
Enhancing H2O Model Validation App with h2oGPT Integration

As machine learning practitioners, we’re always on the lookout for innovative ways to streamline and enhance our processes. What if we could integrate the power of language models into our workflows, especially in the critical phase of model validation? Imagine running validation procedures, interpreting results, or even troubleshooting issues through intuitive, natural language interactions. In this blog post, we delve into the practicality of integrating h2oGPT with the H2O Model Validation application, unraveling its potential to simplify tasks, enhance user experience, and accelerate our machine learning tasks. This post highlights our progress and the exciting possibilities this integration brings.
H2O Model Validation
H2O Model Validation is an application that lets you assess the robustness and stability of trained H2O Driverless AI (DAI) models. With this app, you can prevent model degradation by performing various validation tests that identify weaknesses and vulnerabilities in your datasets and models. The app allows you to fine-tune test parameters using available configuration settings and provides detailed metrics through graphs, charts, and heatmaps. The application includes various tests such as adversarial similarity, backtesting, drift detection, size dependency, calibration score, and segment performance.
h2oGPT
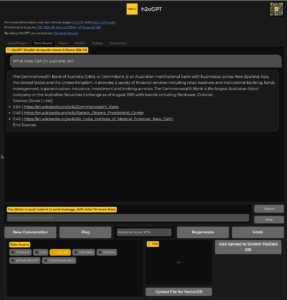
h2oGPT , is a Large language model (LLM) from the team at H2O.ai that not only excels in performance but is also fully open-source and commercially usable, providing a valuable resource for developers, researchers, and organizations worldwide.
Integrating h2oGPT with H2O Model Validation App
The H2O Model Validation application conducts tests to evaluate model stability and robustness, utilizing statistical approaches and machine learning algorithms, often incorporating advanced techniques. By integrating h2oGPT, we harness the capabilities of Language Learning Models (LLMs) to generate automated insights within the app. This enables users to receive simplified textual summaries facilitating better understanding. Moreover, these explanations serve as valuable resources for non-technical stakeholders seeking to comprehend validation test results without repetitive documentation review.
Here are some specific ways by which users can make use of this functionality :
- Simplified interpretation: The results of these tests can be complex for non-technical users. Explanations provide context and interpretation, making the results more understandable.
- Time and effort savings: h2oGPT automatically generates explanations for validation results, reducing the time and effort required for interpretation.
- Effective communication: Explanations help non-technical stakeholders communicate with technical stakeholders about models. Understanding validation results and their implications facilitate productive discussions aligned with business goals for enhancing model robustness and stability.
Unlocking Insights with h2oGPT
To demonstrate the capabilities of the integration, let’s look at how we can easily obtain insights using the h2ogpt-512–20b model. These insights cover datasets, models, and drift detection tests.
Dataset Insights
With the integration of h2oGPT, the H2O Model Validation app can efficiently generate an overview of the dataset. This overview encompasses key details like the dataset’s size and recommendations for the most appropriate models based on the dataset and use case. As an example, For instance, let’s explore the autogenerated insights for the KC house dataset from Kaggle .
