







AT&T panel: AI as a Service (AIaaS)

Mark Austin, Vice President of Data Science at AT&T joined us on stage at H2O World Dallas, along with his colleagues Mike Berry, Lead Solution Architect; Prince Paulraj, AVP of Engineering; Alan Gray, Principal-Solutions Architect; and Rob Woods, Lead Solution Architect, CDO to discuss what they’re doing today and where they see the future of the data science practice at AT&T.
Democratizing AI
Mark Austin:
We’re going to talk about democratizing AI. We’re going to talk about AI as a service. A large portion of what we do is in democratizing AI. We’re all helping on this democratized AI journey.
Prince Paulraj:
Talking about democratizing AI and my portion I’m representing here, the team where the data scientists spend most of their time, right? Finding the data, creating the features, and building the model. I’m leading the team of Feature Store, so that’s my portion of the Democratization of AI.
Rob Woods:
I’m Rob Woods, product manager for a software solution we call Pinnacle. And once the data scientists or the staffers have assembled a feature set that’s worth building a model off of, we start doing the mathing, if you will.
I learned that’s a verb this week. Um, so mathing with auto ML and the crowd.
Alan Gray:
Hello everybody. My name’s Alan Gray. I’m responsible for the team that implemented H2O’s Hybrid Cloud and AI as a service along with other tools and capabilities in the create, deploy, and serve pieces of our AI as a service ecosystem.
Mike Berry:
Thanks. I’m Mike Barry, solutions architect. But my role I play on the team is AI as a service lead evangelist. So I get to talk to multiple business units across AT&T, and help them on their journey in AI.
Mark Austin:
So, let’s start with our evangelist. Tell us a little bit about AI at AT&T. How big is it? Give, what are some fun facts just to kind of get the ball rolling.
Mike Berry:
Yeah, so we have over 600 models in production. We’ve got about, you know, 300 professional data scientists and this year we’ve really focused on expanding the reach of AI to what we’ve called the citizen data scientist. And over the course of this year, you know, there are about 3000 people that are active in a monthly time period on our AI as a service platform.
AI as a Service (AIaaS) at AT&T
Mark Austin:
Cool. So, I think we actually have a picture. Okay. So Sri showed AI as a service before. There was a lot going on in that slide. If you saw AI as a service at AT&T. This is our simplified picture.
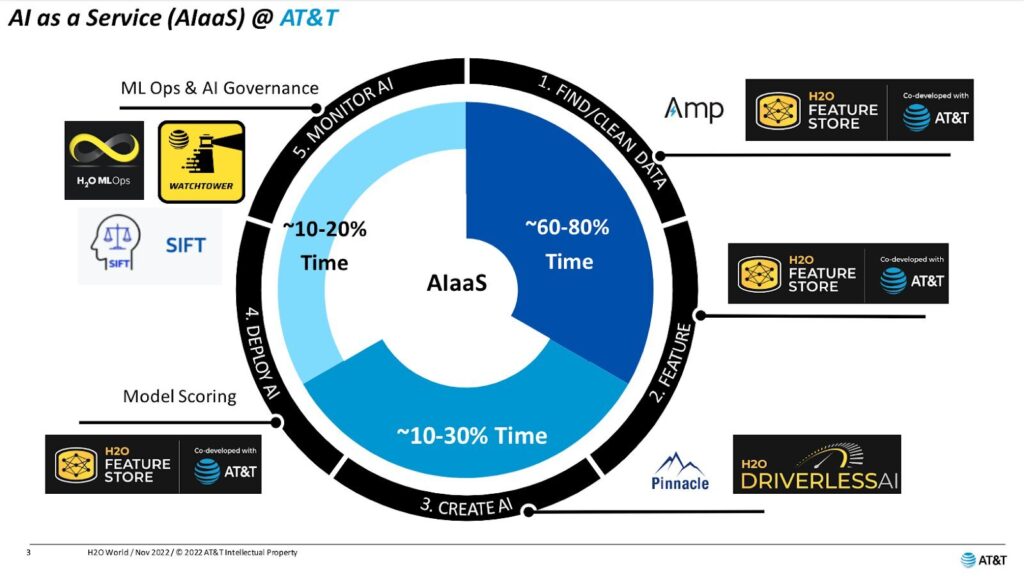
We’d like to think of it as a circle. Various folks will describe it, you know, how’s this start? Starts with finding data, getting data, cleaning it, right? That’s kind of step one. And then you engineer it. You create features, right? And those features, you try to reuse them as much as you can.
