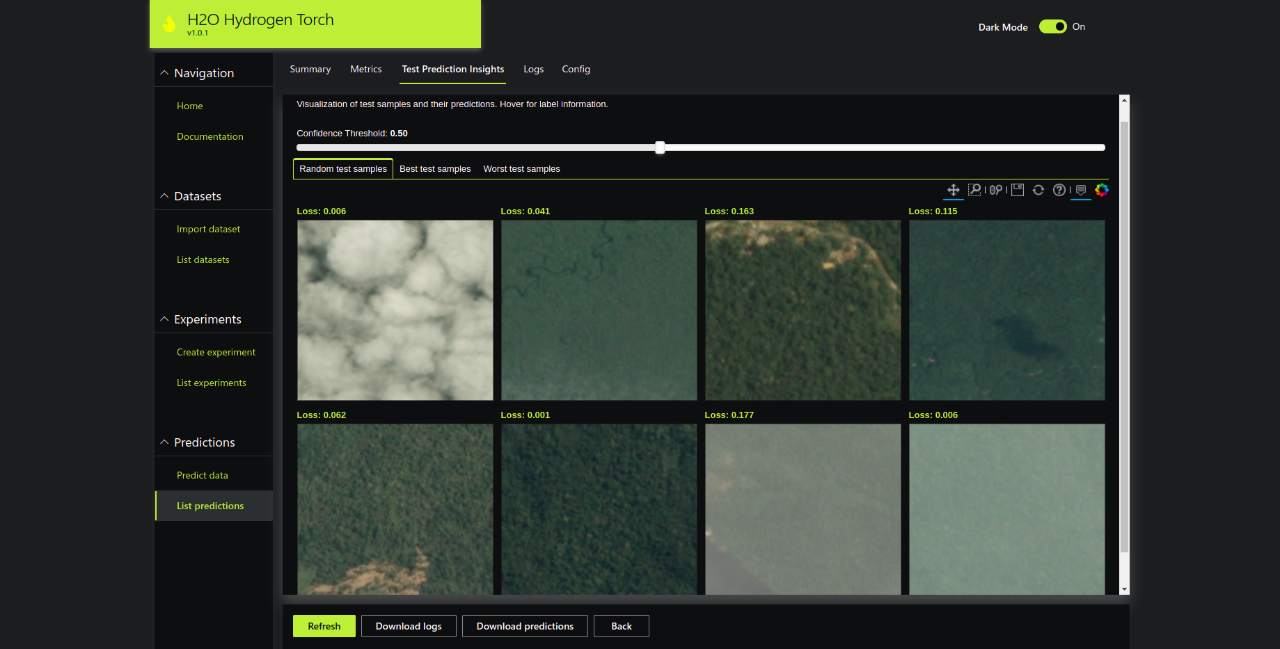
That’s it. I hope you enjoyed this end-to-end, no-code walkthrough of image classification example using H2O Hydrogen Torch.
Let’s Build Some Deep Learning Models
Sign up for our free demo today!. Start building your own SOTA deep learning models today.







