




H2O.ai Tops the General AI Assistant (GAIA) Test

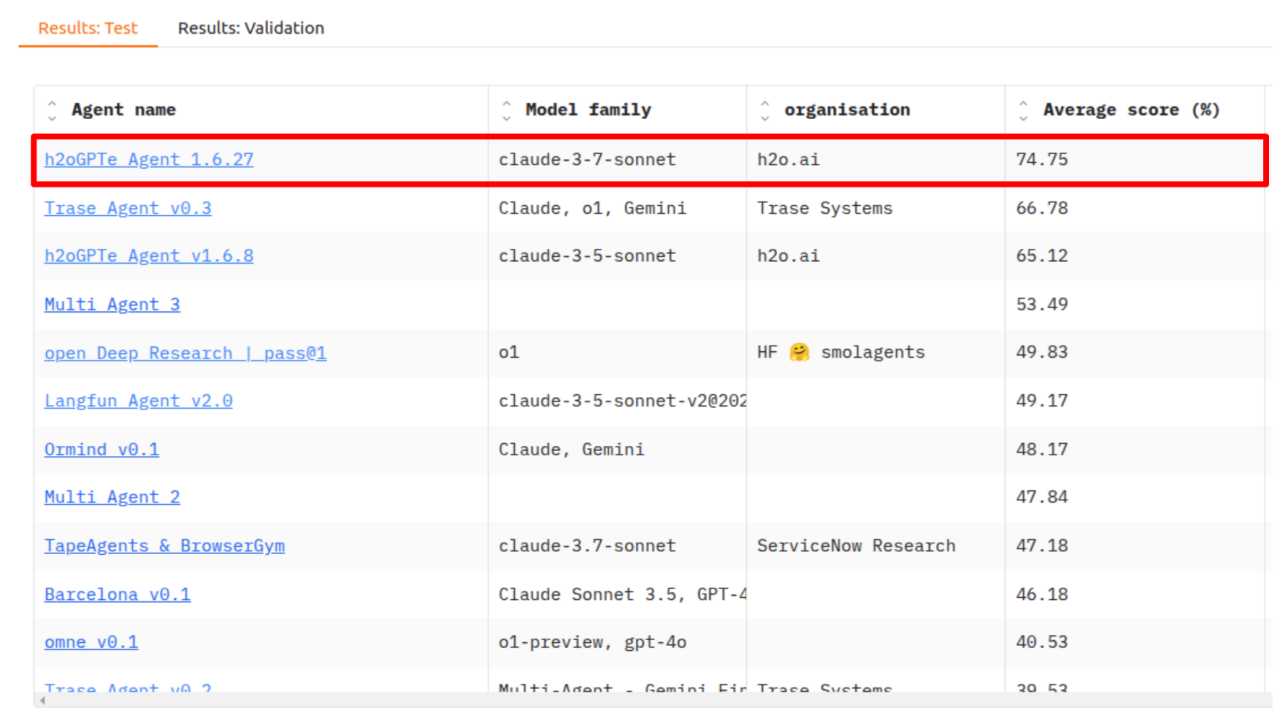
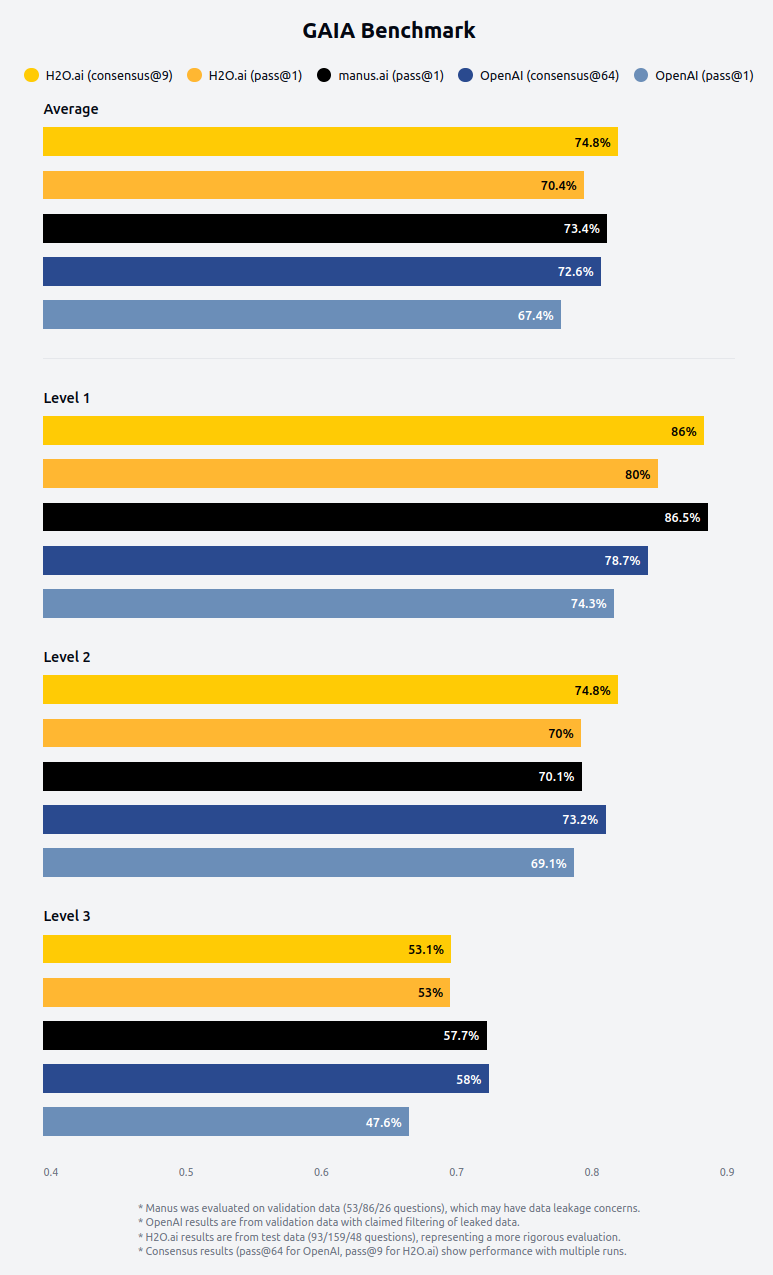
We're proud to announce that our h2oGPTe Agent has once again claimed the #1 spot on the prestigious GAIA (General AI Assistants) benchmark with an impressive 75% accuracy rate – the first time a grade of C has been achieved on the GAIA test set. Previously H2O.ai was first to get a passing grade on the GAIA test. This achievement places us ahead of OpenAI's Deep Research while matching the performance of newcomer Manus. This milestone validates our vision and approach to creating AI assistants that deliver both exceptional capability and practical value in real-world applications.
New Agent Capabilities
Since our previous announcement about our GAIA benchmark results, we've significantly enhanced our agent technology with several key features that contributed to our improved performance:
- Enhanced Browser Navigation
Our agent now features sophisticated web navigation capabilities that allow it to explore complex websites, follow links intelligently, and extract relevant information with greater precision. It can fill in forms, extract HTML and Google Sheets tables, screenshot or answer questions about specific web elements on the page, search within a page, fill in all form fields at once, save pages as PDF, and much more. These capabilities significantly enhance the open-source browser-use package and enable the agent to handle multi-step research tasks that require deep exploration of online resources.
- Unified Search Across Multiple Engines
Our agent now employs an advanced unified search tool that uses query understanding to decide which search engines to utilize for each specific task. It intelligently coordinates searches across Google (with various versions of the search query derived from query understanding), Bing, News API, Wikipedia, Wolfram Alpha, Semantic Scholar, ArXiv, browser agent, and Wayback Machine. The system aggregates and re-ranks results using an LLM or directly answers questions by reasoning over these consolidated results, providing more comprehensive and accurate information.
- Advanced Reasoning with Claude 3.7 Sonnet
Our agent architecture now incorporates Anthropic's Claude 3.7 Sonnet as our main agent model, with its specialized reasoning mode powering our advanced reasoning agent. This dual-model approach allows our main agent to strategically delegate complex analytical tasks to the reasoning-optimized version, significantly enhancing our problem-solving capabilities while maintaining operational efficiency.