We’re gonna talk about that. And then you move in to create AI. That’s where the fun really happens for a lot of people, right? Building models per se. And then you move on to deploy and then on to monitor and govern. That’s where the bias stuff comes into it.
One thing you’ll notice, there’s a lot of black and gold in this slide. That’s our collaborator and partner H2O.ai in that regard, using their tools there. And we’re going to talk about those okay. As we go through this, we’re going to talk through this life cycle. Okay?
So, Prince, let’s kick it off. On the first part, you know, finding data and the other thing, look in the middle there. I think this is probably true. I’d be curious. You know, the audience we still see about 60 to 80% of the time is in that first step or two. Right. Finding it, getting it, cleaning it, transforming it, trying features, before you get to the modeling piece, so these first couple of steps are super important. Let’s talk about Amp and let’s talk about Feature Store.
3 Challenges AT&T’s Data Science Team Faced
Prince Paulraj:
I’ll start with some of the challenges that our team has faced in the journey of making this AI and democratization across AT&T.
Most of the time we see a couple of data scientists creating the same features, though they are sitting in the same team. In other words, these features are very important machine learning assets. It’s not centralized so no one can come and discover and reuse it, even from the collaboration standpoint. It’s not available in one place.
The second biggest challenge that we have seen, most of the time, data scientists create awesome machine learning models, but when you’re taking them to production, they’re handing them over to some of the ML engineers. So the performance in all those things in question, when you actually take it from development to production, we want to have a feature store, something like that, is really helping a one pipeline for development and deployment. Right?
The third problem is that we have so many technologies, right? I mean, we use great best of the breed tools in the industry. So we have Databrick, Snowflake, Palantier, Jupyter, we use H2O Driverless. There are so many tools out there. But we want to have one agnostic feature store which can consume the feature from any one of the pipelines and keep it in one place so that it can be reused across all data scientists at AT&T. So those are all the three important things I would highlight, why we need to have this feature store there and finding the data, with the combination of the amp, it makes it more powerful.
Mark Austin:
And how many features do you have, how long ago did you start this thing?
Prince Paulraj:
We released it in April this year and the journey is almost six to eight months now. But we have more than 25,000 features sitting in our feature store now. Like Mike mentioned, there are 600 models, but all these features are really useful in terms of development and deployment today.
The Water Cooler for Data Scientists
Mark Austin:
It’s grown about 10% a month, believe it or not. A lot of it is like, let’s make sure it’s curated, make sure we understand the pipeline behind it as well. But often we refer to this as a water cooler for data scientists, right? This is where you go.
And the other reason I love the word “store,” and Mike always knows that we always use this, right? We love the word “feature store” for two reasons: It’s a store for shopping. You shop for features. It’s also a store for storage. That’s where you put them, right? So I love that analogy.
So Mike, does this water cooler work? Do you have any cool examples where we actually used it?
Mike Berry:
Yeah, it does work. And you know, as more features come online, this flywheel is starting to spin.
Build Faster, More Accurate AI Solutions in a Fraction of the Time
One of my favorite examples from this year actually, you know, Mark challenged one of the data scientists on his team with a very mature fraud model. They said, “Hey, you know, we’ve just launched this feature store. I bet ya in an afternoon you can find a feature, add it to your current model and you’ll get some improvement.”
It took a little bit of arm wrestling on the coffee break between meetings, but that data scientist did. And in one afternoon, between meetings, they found a feature, added it to the model, and got, I believe it was a 37% increase of a model that had been in production for a year.
So, it does work and I’m seeing more and more data scientists flock to it. But those citizen data scientists are also starting to come because they may not have the 60-80% skillset that is required to create model-ready data sets and where they can go to the store and just find some ready to go.
Creating AI & Causing a Culture Shift at AT&T
Mark Austin:
Yeah, that’s cool. And I think we bring those stories, we got lots of those stories and that’s what we’re going to hear more about. How do we actually share those things going forward?
