







Introduction to H2O Document AI

Mark Landry, H2O.ai Director of Data Science and Product, and Kaggle Grandmasters showcases H2O Document AI during the Technical Track Sessions at H2O World Sydney 2022.
Mark Landry:
I’m Mark Landry, with some different titles than you see on the screen here. I’ve got a bunch at H2O, so I’ve been at H2O for about seven and a half years, doing a variety of roles. Speaking to you as a co-product owner of Document AI. I lead a data science team behind Document AI.
That’s what I’ve been doing, arguably for the last four years. We’ve had this product that’s pretty new to us, relatively new. We’ve had it and have been selling it for about a year, but it’s based on work that my team and I had done for about three years prior to that. Taking a lot of the learnings, productizing that, and that’s what I’m going to be talking about today. Yes, Kaggle grandmaster as well, and several others on this team.
We’ve got a lot of modern AI, and a lot of Kaggle robust knowledge going into this tool.
H2O Document AI: Overview
The first thing is, what is Document AI?
Our goal with this product? It’s a new space. You’ve got a lot of different companies doing it. I’ll talk a little bit about how we are different and what we do here.
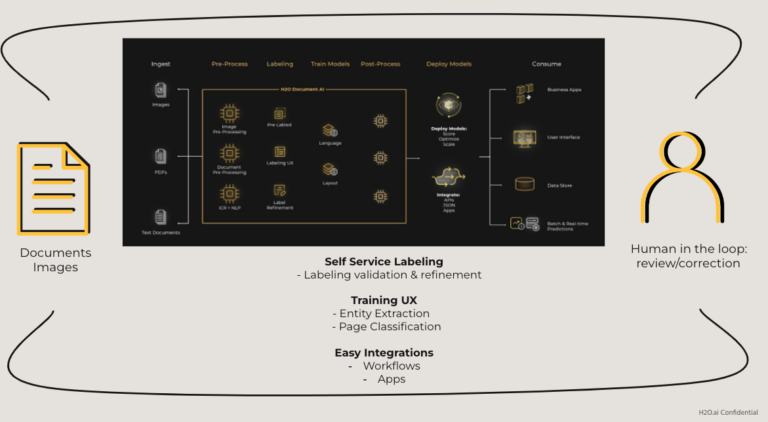
The main goal is extracting information from documents.
Really simple, kind of boring. When we first got this about four years ago, it was surprising that that’s a thing. What it really is we’re going after key information that businesses need. When you start hearing what this is, you find that businesses have lots of these processes going on. A lot of them are done manually. We’ve got a stack of documents. We’re going to scan those. We have someone keying them in. Sounds old-fashioned, but there’s a lot of those use cases out there.
I’ll talk about a few of those use cases, and that might jog your memory of things that you might know where these processes exist. For us specifically, as you might guess at this conference, we’re using AI to do it.
Modern AI, everything in this tool is recent. All the way up to this year, we’re creating our own. These models didn’t really exist even three years ago to do the way we’re doing right here.
There’s two basic components that go into reading these documents. We’ve got computer vision, and we’ve got natural language processing.
Computer vision comes in. You may be familiar with OCR, and the intelligent characteristic recognition we’re looking at can mean a few different things. We have lots of different OCR libraries, and we’re trying to use the right thing for the right job.
A lot of companies have PDFs where you can pretty much copy and paste the text. You don’t need to use computer vision in that case, and you’re going to have perfect accuracy if you can just extract that information correctly.
But you’d be surprised at how many PDFs have really crazy formats in there. It’s still not straightforward. There’s still ways to make mistakes. We take that in-house and then use a variety of OCR libraries, and we’ll let you choose. I’ll show that at the end of some of those.
That’s been a big focus of ours this year is to keep adding more and more OCR libraries that you can use. Different techniques, different languages, things like that.
