







How Driverless AI Prevents Overfitting and Leakage
By Marios Michailidis , Competitive Data Scientist, H2O.ai
In this post, I’ll provide an overview of overfitting, k-fold cross-validation, and leakage. I’ll also explain how Driverless AI avoids overfitting and leakage.
An Introduction to Overfitting
A common pitfall that causes machine learning models to fail when tested in a real-world environment is overfitting. In Driverless AI , we take special measures in various stages of the modeling process to ensure that overfitting is prevented and that all models produced are generalizable and give consistent results on test data.
Before highlighting the different measures used to prevent overfitting within Driverless AI, we should first define overfitting. According to Oxford Dictionaries , it is the production of an analysis which corresponds too closely or exactly to a particular set of data, and may therefore fail to fit additional data or predict future observations reliably . Overfitting is often explained in connection with two other terms, namely bias and variance. Consider the following diagram that shows how typically the training and test errors “move” throughout the modeling process.
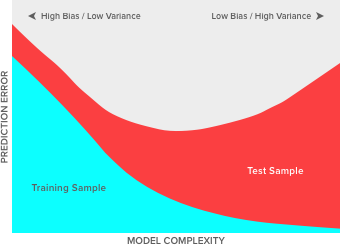
When an algorithm starts learning from the data, any relationships found are (still) basic and simple. You could see in the top left of the chart that both errors, training (teal) and test (red) are quite high because the model has not yet uncovered much information about the data and makes basic/biased (and quite erroneous) assumptions. These basic/simple assumptions cause high errors due to (high) bias. At this point, the model is not sensitive to fluctuations in the training data because the logic of the model is still very simple. This low sensitivity to fluctuations is often referred to as having low variance. This whole initial stage can be described as underfitting , a state in the modeling process that causes errors because the model is still very basic and does not live up to its potential. This state is not deemed as serious as overfitting because it sits at the beginning of the modeling process and generally the modeler (often greedily) tries to maximize performance ending up overdoing it.
As the model keeps learning, the training error decreases, as well as, the error for the test data. That is because the relationships found in the training data are still significant and generalizable. However, after a while, even though the training error keeps decreasing at a fast pace, the test error does not follow. The algorithm has exhausted all significant information from within the training data and starts modeling noise. This state where the training error keeps decreasing, but the test error is becoming worse (increases), is called overfitting – the model is learning more than it should and it is sensitive to tiny fluctuations in the training data, hence characterized by high variance. Ideally, the learning process needs to stop at the point where the red line is at its lowest or optimal point, somewhere in the middle of the graph. How quickly or slowly this point comes depends on various factors.
In order to get the most out of your predictions, it becomes imperative to control overfitting and underfitting. Since Driverless AI thrives in making very predictive models, it has built-in measures to control overfitting and underfitting. These methods will be analyzed in the following sections.
This section includes both existing and upcoming features.
Check similarity of train and test datasets
This step is conditional upon providing a test dataset which is not always the case. If a test dataset is provided during the training procedure, various checks take place to ensure that the training set is consistent with the test set. This happens both at a univariate level and global level. At a univariate level, the distribution of each variable in the training data is checked against the equivalent one in the test data. If a big difference is detected, the column is omitted and a warning message is displayed.
To illustrate the problem, imagine having a variable that measures the age in years for some customers. If the distribution for train and test data resembles the one below, even a very basic model would start to overfit very quickly.
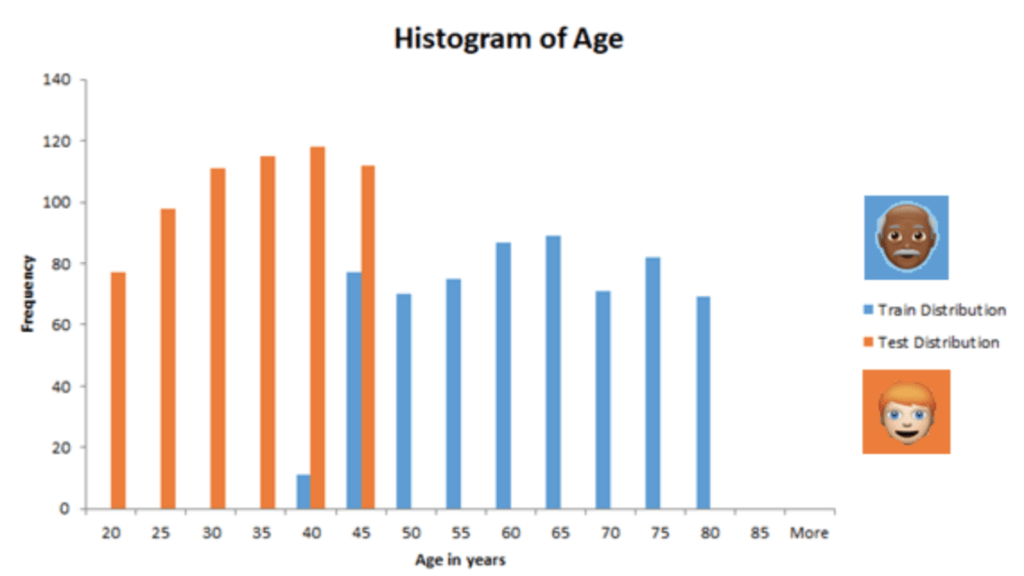
This happens because the model will assume that a given customer will be between 40 and 85 years old. However, that model is tasked to make predictions for customers that are much younger. This model would most probably fail to generalize well in the test data and the more the model will rely on age, the worse the performance will be for the test data.