So let’s move on. So we’ve found the features, we’ve created the features. Let’s move on to this next step: create AI. And there’s something unique next to the black piece, the driverless AI, which you’ll talk about in a second. But, let’s talk about this thing called Pinnacle. What’s novel about what we’ve done there?
Rob Woods:
The novel portion there is that we’ve got a tool that enables us to–this word that keeps getting said over and over again, which is: “democratize.”
We’re causing a culture shift at AT&T, right? So how do we take the great number of folks that are here that have either been engaged in network activity or in software development, and educate them to make more use of machine learning.
So we see that by creating an opportunity to get crowdsourcing involved and we stack that on top of autoML. Now, the fun part here over the last few years is that we’ve tried just about every autoML under the sun. We’ve had 19 of them running through this tool. This is the base. Every data set that comes into Pinnacle automatically gets churned on by the autoMLs and it creates machine learning models.
This all happens within just a few hours, right? The fun part there is that we get to see those things get stacked ranked on top of one another. We wash out the autoMLs that don’t perform, and we keep those that do.
So let me give you a fun statistic here. There’s about 5,500 models that are in Pinnacle today. About 4,600 of them were created by staff at AT&T. The other 900 were built by autoMLs. There are 245 use cases that are in Pinnacle today. Over four years. 245 times we’ve gone to this thing and said, create a machine learning model with the data set.
Mark Austin:
So this use case, think of it as a competition, right? You’ve all heard about Kaggle. We’ve got plenty of Kaggle Grand Masters here. This is what we do. So every time we do these things, this use case is a competition. Right?
Prince Paulraj:
Almost every day if you do a hackathon.
Mark Austin:
We do a hackathon every day AT&T. Right? So it’s just part of the culture.
Rob Woods:
It is. It is. Absolutely.
So out of those 900 plus models that are out there created by autoMLs, almost half of them were created by H2O products, so congratulations to Sri and his team. What that means is there’s a high level of tolerance for the data quality that we might bring into those data sets, right? They run every time. And that’s a fantastic thing too.
The fun part about that as well, not only are they reliable and run, and I’m talking about two of the H2O products here, the Driverless AI as well as the open source autoML, but they always score at or near the top. So we had 19 autoMLs, we’re only running 10 today, and Driverless AI and open source autoML have stayed in there since the beginning.
So again, congrats. It’s helped with a big culture shift here at AT&T. It gives us somewhere to start.
Mark Austin:
So Rob, are you saying that the autoMLs a great thing to kind of get you started? Does the autoML ever win?
Rob Woods:
One out of 245 cases, once. They won once. Sorry, but the people always beat the machine.
Mark Austin:
Why is that?
Rob Woods:
Yeah. So the autoMLs are the start, right? You get in there and those things have run within a day. Data science is not easy. We know that it takes time, so why not take the thing that’s been built here within the last few hours? And we’ve got multiple use cases too that help to prove this.
Ensemble is a fantastic tool that these guys have made use of, we’ll talk about, I can tell you stories about use cases where the top 15 were ensembles of an autoML plus a custom recipe.
Mark Austin:
So, the bottom line, we always ensemble on top of it. In fact, you’ve enabled that in Pinnacle as a point and click, right? You can have Pinnacle Ensemble for you.
Rob Woods:
Yes, for most of our use cases, there’s an average ensemble function that most folks can take use of with literally two clicks.
Mark Austin:
Cool. So Mike evangelist, have we tried this out? You got any kind of cool stories about how we’ve used this?
Improving the Marketing Team’s Churn Model
Mike Berry:
Yeah. So, one of the first engagements I had this year was with our broadband marketing team.
And they had a churn model that had been in production for a couple of years. We’re working on another platform, and wanted to kick the tires on AI as a service. So they brought their churn model over We, within a day or two, ran it on Driverless AI and they got a 64% performance increase.
Simultaneously, we kicked off a Pinnacle Challenge, ran that for a few weeks. I think it’s still one of the top participated challenges. I think it was 89 participants with over a hundred models. And the winning model, which was an ensemble, was 154% increase over the baseline. And that is now the current production churn model for the broadband team.