- GitHub Integration for Software Engineering
We've integrated dedicated GitHub tools that empower our agent to navigate repositories, understand codebases, and assist with software engineering tasks. This capability has shown promising results on SWE-bench and similar benchmarks, providing developers with more contextual assistance.
- Live Source Attribution and Inline Response Citations
Our agent has been enhanced with new source attribution capabilities, now displaying live source links as it discovers and uses them during its research process. Additionally, the final responses include inline citations that reference specific sources, creating a rigorous citation framework that enhances transparency and allows users to verify information independently.
Understanding Our GAIA Benchmark Results
GAIA was created by Meta-FAIR, Meta-GenAI, HuggingFace, and AutoGPT teams to stress the limits of LLMs. The GAIA benchmark stands apart from other AI benchmarks by focusing on real-world tasks that require a combination of reasoning, multi-modality handling, and tool use proficiency. GAIA evaluates how well AI systems help users accomplish real tasks - from data analysis to document processing to complex research questions.
The benchmark includes 466 carefully crafted questions across three difficulty levels from easy (level 1) to moderately challenging (level 2) to challenging (level 3), testing:
- Web browsing and information synthesis
- Multi-modal understanding (text, images, audio)
- Code execution and data analysis
- File handling across various formats
- Complex reasoning and planning
Example questions:
- Level 1: What was the actual enrollment count of the clinical trial on H. pylori in acne vulgaris patients from Jan-May 2018 as listed on the NIH website?
- Level 2: According to https://www.bls.gov/cps/, what was the difference in unemployment (in %) in the US in june 2009 between 20 years and over men and 20 years and over women?
- Level 3: In July 2, 1959 United States standards for grades of processed fruits, vegetables, and certain other products listed as dehydrated, consider the items in the 'dried and dehydrated section' specifically marked as dehydrated along with any items in the Frozen/Chilled section that contain the whole name of the item, but not if they're marked Chilled. As of August 2023, what is the percentage (to the nearest percent) of those standards that have been superseded by a new version since the date given in the 1959 standards?
Answering level 1 questions requires about 5 steps for a human and up to 1 tool, but can challenge AI visual acuity. Level 2 questions require 5-10 human steps and any tools, while level 3 questions require humans up to 50 steps and any number of tools.
Benchmark Methodology and Data Contamination Challenges
While benchmarks like GAIA provide valuable insight into agent capabilities, we must acknowledge important methodological considerations that affect interpretation:
- All of the GAIA validation set questions and answers are widely available online and have been incorporated into LLM training datasets, creating potential data contamination.
- During our GAIA runs, we decontaminated our agent by explicitly blocking certain websites known to contain benchmark answers, but we observed that underlying LLMs have memorized portions of the validation data.
- Even when blocking direct sources with validation data, we found that models can display suspiciously accurate "guesses" about search strategies or intermediate steps—a more subtle form of contamination.
- This data leakage makes the validation set less reliable for true benchmarking purposes compared to the test set, which provides a more rigorous evaluation environment.
- The validation data set is more like doing homework with solutions in the book or an open book exam, while the test data set is like a real exam with no published answers.
For these reasons, while OpenAI Deep Research and Manus were evaluated on validation data, our results are evaluated on the test set data, a more rigorous and extensive evaluation involving nearly double the number of questions with no known data leaks.
Additionally, we've identified that approximately 5% of the GAIA validation and test data contain errors or ambiguities in the ground truth answers. Some are simple typos, while others are more substantive discrepancies. These inconsistencies create an interesting methodological opportunity: by examining how different agents respond to questions with problematic ground truths, researchers can better understand whether solutions are being derived through reasoning or potentially influenced by prior exposure to benchmark data. This approach helps advance our collective understanding of benchmark reliability and agent evaluation methodologies.
