







Natural Language Processing in H2O’s Driverless AI
Note: I’d like to thank Grandmaster SRK for a lot of suggestions and corrections with the writeup.
Note: All images used here are from the talk. Link to the slides
Driverless AI is H2O’s flagship product. Recently, NLP Support has been added to it along with other domains. In the quick video, Grandmaster SRK gives us an overview of the “recipes ” and under the hood action being done by H2O’s Driverless AI, specifically NLP. Note that all of the points showcased are already available to test out along with more “recipes ” coming soon.
What tasks of NLP can Driverless AI Currently handle?
Classification and Regression tasks and the talk covers how these are handled. Note that while this is marked as NLP, these tasks are not just limited to language, but also work with the categorical and non-language data (Think, documents with financial details, etc)

Another point I’d like to highlight here is these work on raw data without any/negligible manual handling required.
Example Applications and Use-Cases
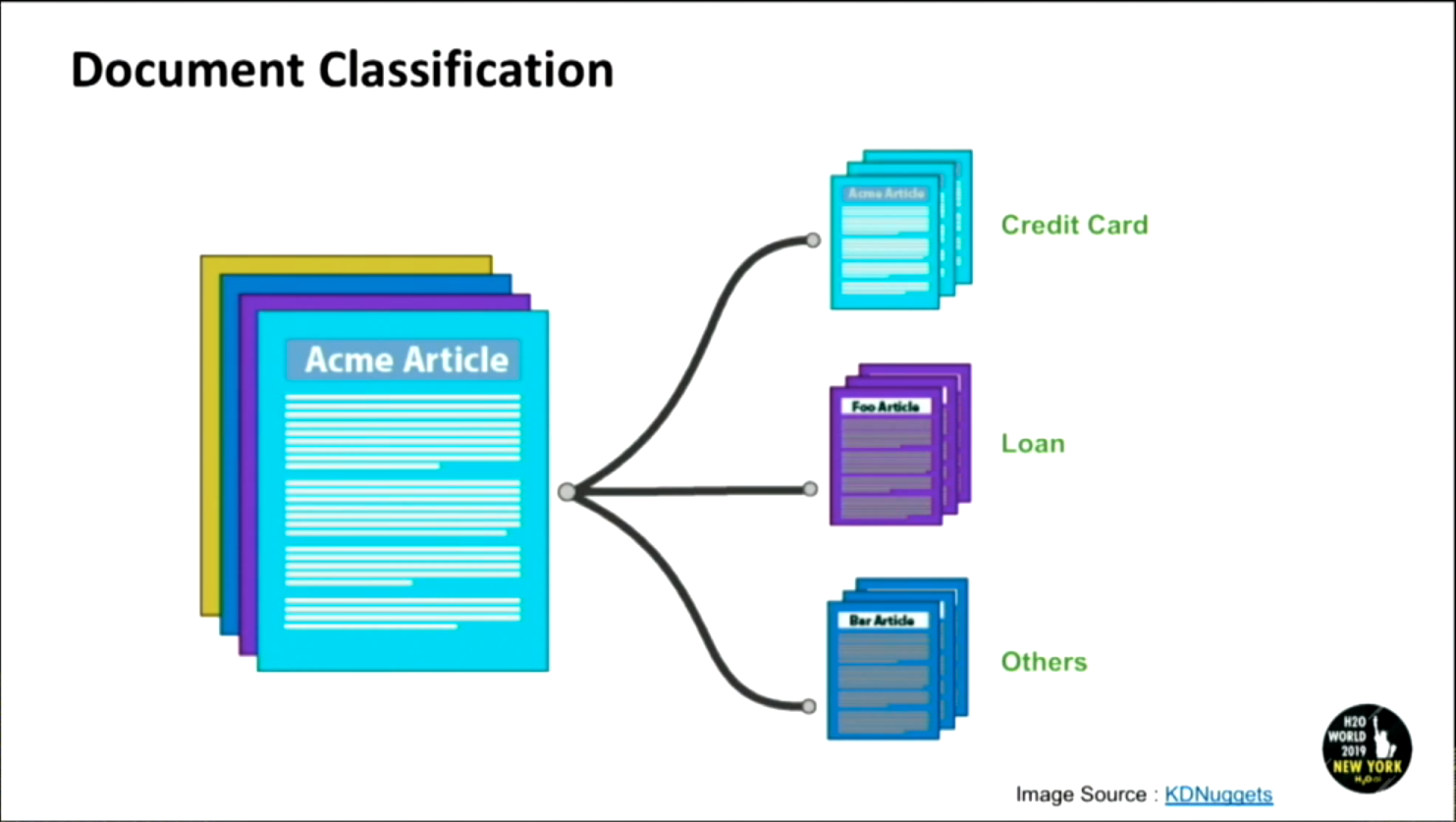
- Document Classification:
Classifying the theme of the document for ex:
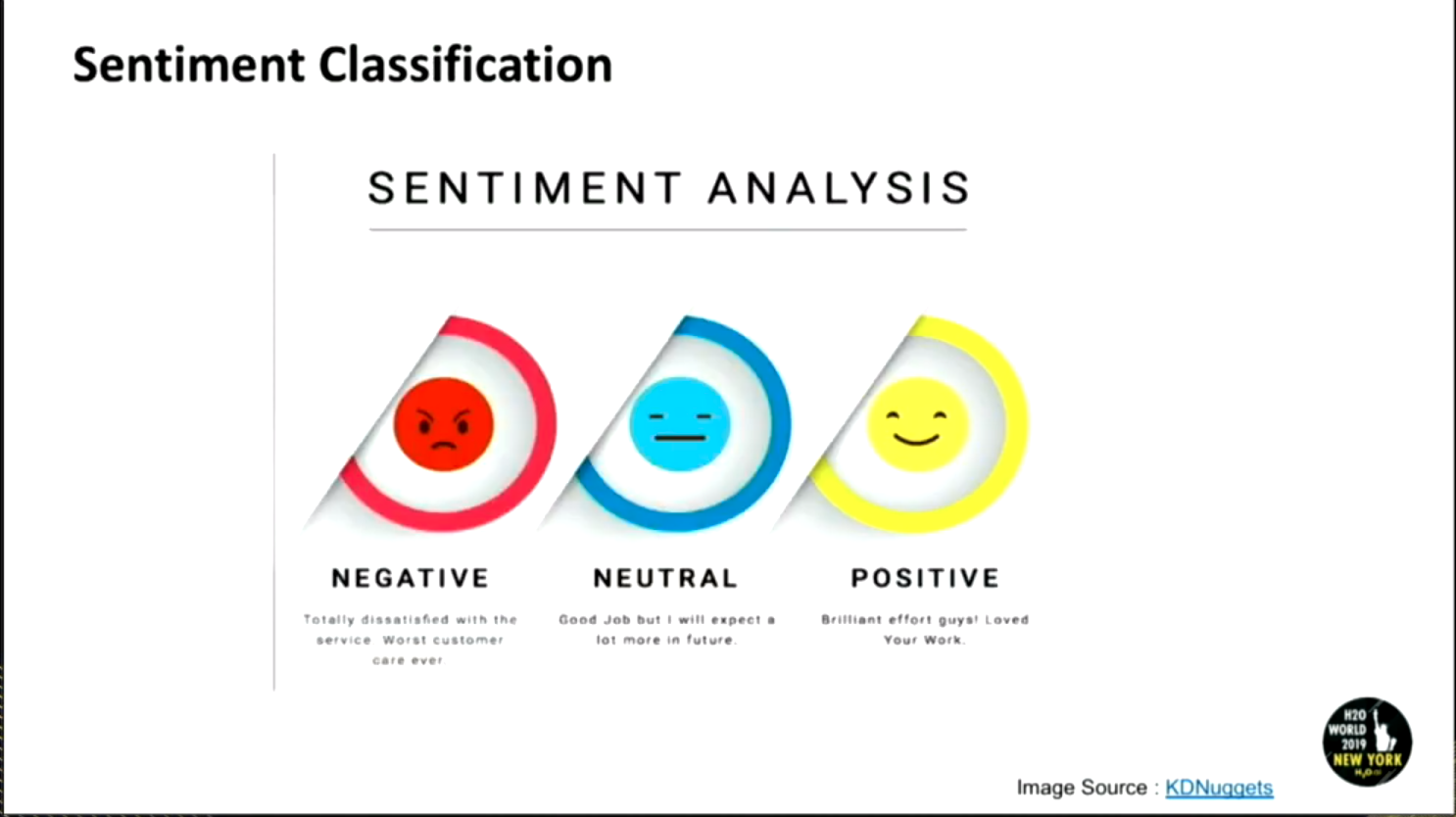
- Sentiment Classification
The ability to classify the sentiment depicted in a text as positive, negative or neutral for example.