For those of you that have seen Hydrogen Torch somewhere around here, we are using that in-house to actually further drive OCR models.So we are using Hydrogen Torch ourselves to build some of the component models of our OCR pipeline, which right now consists of three different models back to back to back to get that task done.
And then you move over to the natural language processing side. The character recognition is to see the text on those documents, and then we’re going to work with those in a natural language processing way.
With one exception: documents don’t always work in reading order. They don’t work left to right like reading the Gutenberg Bible and Wikipedia and a lot of the text that we’re training on with natural language processing models. Documents can be slightly different.
The way humans lay out documents winds up being concise. We don’t want to write a whole paragraph to say the due date is this. Maybe that is pretty simple, but we’re going to go really small. Sometimes we’ll have things on top of each other. Sometimes we’ll put cluster information on the left side. We’ve got tables, which is a really big part of Document AI really.
The models we use are custom for documents and that’s why I say they’re new. We’ve been processing these as text.
Some of you may have tried some of the existing libraries out there and struggled to work with it because it’s hard to work with the text. It’s just a bundle of text here. The location’s really important. The context is really important. We use models that understand that.
And, like the computer vision side, this is where we’ll be expanding as well. We use one workhorse model for those of you that are familiar, ALM is doing a lot of work here. This is an innovative space. There’s a lot of research papers. There’s one that came out in the summer that we’re really looking at that gives us different angles at this. And again, give more options to try almost like Rohan just said with H2O-3, that you don’t know which one’s going to be the best each time. So we are giving more options in our offering so that you can use the best one for your problem. Certain ones may focus on difficult dirty documents and our OCR has gotten much better in the last year at handling that stuff. We still have room to grow so we’re always working on that, trying to get it better and better at difficult documents, different things, wide documents, big documents, contracts, lots of different things out there.
Now our focus specifically is a little different from if you might have seen some other vendors out there. Some of the clouds are looking for general purpose document AI. You put a document in, it’s never seen that document or understands it, it’s just going to tell you what’s on there. There’s a use for that. A lot of people use table methods, so they’ll try to parse a generic table method, try to segment it to different parts, keys, and values, and things like that.
Ours is a little different from that in that we are going to look at a collection of documents that all support a specific use case. Custom for each use case’s needs. What that means is, I’ve got an example of an electricity bill that we’ll take a harder look at a little later. I’ve got a bunch of different electricity bills from different providers in Australia in there.
Each one’s slightly different in how they lay out the information. It’s all the same information. Humans are good at that. You figure out where the due date is, the customer, the address, they’re all there sometimes multiple times, sometimes on multiple pages. But for us, it’s important that they’re different because a lot of our customers don’t control the input source. They’re going to get it from all over the place. They’re not just going to process this one origin. It looks like an electricity bill, they need to process whatever comes through. Our models are going to use the NLP. They’re going to understand the nature of a due date and they’re going to understand the nature of a billing period begin and end even if there’s no text whatsoever, as I think this one does, up in the top middle right over there, it’s a little small I’m sure on the screen. But there’s no text telling you that that’s the beginning and the end date, none at all.
But once you get the hang of these documents, you realize that’s what that is. That’s what we’re going to teach our model and we want to show it as much variety as possible. The things that you’re going to extract from that document, you can notice in here, I’ve got a few bounding boxes over there. I’ve picked a pretty trivial one, there’s about five different things I’m pulling off of this one, pretty basic stuff. But that’s pretty typical. When you have to show a second form of ID, you need to open up a home loan. This is one of the documents you need to bring with you or one of the acceptable doc types of documents. We don’t need to understand the entire bill, but maybe a different customer does. We’ve seen this with something like invoices. The first use case we had with invoices, only about four pieces of information were relevant out of there. They just needed a total, they needed a couple of different things.
As we progress with our supply chain offering, different customers want different things out of there all the way to fine grain details. Now we’re extracting everything we know about the invoices and our understanding of that keeps improving at H2O. These models are customized to whatever our customers bring. I’ll show you a sample of use cases and they’re all over the board. Different types of contracts, and supply chain document statements like you see here. A statement is a statement to a certain extent, but they are different. All different things we can do.