Coming Soon
We're excited about several upcoming capabilities that will further enhance our agent's performance:
- Streaming document rendering in side panel
- Human-in-loop via pausing and chat during streaming
- Advanced task and sub-task management
- Specialized output response formatting agent
- Autonomous deployment of websites, tools, and agents
- Integration of data connectors like Teradata, Snowflake
Enterprise h2oGPTe
Enterprise h2oGPTe is a platform for document question-answering via RAG, model evaluation, document AI, and agents. Our platform supports cloud, on-premise, and air-gapped deployments, including use of models like DeepSeek R1 or LLaMa 3.3 70B, where DeepSeek R1 achieves about 45% on GAIA test.
Predictive Analytics meets Generative AI
Enterprise h2oGPTe agent runs DriverlessAI or other machine learning platforms from a simple user prompt. DAI does time-series forecasting, fraud prevention modeling, etc., and our agent provides detailed plots, results, data science insights, and business recommendations.
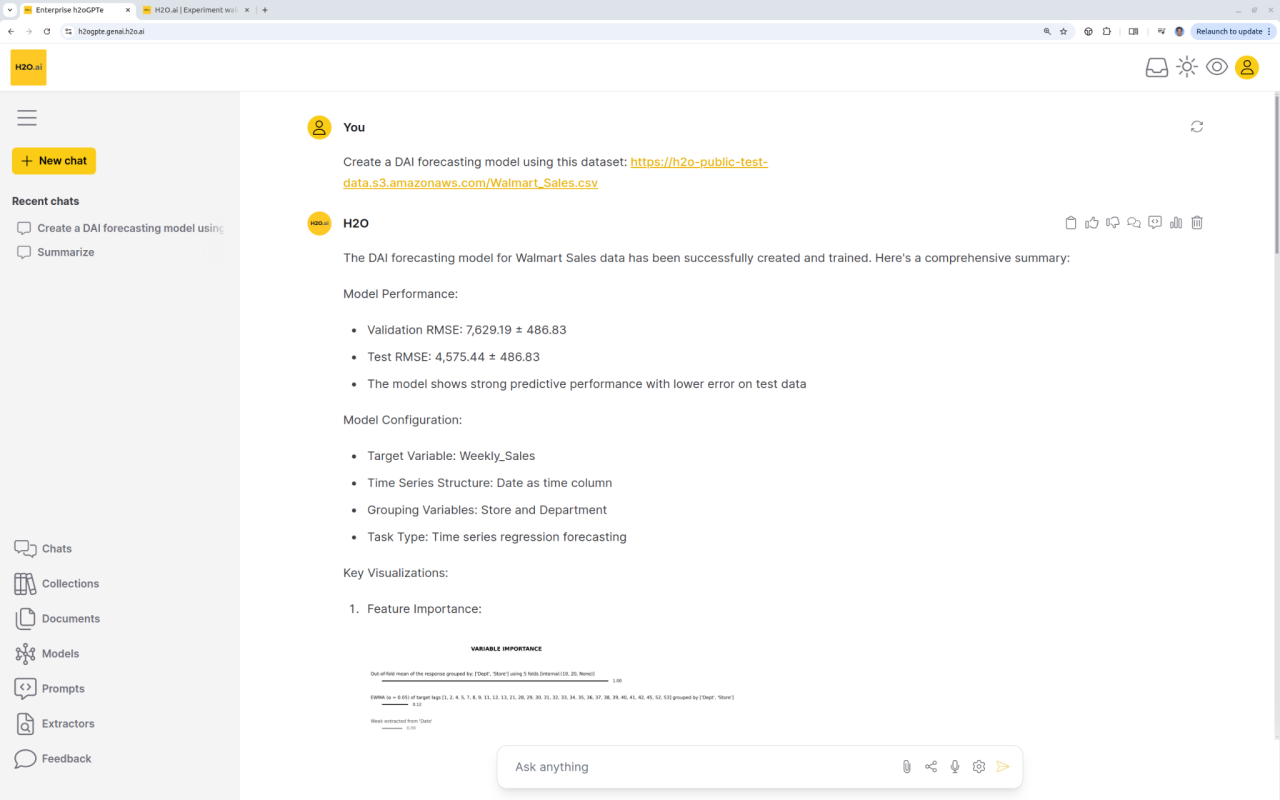
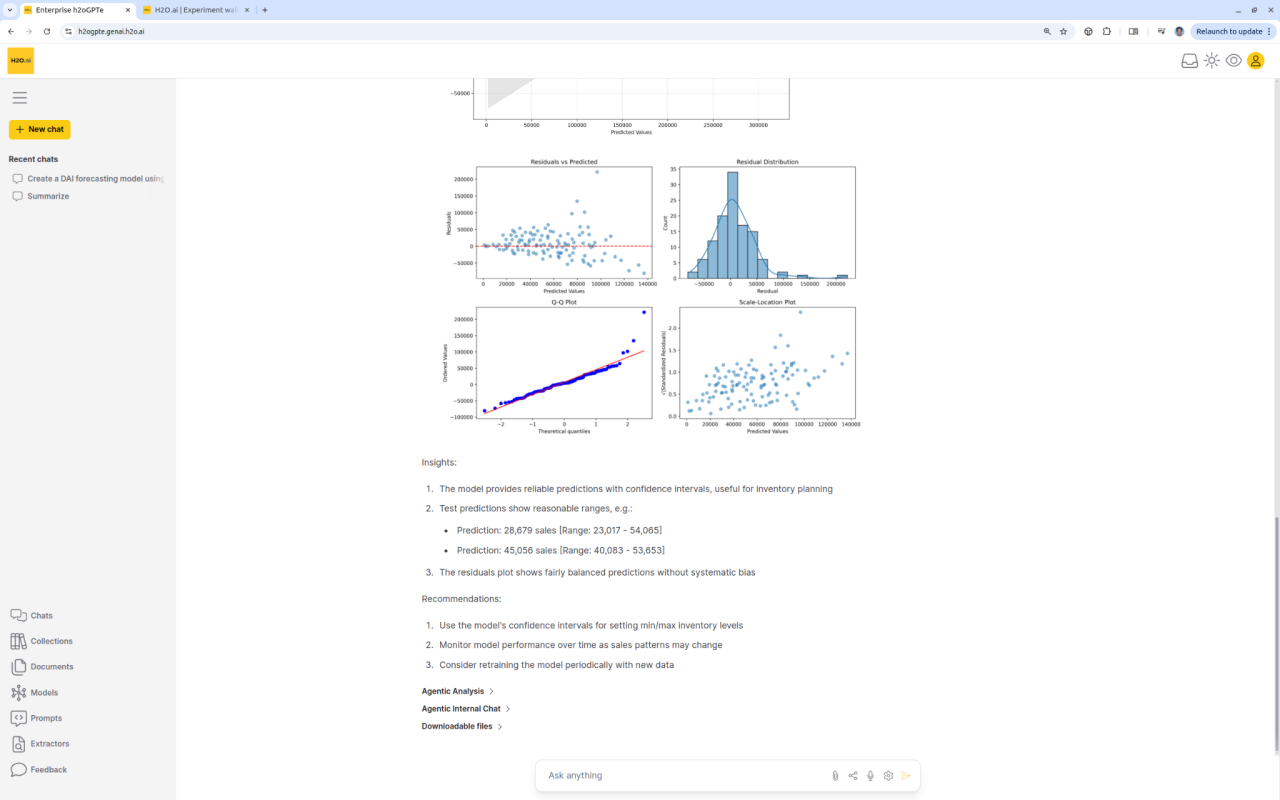
The Agentic Future
Our top performance on GAIA represents more than just a technical achievement—it validates our approach to building practical, adaptable AI systems that can truly assist in real-world tasks.
The future of business software lies not in isolated applications but in intelligent agents that can seamlessly coordinate across tools and data sources. Our success with GAIA demonstrates that we're leading the way in making this future a reality.
Learn more about us at h2o.ai.
Try out our freemium offer that includes agents at https://h2ogpte.genai.h2o.ai/.
h2oGPTe Agents Team: Jon McKinney, Fatih Ozturk, Laura Fink, Mathias Müller, Ryan Chesler, Arno Candel, Kim Montgomery, Luxshan Thavarasa, Prathushan Inparaj, Ruben Alvarez, and many others.