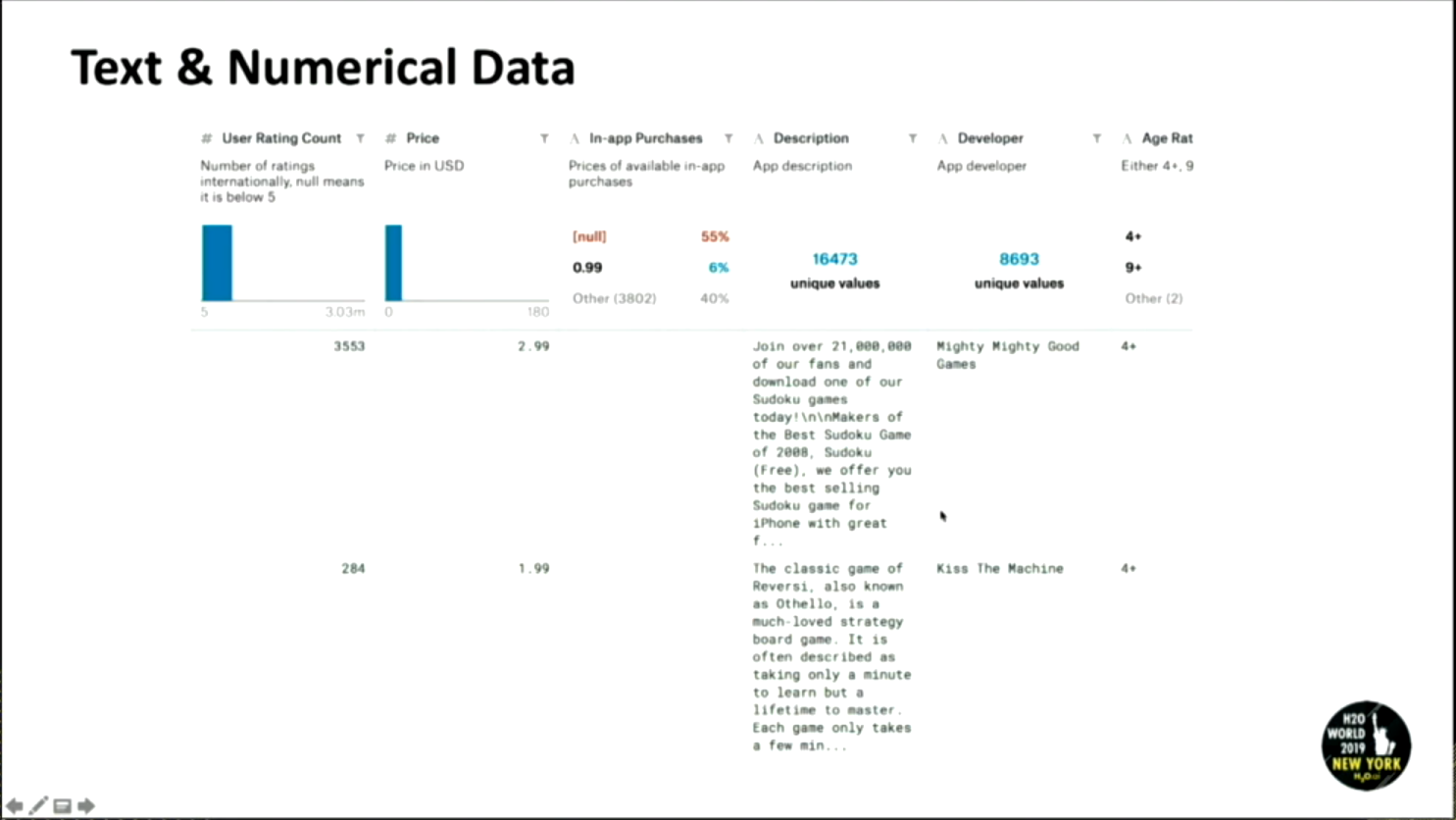
- Textual, Numerical Data
As you can see in this image, the data could have both numbers, alphabets and special characters.
Feature Transforms inside Driverless AI
- Count based:
For these, single words and n-grams are used.

2. TF-IDF :
The idea is to multiply the frequency of words and the inverse frequency documents to get a list of useful words.

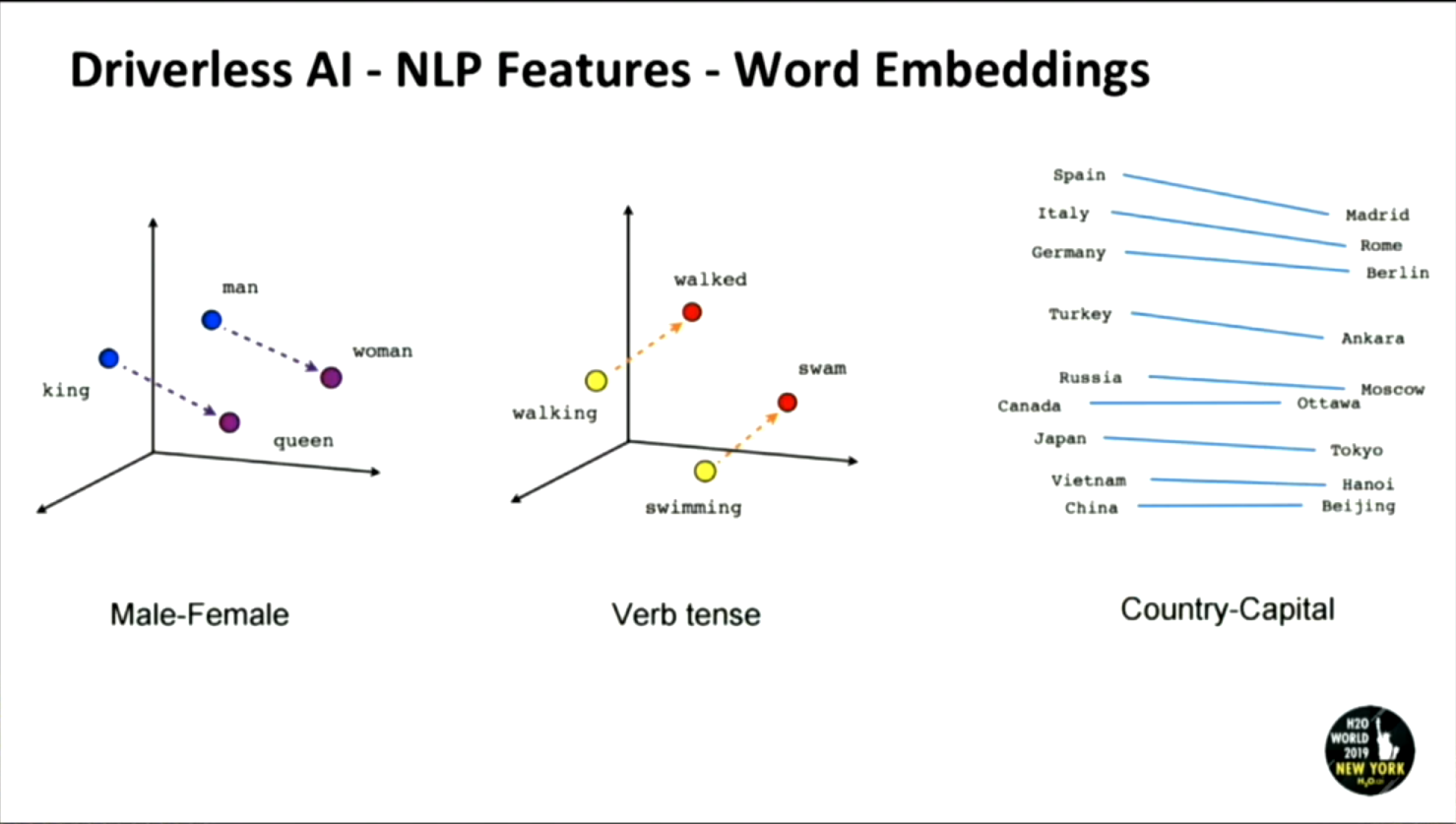
3. Word Embeddings:
This shine where semantics can be captured by representing words in higher dimensions, which may be missed by TF-IDF or Count based.
NLP Recipe for Feature Transformations
This image gives us a good overview of how different features are generated using DAI.
All of the feature engineering is handled inside of DAI, which means that many features would be created behind the scenes:
