







Sparkling Water 3.30.0.3 is out
Sparkling Water is about making machine learning simple, speedy, and scalable with Apache Spark. This blog provides an overview of the following new features:
- No H2O Client on Spark Driver
- Speedups
- Automatic String conversion to Categoricals
No H2O Client on Spark Driver
Previously, Sparkling Water always started worker nodes either on Spark executors in case of internal or external backend. To be able to communicate with such created worker nodes, we needed to start another instance of H2O on the Spark driver. This approach, however, has several disadvantages.
In order to overcome the disadvantages from our previous approach, we decided to completely replace the H2O client with a lightweight REST API client which runs on the Spark driver. Our new approach significantly reduced the design limits of Sparkling Water. One of the major changes was removing the H2O client from the Spark driver in both PySparkling and RSparkling backends . This new approach has several benefits:
Easier to Deploy and Manage
- Because the H2O client was just standard H2O with a special flag, it required two ports to be able to communicate with the rest of the cluster. One for the API and one internal port. Currently, we no longer need the internal port and all the communication goes via the API port. We also support SSL via HTTPS.
- In the case of an external backend, it is now possible to reconnect to a new pre-existing H2O cluster during run-time. This was not possible before as the H2O client was tied to a single H2O cluster.
- We avoid issues with connections when the H2O client & the rest of the H2O worker nodes run on different networks. Previously we had to provide extra configurations such as client IP or client network address in order for the client to be able to connect. These requirements are now lifted and there is no need for such configuration.
- Since the H2O client was in some terms a regular H2O node, Xgboost was performing some computations on the Spark driver which is not desired. This is no longer the case with the new version.
More Secure
- In some environments, the H2O client can reveal security issues. By not using the client and using single, for example, secured HTTP connection, we ensure that the cluster and the communication are secured.
Enable Sparkling Water for Kubernetes
- This client-less solution simplifies Kubernetes deployments and enables Sparkling Water to run in cluster mode in Kubernetes.
Speedups
The version of 3.30.0.3 also includes several speedups when it comes to conversion time from H2O to Spark frame. The following examples show speedups on several datasets by 50%.
Benchmark
| Sparkling Water Versions | |||||
|---|---|---|---|---|---|
| Dataset | pre-3.30.0.3 (milliseconds) | 3.30.0.3 (milliseconds) | Columns | Rows | Speedup |
| airlines-1m | 5031 | 1603 | 9 | 1m | Almost 5x |
| airlines-10m | 7223 | 7151 | 9 | 10m | Same |
| springleaf | 24463 | 13951 | 1936 | 101810 | Almost 2x |
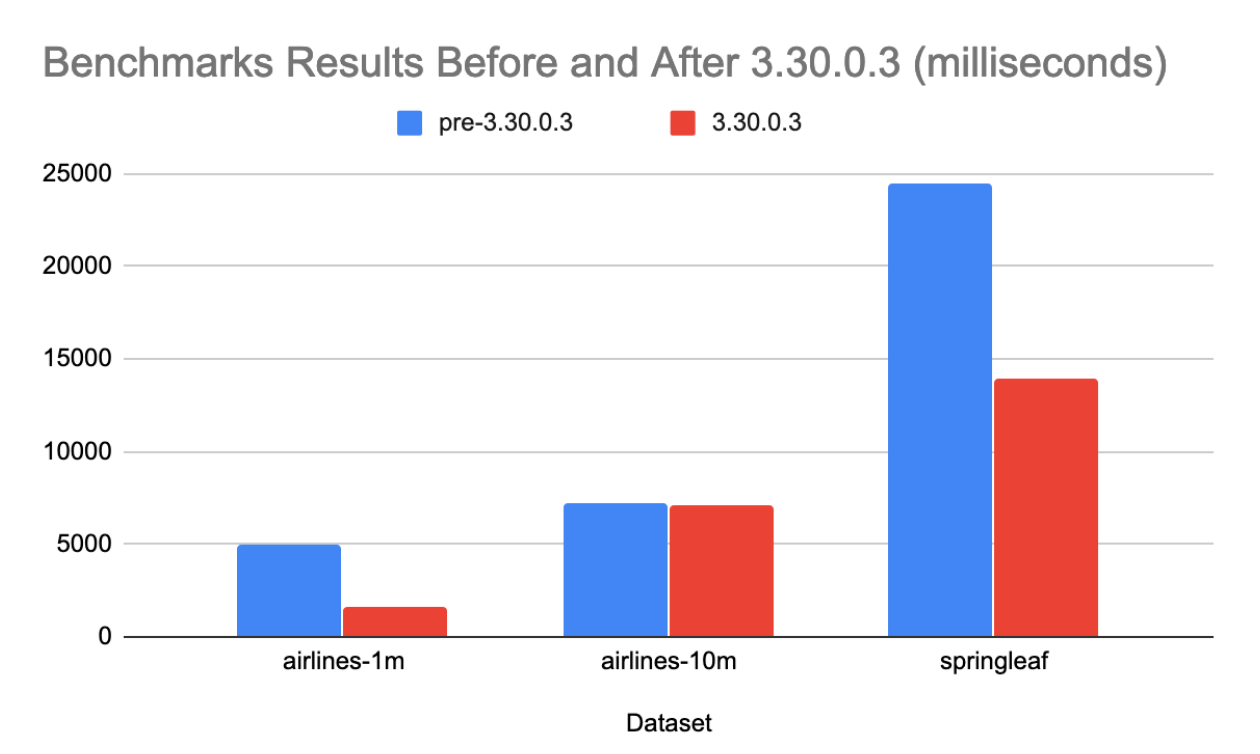
We can see that this speedup affects smaller datasets as we improve the internal protocol and ovoid creation of some unnecessary objects.
This speed comparison in data frame conversion was done using the H2OFrameToDataFrameConversionBenchmark in our benchmark. You can try it yourself or, better yet, try it with your data and let us know what performance you are seeing.
Simplifying String Conversion to Categoricals
Spark to H2O conversion on H2OContext now automatically converts strings to categorical values. This ensures that the frame created during the hc.asH2OFrame call has the same properties as the frame imported directly using h2o.import_file. We hope that his change will again simplify the Sparkling Water usage.
For example, in PySparkling API, the previous code was:
frame = hc.asH2OFrame(sparkDataFrame) frame[“str_col”] = frame[“str_col”].asfactor()
In the new version of the API, the conversion to categorical is done automatically, so the code you need to run is only:
frame = hc.asH2OFrame(sparkDataFrame)
Upcoming Changes
Please note that the benefits of REST API clients are available only in RSparkling and PySparkling so far. We are actively working on making sure the Scala implementation can run without the client as well and we are getting really close to achieving that.
Several other changes we are planning to incorporate to Sparkling Water soon:
- Kubernetes support for Sparkling Water.
- Expose remaining algorithms and stack ensembles to Sparkling Water API
Stay tuned and we hope you enjoy the new features in Sparkling Water.
Credits
This new Sparkling Water release is brought to you by Jakub Háva and Marek Novotný .