Again, our focus is in allowing customers to fit the models that they need without being burdened by templates. The second one is models that generalize to new documents rather than memorizing keywords and the location of those templates.
That’s how a lot of these tools will work. Our first customer brought with us, they had been doing templates for two years. They had clicked on the specific regions of a hundred different template types, but it just kept coming and it was more and more diverse.
This is a physician referral form. They estimated that 60% of what came through after two years of trying to create a hundred different templates, they still only had 60% of the volume covered. The other 40%, they had no idea, nothing at all because it didn’t recognize it. The generalized understanding was able to do equally as well on new documents as it was the data it was trained on. Your mileage may vary on that and when you start small, but they started with all of that power of two years.
They were able to really quickly get similar accuracy on documents that had never been shown that template, and that specific format had never been seen by the model. That’s the key part here. We’re developing a generalized understanding using all the contexts. For those familiar, we’re basically using a BERT model extended to work with these documents with the locations. It’s a multimodal model. It takes the text and the coordinates of where each of those boxes are or the content of the OCR. That’s the model that we’re going to use to drive these. And again, as I said, there’s a couple of different models. This is really changing quickly. We’re going to stay on top of that and always be using the best model for it. That’s how this works. It extrapolates, it generalizes, that the idea is that we’re going to cover new documents we’ve never seen.
The product itself that we’ve built is a data science library underneath it that does these things in the focus item. A UI that is really intended to be easy to use. Our model training is very simple. There’s not many parameters to choose the OCR, it’s some quick dropdowns. We just really want to get it down to the basics of bringing your documents, and teach the model. We do have to create annotations and that’s a big part of what we’re doing here. A lot of people don’t have targets for these. They don’t know, they haven’t been tracking it. Some that had templates like that first vendor, they were able to bring everything they had in because they had been doing it in templates. That’s the last one we’ve seen like that everyone else is starting from scratch.
A lot of this tool is trying to help you go quickly through that task of teaching the model what the labels are. I’ll talk about that a little bit more too. The goal there is that we’re creating custom models. We’re gathering the training data, allowing you to annotate it so that we can create those models. Then the big part at the end is deploying pipelines for the end user consumption. We have a Rest API that wraps up a pipeline and that’s a keyword here because it’s not just models. You heard us say three OCR models. Customers often have one or two classification models. Sometimes they’re classifying what a page is first and then going after the contents of that page. The same models are going to look at all the text on there. They’re going to see in big chunks, hundreds of tokens at a time to classify what that document is.
The same for the classification of all the tokens, but the end user consumption. Typically for these use cases, again, these are a line of business teams very frequently. People that are already doing these jobs get an email queue, download the attachment, check it against a second source, and agree whether it’s correct or send it on its way to a different pipeline. In those things, our Rest API can do the same thing. They can automatically extract the document, send us a document, send the document to us, to our Rest API post one, let the machine learning models work the entire pipeline and at the end of the day they’re going to pull out all the specific pieces of information that they wanted.
With purchase order confirmations, that is exactly that. There’s a person sitting there downloading attachments, checking against another system. They’re looking at about 30 different items from those invoices. With invoices, you have multiple different line items. Could be a 10-page purchase order. A purchase order may have 10-pages worth of items, and we would need to extract them all. In their use case, they’re checking every single thing on there, checking what they believe that was supposed to be in that order. If everything checks out, they’ll remove it from the queue. If not, they send it to somebody to work. Really simple. We can take out a lot of manual effort anytime that those match.
H2O Document AI Use Case Examples
The next one I’m going to show is some of these use cases, and I’ve broken them down to a little bit of what I just hinted at. I would call that where they’re ingesting a document and checking it as an alternative source as the validation type. We’re able to validate A and B, and there’s two different systems, and that might sound rare, but it really isn’t. We actually have the majority of our use cases there. It’s a really easy way to deploy AI because one of the key things we do have to talk about is models.

