







Reducing False Positives in Financial Transactions with AutoML

In an increasingly digital world, combating financial fraud is a high-stakes game. However, the systems we deploy to safeguard ourselves are raising too many false alarms, with over 90% of fraud alerts being false positives. These false positives, not only frustrating for consumers but also costly for financial institutions, can eclipse the cost of the fraud itself. Traditional fraud detection models, burdened by static rules, lack of adaptability, and high maintenance, are the primary culprits contributing to this issue.
To alleviate these limitations, financial institutions are starting to integrate machine learning models into their existing systems. By utilizing machine learning models, specifically Automated Machine Learning (AutoML) and anomaly detection techniques, these new systems can adapt to changing fraud tactics, reduce false positives, and therefore cut down on operational costs. Implementations of these strategies have been successful, reducing false alarms by 64% and actual fraud by 50%. This underscores the potential of machine learning in transforming the landscape of financial fraud detection.
The Staggering Economic Impact of Fraud
Fraud is a pervasive menace that grows in tandem with the expanding e-commerce landscape. It accounts for an estimated 6.4% of the global GDP [1] (this equates to USD $5.38 trillion ), outpacing the economic output of Germany, Europe’s largest economy. However, an often-understated issue is that the cost of fraud prevention systems eclipses the cost of fraud itself by three times.