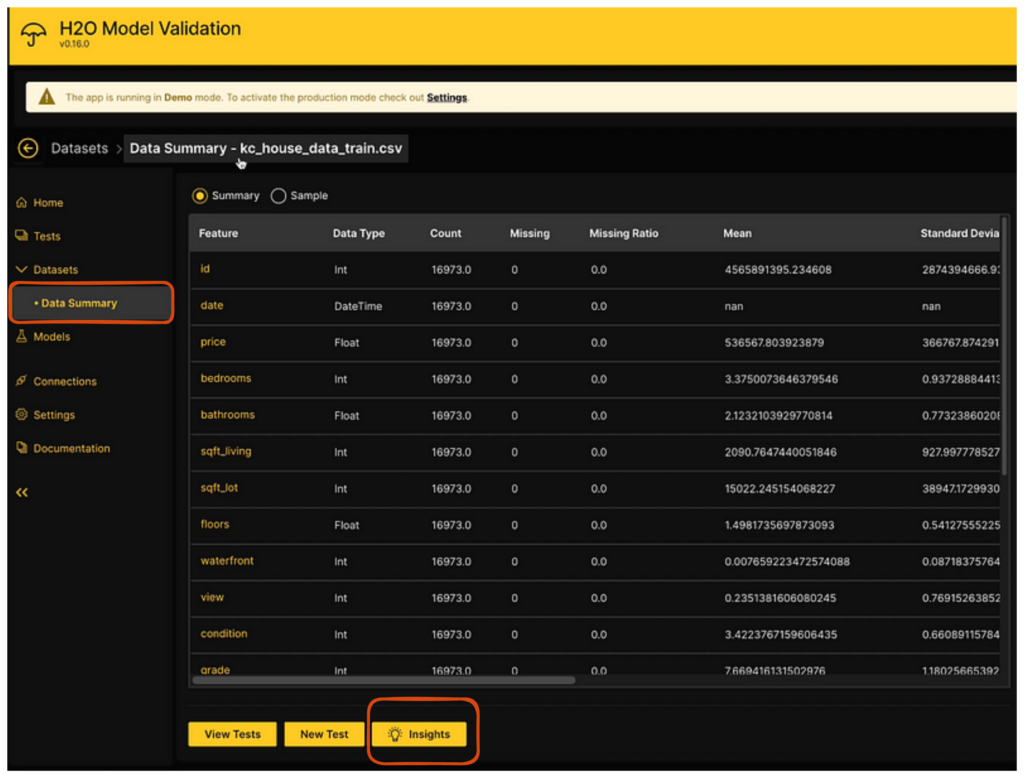
While the model validation app offers a summary with various metrics, h2oGPT takes it further. By clicking the insights  button, a new popup window emerges, providing real-time insights and a concise summary of the dataset, its features, and suitable models.
button, a new popup window emerges, providing real-time insights and a concise summary of the dataset, its features, and suitable models.
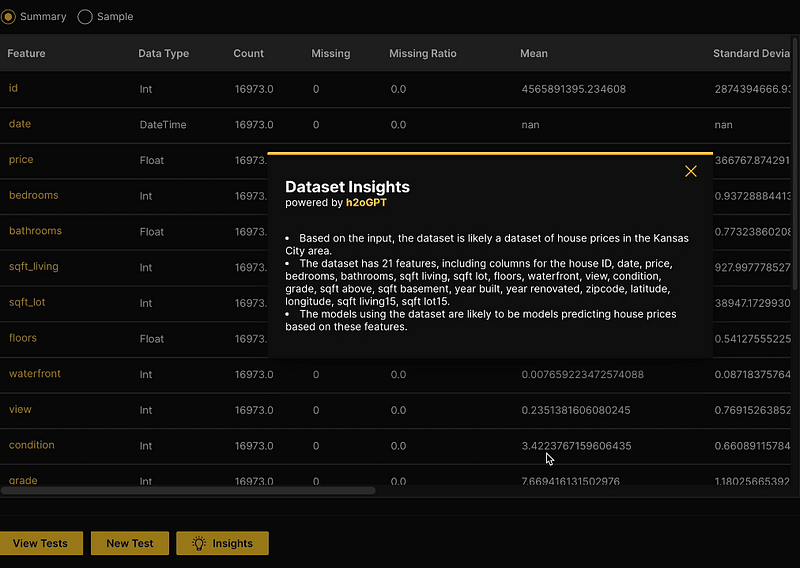
An interesting observation pertains to h2oGPT’s ability to infer a dataset’s domain solely by examining its columns and the dataset’s name. For instance, for the given dataset, it may not be immediately apparent that “KC” stands for Kansas City, but this fact nicely emerged through the insights gleaned from the data. The same applies to the column names. For example, columns labeled ‘lat’ and ‘long’ were adeptly expanded to ‘latitude’ and ‘longitude’ in the insights provided, illustrating the model’s ability to intuitively understand abbreviations. This feature is incredibly useful for individuals approaching the dataset for the first time, enabling them to quickly infer the meanings behind the data.