Mark Austin:
Yeah. Now a fun fact on Pinnacle is when we started off we were like, well, we’re, we’re 300 data science and developers in our team, the centralized team, but there’s data scientists now across the whole company. We have data scientist titles out there. The interesting thing that’s always funny to me is, I look at the leaderboard and it’s like, Was that person in our group? No, they’re in finance. In fact, I go, who are these? Who is this person? Oh, well they just took their masters and they got this thing and they’ve been trying it out and sure enough, there they are. Right. So it’s a great way, it’s almost a bit of a bragging rights kinda, you see Kaggle do that too, right? You get the Grand Masters and stuff, so it’s kind of a nice bragging rights thing. And Rob, do you ever entice folks to participate? What do you do?
Rob Woods:
Absolutely. So there’s a number of motivators that’ll bring people out to these things. One is, are they interested in the subject matter and do they like to solve the problem? That’s fantastic. We love to see folks show up and do that kind of thing.
The others are motivated by competition. Sometimes they just wanna see where they rank or can they practice their skills. We’ve never once made somebody feel bad for not showing up at the top of the leaderboard. We encourage and celebrate everybody who shows up. And when they show up over and over again, like Mark said, we notice. And that’s a good thing. That’s a great thing for AT&T as well.
Mark Austin:
And sometimes you put a bounty.
Rob Woods:
We will put a bounty on these things. Yeah. For those use cases that could demonstrate a great amount of potential for financial benefit to the business, we will throw some money to the winner as well as the use case owner.
Mark Austin:
Yeah, I mean, just think if you’ve been working fraud as an example, right? You had a 1% improvement in fraud, it could be millions of dollars, right? So you really wanna squeak it out. I think our favorite motto, Rob, is the crowd always wins, right?
Rob Woods:
Every time.
Mark Austin:
So it hasn’t failed us once there.
So let’s talk, well actually, is Pinnacle available if somebody else wanted to have their own internal Kaggle at their company? Is that available?
Rob Woods:
Yeah, so we’ve uh, it’s been a hit at AT&T so we wanted to make sure it was a hit out on the open market as well. So there is a pinnacle.att.com instance out there and consumable.
Mark Austin:
So catch Rob afterwards if you’re interested in running your own Pinnacle. It could be available for you too.
Alan, any other Driverless AI, like, give us some stats on Driverless AI.
Build Models Faster and Better with Any Skillset
Alan Gray:
Sure. So, you know, we always talk about building models faster and better, right? But what Driverless AI really does is it enables users across different analytics skill sets, right? So, we have today, we have 380 plus users of Driverless AI in our organization across 80 different business units within the company, right? So that’s a lot of users that we scaled to very quickly. Right?
When we first started with driverless, we had 10 trial licenses, right? We deploy in the cloud, make it available to the enterprise. And now we have, you know, we’ve been able to scale in the last year and a half, almost two years, 380 users, right?
Mark Austin:
So, yeah, looks like our Australia peers have a bit more there, so we’ll have to see.
So let’s talk a little about, move on to the next part here, model and scoring. How are we using, well, we got Feature Store there too, right? Talk about that one.
Improve Model Development Time
Prince Paulraj:
Yeah. I mean, especially like you talked about it, right?
I mean, it’s good for the model development time. You go and publish the features in the feature store, but you know, it’s also the same features used during the scoring time, right? So we got a multiple pipeline, you might have a batch scoring, or you might even have a real-time scoring.
Some of the features in fraud, you know, we’ve got to just generate them in less than 200 milliseconds, you know, less than a hundred milliseconds. So that’s where this feature store is kind of playing the data role. It happens at the time of the development as well as and after the fact you deployed this scoring time also. It’s quite useful.
Mark Austin:
So I almost think of it, it’s almost like an API store, right?
You hit this thing and you can score stuff too. So it’s really cool for that as well.
All right, so Alan, let’s move on to ML ops and give us some fun facts there.
Alan Gray:
Right. So we’ve worked really hard with our colleagues at H2O to really harden and make our ML ops environment more robust.