To detect this problem, Driverless AI would fit models to determine if certain values for some features have a tendency to appear more in train or in test data. If such relationships are found and deemed significant, the feature is omitted and/or a warning message is displayed to alert the user about this discrepancy.
K-Fold Cross-Validation
Depending on the accuracy and speed settings selected in Driverless AI before the experiment is run, the training data will be split into multiple train and validation pairs and Driverless AI will try to find that optimal point (mentioned in the top section) for the validation data in order to stop the learning process. This method can be illustrated below for K=4.
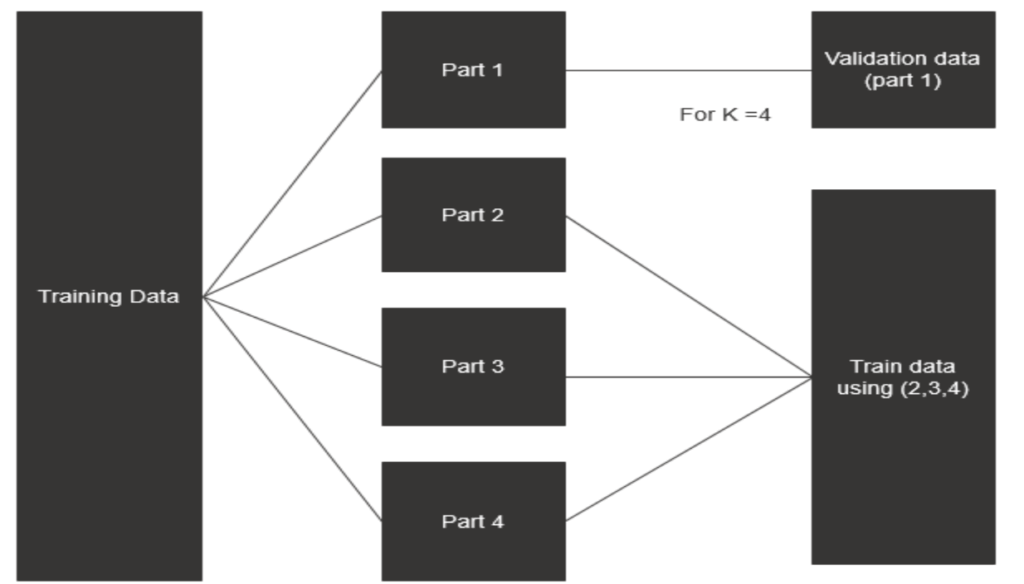
This process gets repeated 4 times (if K=4) and K models are run until all parts become validated exactly once. The same model parameters are applied to all these processes and an overall (average) error is estimated for all parts’ predictions to ensure that any model built with such parameters (features, hyperparameters, model types) will generalize well in any (unseen) test dataset.
More specifically based on the average error on all these validation predictions, Driverless AI will determine:
- When to stop the learning process. Driverless AI primarily uses XGBoost which requires various iterations to reach the optimal point and the multiple validation datasets facilitate in finding that global best generalizable point that works well in all validation parts.
- Which hyperparameter values to change/tune. XGBoost has a long list of parameters which control different elements in the modeling process. For instance, based on performance in the validation data, the best learning rate, maximum depth, leaf size, and growing policy are found and help achieve a better generalization error in test data.
- Which features or feature transformations to use. Driverless AI’s strong performance comes from its feature engineering pipeline. Typically thousands of features will be explored during the training process, but only a minority of them will be useful eventually. The performance of validation data, once again defines which of the generated features are worth keeping and which need to be discarded.
- Which models to ensemble and which weights to use. Driverless AI uses an exhaustive process to find the best linear weights to combine multiple different models (trained with different parameters) and gets better results in unseen data.
Check for IID
A common pitfall that causes overfitting is when a dataset contains temporal elements and the observations (samples) are not Independent and Identically Distributed (IID). In the case of temporal elements, consider having future data predicting past data and not the other way around, as that prediction is misleading.
DAI can determine the presence of non-IID easily if a date field or equivalent is provided. In this instance, it will assess how strong the temporal elements are and whether the target variables values significantly change for different periods in the date field. It uses correlation , serial correlation checks and variable binning to determine if and how strong these temporal elements are. It should be noted that this check is extended to the ordering of the dataset too. Sometimes the data itself may be ordered in a way that it does not help if the validation is formulated randomly. For example, if the data is sorted by date/time, even though that field is not provided.