Model Insights
In H2O Model Validation, imported models include a comprehensive model summary that provides an overview of the model’s performance. The summary includes metrics such as important features, scorer, validation score, and more, extracted from the model and accessible within the H2O Model Validation framework.
The following image shows the model summary for a model trained on the Australian weather dataset , where the goal is to predict whether it will rain the next day based on the given features.
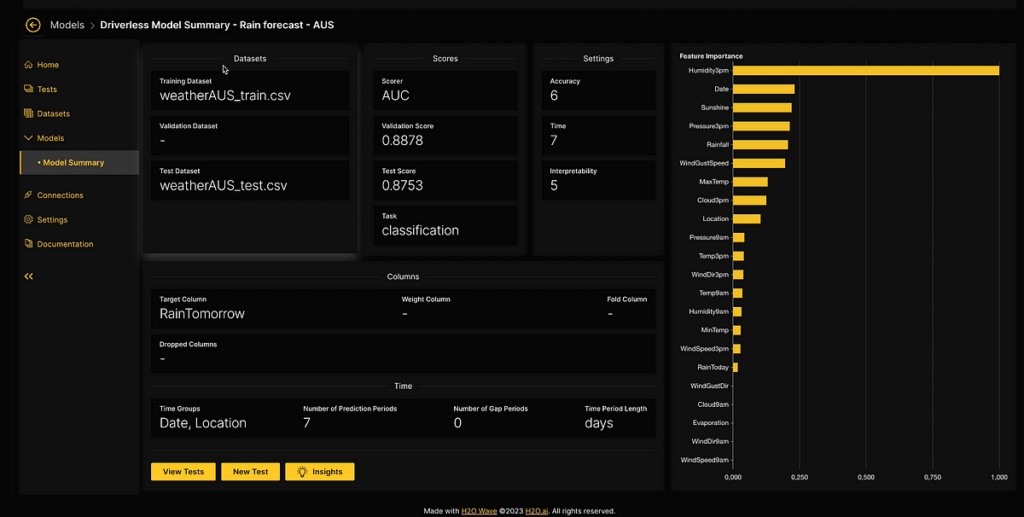
Similar to the previous section, clicking the insights tab generates consolidated insights based on the above metrics.

The generated insights provide a comprehensive explanation of each metric and its corresponding values, aiding users in making informed decisions. For example, users can easily comprehend that the target column represents the predicted probability and understand the significance of high feature importance. This facilitates sharing findings with others or incorporating them into reports seamlessly.
Drifts Insights
Drift detection is one of the many validation tests offered by H2O Model Validation to analyze the robustness and stability of a model or dataset. A drift detection test enables the detection of shifts in the distribution of variables within the model’s input data, helping you to proactively prevent any decline in model performance. H2O Model Validation employs drift detection by comparing the training dataset with another dataset collected at a different time to evaluate changes in data distribution over time. The population stability index (PSI) formula is utilized to quantify the extent of distribution shifts for each variable.