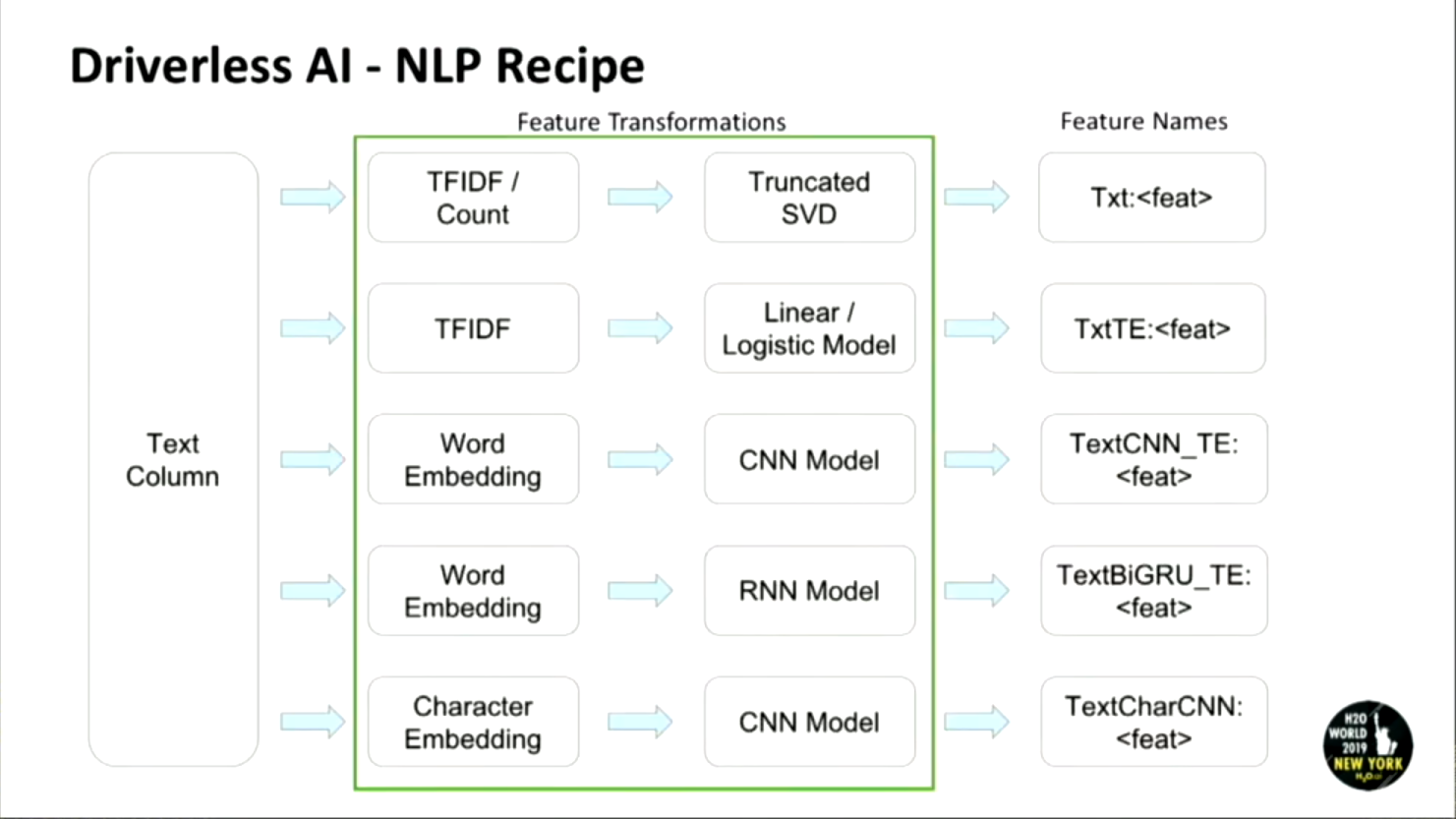
- Text features are generated by running the input through TFIDF/Count followed by a truncated SVD to convert the sparse matrix into a dense matrix.
- Similarly, the input is run through TF-IDF followed by linear/logistic regression to generate features.
- Different features can be generated by word embeddings being run through CNN/RNN models for ex: Bi-Directional GRU or TextCNN.
- For some language with lesser resources, character embeddings can be used to generate CharCNN features.
Driverless AI: NLP Recipe
- Features used in text classification are language agnostic.
- Pre-trained word embeddings can be used via expert settings.
- C++ MOJO available for deep learning models.
Custom Recipes
Custom Recipes allow you to bring your own recipe to Driverless AI or even use your own Recipe along with the existing ones.