If non-IID is detected, Driverless AI typically switches to time series based validation mode to get more consistent errors when predicting the test (further) data. The difference with the k-fold (mentioned above) is that the data is split based on date/time and all pairs of train,validation are formulated so that train is in the past and validation is in the future. The type of features Driverless AI will generate are different than when there is IID. This process also identifies main entities that will be used for both validation and feature engineering . The entities are the group-by categorical features such as stores or type of products that if used make predictions better – ex: sales by store and product in last 30 days.
As a summary of this subsection, this check is put in place to ensure that Driverless AI performs feature engineering, selects parameters and ensembles models in a way that best resembles reality when strong temporal elements are detected.
Avoiding Leakage in Feature Engineering
Leakage can be defined as the creation of unexpected additional information in the training data, allowing a model or machine learning algorithm to make unrealistically good predictions . It has various types and causes. Driverless AI is particularly careful with a type of leakage that can arise when implementing target (mean or likelihood) encoding . In many occasions, these type of features tend to be the most predictive inputs, especially when high cardinality categorical variable (as in with many distinct values) are present in the data. However, over-reliance on these features can cause a model to overfit quickly. These features may be created differently in different domains – for example in banking they take the form of weights of evidence , in times series they are the past mean values of the target variable given certain lags and so on.
A common cause that makes target encoding fail is when predicting an observation/entry that its target value was included for the formulation of an average value for a certain category. For example, let’s assume there is a dataset that contains a categorical variable called profession and various job titles are listed like ‘doctor’, ‘teacher’, ‘policeman’, etc. Out of all of the mentioned entries, there is only one entry for ‘entrepreneur’ and that entry has an income of $3,000,000,000. When estimating the average income for all ‘entrepreneurs’, it will be $3,000,000,000, as there is only one ‘entrepreneur’. If a new variable is created that measures the average income of a profession, while trying to predict income, it will create the connection that the average salary of an entrepreneur is $3,000,000,000. Given how big this value is, it is likely to make a model over-rely on this connection and predict high values for all entrepreneurs.
This can be referred to as target leakage because it uses the target value directly as a feature. There are various ways to mitigate the impact of this type of leakage, like estimating averages only when there is a significant number of cases for one category. Ideally though, the average values need to be created with data that the entries’ features have not used in any way as their respective target values. A way to achieve this is to have another holdout dataset that is used to estimate the mean target values for certain categories and then apply these to the train and validation data – in other words, have a third dataset dedicated to target encoding.
The latter approach suffers from the fact that the model will then need to be built with significantly less data, as some part is surrendered to estimate the averages per category. To counter this, Driverless AI uses a CCV or Cross-Cross-Validation, or cross-validation inside a cross-validation. After a train and validation pair has been determined, then only the train part is undergoing another k-fold procedure where K-1 parts are used to estimate average target values for the selected categories and apply those to the Kth part until the train dataset has its mean (target) values estimated in k batches. They can be applied at the same time to the outer valid dataset, taking an average of all the K-folds’ mean values.
The same type of leakage can also be found in metamodeling. For more information on this topic, enjoy this video , in which Kaggle Grandmaster, Mathias Müller , discusses this and other types of leakage, including how they get created and prevented.
In regards to other types of leakage, Driverless AI will throw warning messages if some features are strongly correlated with the target but typically does not take any additional action by itself unless the correlation is perfect.
Other means to avoid overfitting
There are various other mechanisms, tools or approaches in Driverless AI that help prevent overfitting:
- Bagging (or Randomized Averaging): When the time comes for final predictions, Driverless AI will run multiple models with slightly different parameters and aggregate the results. This ensures that the final prediction, which is based on multiple models, is not too attached to the original data exactly due to this imputed randomness and produced of (to-some-extend) uncorrelated models. In other words, bagging has the ability to reduce the variance without changing the bias.
- Dimensionality reduction: Although Driverless AI generates many features, it will also employ techniques such as SVD or PCA to minimize the features’ expansion when encountering high cardinality categorical features and simplifying the modeling process.
- Feature pruning: Driverless AI can get a measure of how important a feature is to the model. Features that tend to add very little to the prediction are likely to just be noise and are therefore discarded.
Examples of Consistency
It is no secret that we like to test drive Driverless AI in competitive environments such as Kaggle , Analytics Vidhya , and CrowdANALYTIX to know how it fares compared to some of the best data scientists in the world. However, we are not only interested in accuracy, which is a product of how much time you allow Driverless AI to run and can be configured in the beginning, but also the consistency between validation performance and performance in the test data, in other words the ability to avoid overfitting.
Here is a list of results from public sources that show Driverless AI’s validation performance and performance on the test data drawn with various combinations of accuracy and speed settings. Some of the results may contain combinations of multiple Driverless AI outputs and a metamodeling layer on top of them:
[table id=2 /]