When you think of how we used to or traditionally deploy models in AT&T, we, you know, have to, like Prince mentioned, we pass it off to another team, right. You know, for deployment or recoding in production systems. Right. You know, I’m not saying IT systems or processes are bad, right? But they oftentimes add complexity and they also could add lead time.
And I’m gonna borrow a stat from your team, the ML ops team, that we learned in a workshop:
Over 80% of models that are built across industries aren’t deployed to production.
So we’ve worked really hard with the ML ops team to make sure that we get these models in production, we make it more of a point and click system for rapid deployment. And then on top of that, within ML ops you’re able to monitor, right? You’re able to challenge and test your models to make sure that you’re continually providing the best-in-class models in production.
We’ve also integrated with Watchtower.
Monitoring: AI Checks on AI
Mark Austin:
So let’s talk about that. So ML ops, I think people kind of, kind of get what that is.
It doesn’t really stop with ML ops in our experience. What is this thing Watchtower that we have here?
Prince Paulraj:
You know, Sri mentioned that, right? AI checks on AI. So that’s very important, right? Because when you deploy the model, it’s not just the model, right?
The data actually goes into the model. If you look at the model lineage, there are features that’s going as an input to the model, and the model is departed on some infrastructure and it’s inserted in part of the business process, maybe through the API. Right. So when you need to monitor, we’ve got to monitor every piece of it, and everybody’s interested. Different personas, if you understand, DevOps, ML ops, and even the data scientists or ML engineers, everybody’s monitoring it, but Watchtower is a place that’s bringing all them in one place together. And you can really understand what’s the root cause–model drifting, feature drifting, or API issues–all these things can be solved in a quick fraction of time. So that’s why Watchtower is so powerful for us.
Mark Austin:
Yeah, I’ll never forget that Prince and I were caught on a Black Friday, which is a huge sales day for AT&T and there was something that was going wrong and there were 30 systems that had to fire to complete this thing. And it was like, man, it’d be really great if we had a watch tower like thing to look over all those things. So that’s a little bit of the genesis for this thing in the past, of course.
Okay. So, Sri mentioned a little bit, you know, making sure we’re doing AI responsible and right. And we have a product called Sift internally. Mike, you work on that with, I see Chris Walinsky and the team out here as well.
Tell us a little about, a little about Sift. Like what is it doing?
System to Integrate Fairness Transparently
Mike Berry:
Yeah, so Sift, which stands for System to Integrate Fairness Transparently is a tool that has a team behind it that will help data scientists and data engineers, really anybody that’s doing AI and ML, evaluate their life cycle for governance and fairness.
We kind of have it in that fifth position there, but it really should occur throughout the life cycle.
You come to the site, you put a little information, a bit about what your use case is, and then once you have a data set ready, you load up the data set and it will actually evaluate the data set for bias.
And if it detects bias, it actually can help you remediate that by adding additional waiting columns to those. And then once you have your data set, it’ll also do the same thing for the model. And then track all of that. And then once you’re ready to deploy, it records and, for posterity’s sake, you know, your entire document of that. As your model is out there in the wild, you’re confident that it is behaving fairly.
Mark Austin
Cool. All right, so of course behind all of these great tools and our whole idea of democratize AI, the way I think about it is, enabling more people to do AI better and faster. Right? That’s what it’s all about.
Right? So we’re trying to focus on that thing. So the people piece, we hadn’t really talked about that. What is the vision, Mike, of the people? Like what are we trying to get others involved with us? What are we doing?
Field Operations Using AI for Workforce Estimation
Mike Berry:
So when I opened, I mentioned the citizen data scientists. AT&T has a large community of people that have some data level skills, and a large pool of those have some coding level skills. They’re just not in the area or of professional data scientists. So we are reaching out to them, integrating all of these tools together, creating one user account to get access to all of them, to reduce friction in their onboarding experience.
And then providing training. We’re now hosting a biweekly call called the AI Democratization Forum. We’ve had several thousand people over the course of this year attend that, and the content, we’ve gone through this entire life cycle of tools and we’ll spend an hour on H2O Driverless AI and a couple hours on feature store, a couple hours on Databricks, which is one of our other tools listed.