Models make mistakes, humans make mistakes, but these models are going to make mistakes as well. You can make the mistake in the OCR portion, the classification portion. We need to be sure that we’re robust to those. That’s sort of working with the clients. We have some confidence scores that are coming through, and people look at that. There’s additional validations that people can use to try and increase their confidence so that you minimize the human effort. Does a human need to look at it at all? In the robotic process automation world, this is usually called straight-through processing, STP for short.
It’s a really tricky thing. If you’re validating something, it’s much easier. Those use cases are really easy to stand up to. Usually, the people working those when we have an incumbent process sometimes it’s something someone’s never been able to try more often, it’s something someone’s tried, they just want additional efficiency. Those people are really happy to get these models in there, helping them get through the easy stuff. Sometimes it’s a lot of documents, some of these are easy tasks, and some of them are pretty hard. A lot of the easy ones are still, it’s a good place for these models because it’s so boring to check and translate and do whatever people are doing today. We have all different kinds of use cases with a lot of menial tasks.
This is a great way to use complex algorithms, which is why some people have been doing this for a while, but a lot of these documents are just a little too hard. The OCR is difficult. The AI, when everything changes, trying to write business rules to cover a hundred thousand different formats is just intractable. Getting these models to generalize is new stuff, and it’s really powerful.
Different industries here, you see a lot of supply chain, we’re seeing a lot of that. So similar kind of content passed through the pipeline, starting with a contract, purchase orders, invoices, shipping receipts, and things like that.
Example Walkthrough
Now I’m going to show you a little bit about what it looks like. This is the front end of our tool. I’m skipping all the way to the back, so I’ll back this up a little bit, but just showing you really where we land at the end. At the end here, I’ve got my document in the middle, and I’ve got a queue of documents. You can see a little bit on the left side, and it’s small up there. Let me see if I can make it bigger and now make the document. What we’re doing, we’ve got documents. I’m going to move to the right. We’re going through this queue of documents, and the documents are changing a little bit. We have a lot of the common ones here. It’s not all that diverse, but in a real use case, they typically are. You’re going to see the common ones. The 80-20 rule often is true of some of these. We’re finding the same content. To be honest, it is laid out pretty similarly in each of these different vendors.
Here what we’re doing is I’m simulating a pipeline that’s been run, and we’re producing what the answer is. We’ve got a few of the different things we’re looking for. The customer name it’s not quite laid out, left to right, but we’ve got the text directly. We’ve asked the model to classify each of those tokens. At the end of the day, we want to put those together to be human readable. The customer’s name is Mr. Amit Kumar. The label is confidence, the model’s pretty confident about this 99.4%. The OCR is also confident about this one very clean document. Not all the documents are clean, for sure. I might show one of those if we have time at the end. We can roll through these, and we can see really what we’re trying to get at.
The address, here it is, and this is editable. This is something we’re working on too, giving the final state so that if there was a mistake, I don’t believe there are any of these, I can just override it this way. I can change the customer address to be something different. The same interface applies here. You see all of the different types of things that we’re bringing back. This is customizable as well. These are the common things we’re usually getting from people.
For example, if I had a table, we also want to see the lines that they’re tied together that this quantity goes with, this amount goes with this tax amount and item ID, and so forth. I have a little bit extra that groups things together so people can see it more naturally.
You can see that this also is a labeling tool. I don’t need it for this use case if I’m checking out at the end. But what we have here is a powerful interface that allows people to annotate in the first place.
Let me show you what that would look like. These are going to be, I think it’s this one that has different documents. So when we start with documents, we can customize our classes, which you’ve already seen with their AR, but here I can add another one if I want to. All of a sudden, zoom it in so you can see it, if I want to start going after more information, I can go after my new class here. This is an interactive labeler, and an annotator easy to use, but this is really key. We are looking at documents all the time. Documents are very visual, and so it’s just a natural thing for us to make this sort of front and center.