A few recipes also exist, catering to quite a few use-cases:
- Text Preprocessing:
Text preprocessing is the first step in an NLP Pipeline. You could use these recipes and build on top of them:
– Stemming
– Lemmatization
– Stop word removal - Text Meta Features:
If you’d like to extract some meta-features from your text. The following are a few tasks that the recipes could cover for your pipeline:
– Number of words
– Number of characters
– Number of Unique words
– Number of uppercase words
– Number of numerics
– Number of punctuations
– Mean word length - Text Readability:
As the name suggests, if you’d like to score the readability of a text, the following features can be picked using Recipes:
– Syllable count
– Average syllables per word
– Flesch reading ease score
– Smog index - Text Sentiment:
You could get a sentiment score using a pre-trained model/package. - Language Detection
- Parts of Speech Features:
Following features can be generated using recipes:
– Noun count
– Verb count
– Adjective count - Text Summarization
- Topic Modelling
- Spelling Correction
Custom Models:
A few recipes, optimized and shipped as close source models are also available in DAI along with C++ MOJOs being developed.
Machine Learning Interpretability
This is an active area of research and DAI comes with a few features to allow you to interpret your models.
MLI in NLP is another feature that the team is working on and hoping to add it to a future release. More details on that later.
**
This was a quick overview of NLP with Driverless AI, if you’d like to find updates, I’d suggesting navigating to the website.