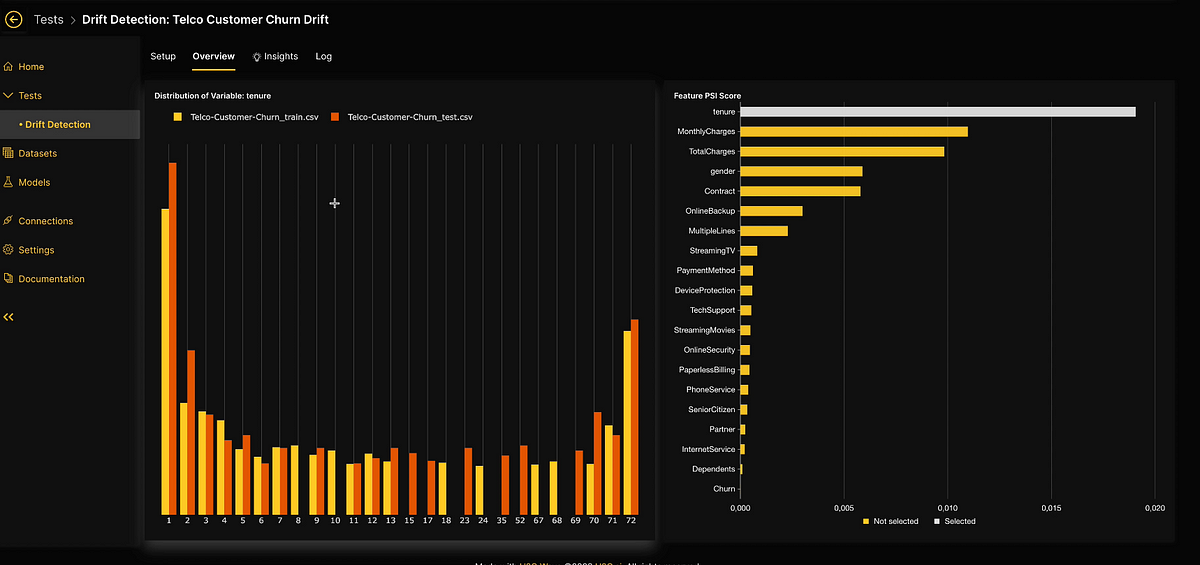
The image above showcases the Telco Churn use case, which involves predicting customer churn in the telecommunications industry to proactively identify at-risk customers and take appropriate retention actions. On the right side, the chart displays the dataset features ordered by their population stability index (PSI) values, ranging from highest to lowest. Meanwhile, the left-side histogram illustrates the distribution values of the selected feature, specifically tenure, revealing insights into population shifts over time. By analyzing the PSI values for each histogram bin, we can detect significant distribution changes, indicating potential shifts or discrepancies between old and new datasets. Let’s explore how we can leverage h2oGPT to further enhance this use case.
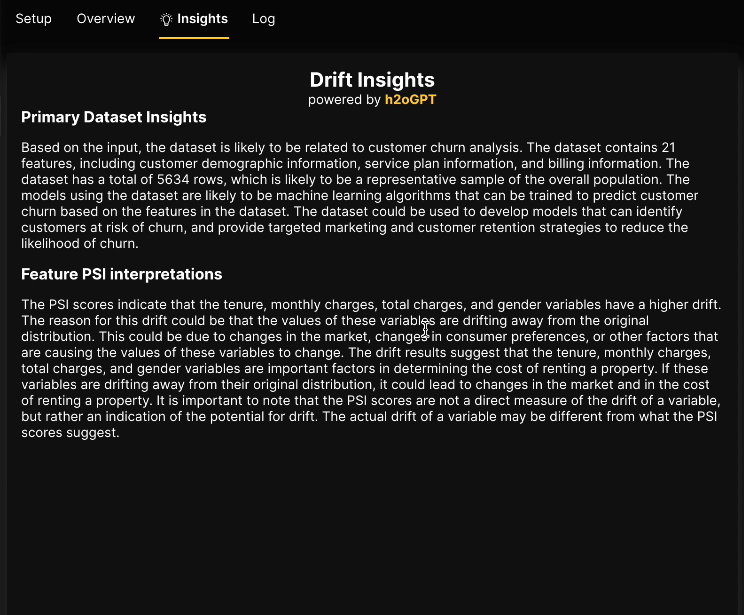
The obtained insights not only provide valuable information about observed changes in the variables but also offer plausible explanations for drift, such as market changes or shifts in consumer preferences, which can impact property rental costs. These insights are highly beneficial for data scientists, enabling them to make informed decisions about the model and the dataset.
Conclusion
While this marks a promising beginning, our efforts to enhance the H2O Model Validation application are ongoing. By integrating the model validation capabilities with the language understanding and generation features of h2oGPT, users can unlock a more interactive, accessible, and efficient model validation process. For more information, visit h2oGPT GitHub page, H2O.ai’s Hugging Face page and H2O LLM Studio GitHub page. For discussions, queries, or simply hanging out, we invite you to join our Discord community! 