I haven’t shown you too much of the UI at this point, but this is how we’re going to record and teach the model what we need. It’s a lot of thinking about what we want from this. Usually, customers know from the start what they want to try. We might have to iterate a couple of times on some of the classes, and they might notice there’s a couple of different things they want to split out. There’s a little bit of iteration here, but most of the time, we’re going to set up our classes and start teaching the model what it is. These are going to be similar documents that you’ve seen before, maybe a few different vendors. I’m going after these, and you can see the other part of the label.
We can actually shift what we show here as well. We can remove the boxes, add the boxes, remove the labels, add the labels, or change them. Change what we’re seeing here. Right now, we don’t have text on the screen, but we could change the colors. A lot of things to help people recognize quickly go after and annotate these. It’s pretty easy when you get the hang of it to annotate the data. That’s because that’s one of the burdens of getting these started. The powerful thing here is that while we annotate with this same tool like I showed you before, we can keep using that same tool to add new annotations after we have a model that’s done a decent job. A common way of iterating a data set is to get maybe a hundred documents labeled or 50 or something like that, depending on how easy.
This one’s pretty easy. I am already at a pretty high accuracy with just 20 or something like that. Documents in there, create a model, and then use that model to predict against new data. If I were to upload a second data set of another hundred documents, I can immediately score it, get the model’s opinion and in certain cases, in many cases, it’s faster to change what the model did. Use the model for everything it’s good at already and just tweak it, and we can use the same interface. It’s really familiar to just keep using the same thing to keep adjusting boxes. If this was a prediction of an address, which is fine, but if I thought it was the date, it’s really easy to just change those and spot check it. We put a lot of thought into trying to make this as easy as possible because I can run models iteratively, keep training models and score against new data and use this same interface.
Model Against Electricity Bill
I’m just going to show you one more thing on the one that has accuracy. Here we go. In talking about the models a little bit, but to show, here’s how we look at things as well. This is a model I ran against 18 of those electricity bills and gas bills, the utility bills I guess we’d say. We’re performing classification. We’re doing it on every single token. Our support over here is how many tokens we’re going to each class. We’ve got a macro about our whole data set up top, and then here we have each of the classes. This is usually where we spend our time when we iterate with customers or ourselves trying to stand some of these up early on both ways. It’s already pretty accurate. We can see the F1 score here. Our precision and recall are pretty transparent about what it is.
This imbalance of 17 versus 73 is not much of a deal. Sometimes we’re fighting things where the customer has only five examples of a certain class they’re interested in. The models are very robust to that class imbalance. When they train quickly, you’ll see them go after the ones that are heavy, but you just need to keep adding data and get them more examples so it can really start to understand the nature of these. These are the tools the data scientists really want to push down to almost like a data analyst level, and can use to see where the model’s at. A lot of times, what I would say, more often than not at this stage, what we’re really doing when we look at these confusion matrices is seeing how accurate the labels themselves are. The annotations.
It’s kind of tricky. There’s different policies, almost. Do we label it everywhere we see it, or do we label it in the key location? Do we need to split things? Inconsistency among labeling approaches is something that’s just kind of natural for this, and I think it probably will be in all sorts of Hydrogen Torch as well with Label Genie for those that have seen it. If you give it to three different people, most of what I’ve picked here is probably going to be pretty common. But even that, sometimes there’s a due date next to a deposit date, and often the deposit date is absent the due date is the due date. Sometimes they’re both listed. What’s the strategy about picking those?
I would say it’s as common to look at this confusion matrix to think of a judgment of “where have I put inconsistency into the training data?” At that point is to look at the consistency of it with some specific targets. You can find your confusion matrix here. You can see what is commonly being classed as something different. Customer address, the most common thing is happening is it is not picking it up. Maybe it’s leaving a last token or a front token. That’s natural. I don’t see any right here actually. The due date is, that’s the other way. Same sort of thing. It’s struggling a little bit with whether it needs to go in or out, but we’ll commonly find classes that two different things are interchangeable, so a confusion matrix can help point that out. You go in armed with that information going through there and looking to see if we need to clean up our data set. I would say in-house at H2O it’s probably two plus times through a data set to annotate, even on ones where we only do like maybe 50 documents or something like that. Trying to give everyone the tools so that they can do that themselves. The actual model training is very simple.