Just train them how to use that and then create a community for them to collaborate, that water cooler. And so we’ve seen some significant success. And we’re working with lots of different groups. Our field operations group is a big participant. Care is a big participant. The marketing teams, finance, fraud. So it’s all areas of AT&T participating in not just this forum, but you know, actual use of the tools.
I’ve got one use case for Driverless AI earlier this year, we had a field operations team that paid a vendor to come in and build a model for them to workforce estimation.
AT&T sells fiber. When that fiber to the home is installed, they leave the cable on the ground, and then a day or two later, a technician will come and bury that cable for you. Well, this workforce estimation is guessing how many people they’re going to need to bury cables and that model that was built by the vendor had an issue with its time series element.
And it drifted over several months to be ineffective. Well, that group came to us through the forum and asked, “Hey, can you help us look at this? Because you know, we no longer have the vendor here. We’ve got one data analyst that knows a little bit of SQL, but he’s never worked in AI before.”
And so me and my partner in crime, Eli Schultz, who’s a data scientist, we spent about three hours with him. One hour overview of Driverless AI, one hour going over their model, and then watching him work for one hour to fix the model and actually improve it.
And so they got their model working again, with improvement, and they’re seeing that they’re saving up to 560 dispatches per day, saved with this model.
And again, just a business analytics guy that had a little bit of SQL skill got in, was able to use the tool effectively and now they’re no longer dependent on a vendor to come in and build their models for them.
Rob Woods:
That’s cool. There’s not a person alive who hasn’t seen a cable strewn across a sidewalk or their driveway at some point. So that’s one of those relevant cases, isn’t it?
Using Apps to Deliver Consumable Insights Back to the Business
Mark Austin:
Yep. All right, so the last thing that we’ll talk about, we don’t have it on the slide, but, we’re really intrigued and really loved the idea of apps, right? Because that’s what hits the business users. Right? And I don’t know if you’ve ever been in meetings, sometimes you try to pull up a notebook and you say, let me walk you through the notebook. Let me show you some stuff. It’s hard for the business user. You almost lose them, right? So tell us a little bit about apps and what we’re trying there, Alan.
Alan Gray:
Sure. So we’ve had Wave, the AppStore, and the app framework deployed in our ecosystem for a little bit over a year, and we’re seeing about 220 users across the Wave platform. Those are people that are researching AI applications, those are people that are building applications, and those are people that are already consuming applications.
We have about 16 production applications in our app store today. What we’re noticing, to Mark’s point, is that our business partners don’t want to consume our data insights by us walking them through the code. By being able to deliver an application prototype in one to two weeks in some cases, an application is really giving us that framework, and that template for how we deliver insights back to the business in a way that they can consume them.
Mark Austin:
And from a data science perspective, what I love is you go from a notebook and python to an app.You don’t have to hand it off to another team and write, so you remove that obstacle there.
Alright, so last thing we’ve talked about, about our journey. We’ve talked about democratization. Where do we think we’re going to be a year from now if we were to come back, any kind of final thoughts, visions?
The Next 5 Years
Prince
We are also experimenting with some of the other tools from H2O: the Hydrogen Torch and Document AI. We see that the more these sorts of tools can also empower the data science work we do, that’s one thing that we see that could become good for us the next year.
But overall the goals that Andy gave to us: democratizing AI, the next five years, the five X, to see that AI is the fabric of AT&T.
Mark Austin:
Five times more people doing it, right?
Mike Berry:
Yeah. So really shift the spectrum up the scale so the people that are smart in AI get smarter, can do more faster and better. And the people that are just learning AI can get in and start producing.
Alan Gray:
Yeah. We’re seeing some trends in our user base as well. When we take Driverless AI, for instance, those 380 users, when we first deployed it, about 70% of the user base was professional data scientists. Halfway through the year when we talked, when we had our last quarterly review, it was about a 50/50 split. Right now we’re 40/60 professional data scientists versus citizen data scientists.
Right? So it’s really important for us to be able to upscale those users.
Mark Austin:
One third of the people that show up in your democratization forum don’t code at all. Right. And a large portion of this, it’s really cool, you can point and click their way through it. Right.
So I would love to get to the whole way, point and click. The apps kind of come to get us there as well.
We love the co-development we’re doing here and it’s just going to get better and faster, right? So thank you all.