Document Sets
This is hinting at the UI, I haven’t really talked about it too much, but a pretty simple organization here. We’ve got different projects. I’ve got quite a lot in this test environment, but document sets. I’ve imported two different document sets. One for my training, and one for my testing, which I could have split separately, just happened to do it this way. Mostly documents as data, annotation sets, kind of a new term. I don’t know that anybody else uses that, but this is where the documents really become data. We can store lots of different things: our labels, our predictions, our OCR output, and all the different things that essentially get tacked onto that input data, which we show as images. A lot of times, they come in as a PDF. I haven’t talked about that too much, but that’s the most common way we get things. Paginating those PDFs, representing them as images on the screen, and then attaching all these attributes to them. We have a lot of different things.
As you get the hang of your own project, knowing one of these from the other and just managing that data through trying something else, trying maybe a different OCR library if you didn’t like the one you tried at first. Or if you need something different or try a different model. Adding data to the model. That’s more of the thing. Incrementally growing your models over time.
I’ve only got one model here. Those are pretty straightforward jobs you can track. Everything that’s happening. These are deployed in Kubernetes, and that’s key for the jobs and the published pipelines. I’ve got GPU instances connected to this. You can do CPUs or GPUs.
Publishing Pipelines
These are heavy Deep Learning models. It can take a little while if you do it on CPUs. But you can if you want to. The pipelines are the more important thing. Most of what we’re doing, while we’re looking at all this, is getting a model ready for end-user consumption. Perhaps someone has no idea what a model is, they just give me the answers, and I’m going to work it, or I’m going to review it, whatever that is, and the different pipelines, or maybe it’s an API that’s just going to go, like we said, checking in different data source and moving things along. This published pipeline once I have a model, I can create a pipeline, and at that point, I can lock in my OCR method. These are growing. Our dev version has seven of these already. We’ve got a lot of new stuff coming in our new releases.
Pick my model. This is the one that I picked, and then you’ll see I can name it. There’s post-processing. We have a couple of different post processes that are common to what people pick, but you can also add your own if there’s some custom thing you want to do. We’ve got some Python code that you can add. Then here, you get to some of the clusters. The clusters at the scoring time are really important. How do you want to optimize this? This is Kubernetes enabled as well, typically on CPUs here. You can use GPS as well, but we’re going to spread horizontally. Different documents, as we get a queue and fill it up, we’re going to let Kubernetes distribute those on the cluster. You can size your cluster here, and we resize it if you need to.
We’ll take in a queue of documents. We’re working on batch loading a bunch as well. Distributing those on all the worker nodes, each one accepts a document in, processes that entire pipeline, all the pieces that we just stipulated there of the OCR method and also the models. I could have put two models in there. I don’t have both models, but getting the output out in the form of a Json at the end of the day. Again, it’s really simple.
I can publish this in a couple of minutes. I’ve got one of these; here’s my published pipeline. Let me just show you what this looks like. Yes, I got one of those just a little bit ago. This is what it looks like on the outside. We have a simple Json format that we’re going to see what page we’re on. We’re going to see a little bit of OCR information. Here’s more of what we’re looking for. Here’s the customer address, here’s our confidence. There’s no line ID on this one. You’ve got a key value store here. The customer address is the class, the value is the text here, and we just rolled through all the predictions this way. You can manipulate those however you want, and you usually plug it directly in. We have a lot of customers turning them into a simple CSV and consuming it that way. But that’s our general idea. We’re going to produce one of these Json objects again, which you can customize. There’s more options than we see here, but process it, carry on its way and get it into the user’s hands.