One key contributor to these staggering costs is the high rate of false alarms. Regrettably, with traditional systems, more than 90% of fraud alerts are false positives.
Current Fraud Models
The majority of fraud detection systems in place today leverage rule-based models. These models are simple in design and work on the concept that each fraudulent act follows a certain discernible pattern. When we can identify and understand these patterns, we can effectively pinpoint fraudulent transactions. To unpack this concept further, let’s dive into the inner workings of rule-based models.
How Rule-Based Models Function
At their core, rule-based models are systems of if-then statements. These systems apply predetermined rules to a given transaction. For instance, if a transaction exceeds a certain amount, then the system flags it for review and potentially rejects the transaction. These rules are often formulated based on historical data and domain expertise.
Some of the most common rules that rule-based systems use in fraud detection include:
1. Card Present or Card Not Present (CP/CNP) : Transactions where the card is physically used (Card Present), are less likely to be fraudulent than those where the card is not physically presented (Card Not Present).
2. Location of Transaction : Transactions from locations where a customer has never used their card or from locations known for fraudulent activities are more likely to be flagged as fraudulent.
3. Distance Between Locations of Last Two Transactions : If the last two transactions were made in locations far apart within a short time, it is likely that at least one of them is fraudulent, as it might be impossible for the cardholder to travel that distance in such a short span.
4. Frequency and Amount of Transaction : Frequent transactions within a short period or transactions with abnormally large amounts can also be flagged as suspicious.
These rules, among others, provide a starting point for identifying fraudulent activities.
Limitations of Rule-Based Models
While rule-based models have been the backbone of fraud detection for many years, they come with significant limitations:
1. Limited Features: Rule-based systems can only consider a limited number of features or attributes of a transaction, such as geography, amount, and rate of the transaction. These models cannot easily incorporate complex patterns or trends in the data, limiting their effectiveness.
2. High False Positive Rate: Rule-based models often err on the side of caution and flag many transactions as potentially fraudulent, leading to a high number of false positives. This can be frustrating for customers and costly for businesses.
3. Lack of Adaptability: Fraudsters are constantly changing their tactics. Rule-based models, with their static rules, struggle to adapt quickly to new types of fraud.
4. Maintenance: The rules in these models need to be constantly updated and tweaked to remain effective, which can be a resource-intensive process.
In light of these limitations, financial institutions are turning to more sophisticated approaches, like machine learning, to augment traditional rule-based models for fraud detection.
Evolving Beyond Limitations of Rule-Based Models
How do we mitigate the issues embedded in current systems? The goal is to increase accuracy, reduce false positives, ensure transparency, and maintain swift response times. Achieving this balance is a challenging task, but recent developments suggest it is feasible.
At H2O , we’ve collaborated with some of the largest enterprises to address these specific challenges . By leveraging Machine Learning (ML), we have achieved impressive results, reducing fraud by up to 80% [2]
Machine Learning to the Rescue
Consider a large financial institution processing an enormous volume of transactions. The main issue is a significant number of transactions being falsely flagged as fraud. To understand the context, let’s examine how transaction monitoring systems function.
When a transaction is processed, it passes through a rule-based decision engine, as mentioned earlier. The system then decides whether it’s legitimate or requires review by a fraud analyst. Due to the low accuracy of these systems, some fraudulent transactions slip through, while many legitimate transactions are incorrectly flagged as fraud, creating a false alarm scenario.
In the context of credit card payments, the cost of these false positives is estimated to exceed $100 B, ten times the cost of actual fraud [3].
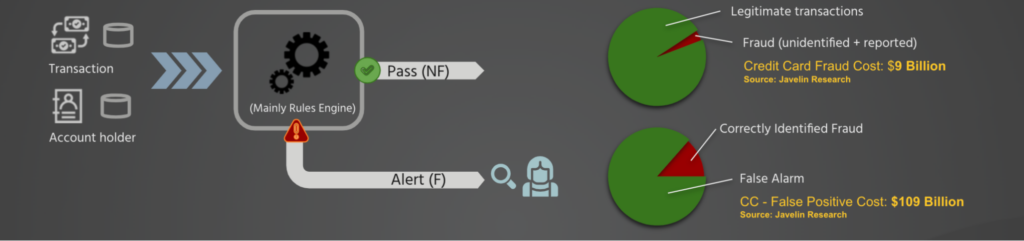
Therefore, our mission presents a dual challenge: improve accuracy to detect more fraud and reduce the incidence of false positives.
Redesigning the Fraud Detection System with Machine Learning
As we discussed, current fraud detection systems tend to rely heavily on predefined rules, which, while useful, often lack the dynamic and adaptive capabilities necessary to deal with the complexity and ever-evolving nature of fraudulent activities. This is where machine learning comes in, offering solutions that can adapt and learn from new data, increasing their accuracy over time. We present several machine learning principles utilized in the architecture of fraud detection systems.
Supervised Machine Learning Models:
The first stage in incorporating machine learning into fraud detection involves the use of supervised machine learning models. These models are trained on a dataset with known labels, in which the result (fraudulent or not) of previous transactions is clear. This label-defined dataset is assembled by fraud analysts who highlight fraudulent transactions. Once these models are trained, they can predict the likelihood of future unseen transactions being fraudulent.
Transactions that have been through the initial rules-based system are then further examined by more advanced machine-learning models. These models may use methods such as random forest, gradient boosting, or deep learning, which can recognize intricate patterns and associations in the data that may not be discernible by simpler models or rules-based systems. This is possibly the easiest component to implement. This is because many transactions flagged as fraudulent by the rules-based engine have been scrutinized by fraud analysts and labeled as either a true positive (a fraudulent transaction) or a false positive (a legitimate transaction that was incorrectly flagged as fraudulent by the rules-based engine). These reviewed transactions provide valuable data for constructing such supervised machine learning models, which aim to reduce the number of false positives. These models are typically placed after a rules-based engine and reassess all transactions flagged by the engine.
Automated Machine Learning (AutoML):
Manual feature engineering – the process of extracting useful features from raw data – can be labor-intensive and requires considerable expertise. AutoML simplifies this process by automatically identifying and creating useful features that improve model performance. In fraud detection, AutoML could help extract more granular information about historical user behavior or transaction patterns, which can significantly enhance the detection of fraudulent transactions. A study by MIT AI LAB[4] demonstrated that false positives could be reduced by over 50% by integrating new data points and automating feature engineering to extract granular behavioral patterns.
Anomaly Detection Techniques:
Fraudulent activities usually manifest as anomalies – they diverge from standard behavior. Machine learning models have the ability to understand what constitutes “normal” behavior and subsequently flag transactions that seem irregular. Each transaction can be assigned an anomaly score, where a higher score suggests a greater probability of fraud. The rationale for employing anomaly detection in fraud detection systems is twofold. First, certain types of fraud committed in the past may have gone undetected and, thus, are not labeled. As a result, a supervised method would fail to identify such fraud types. Second, the task of fraud detection needs to be constantly evolving. As the fraud detection system becomes more adept at identifying certain patterns of fraud, fraudsters often devise new strategies to perpetrate fraud. Consequently, anomaly detection can prove effective, as novel patterns of fraud can often manifest as outliers.
The following illustration demonstrates the integration of these elements to form a multi-layered strategy for defending financial transactions against fraudulent activities. This multi-layered machine learning approach enhances both the detection of actual fraud and the reduction of false positives. By training models on the latest data and using them to adapt to new trends and tactics in fraudulent behavior, we create a dynamic and effective defense against fraud.
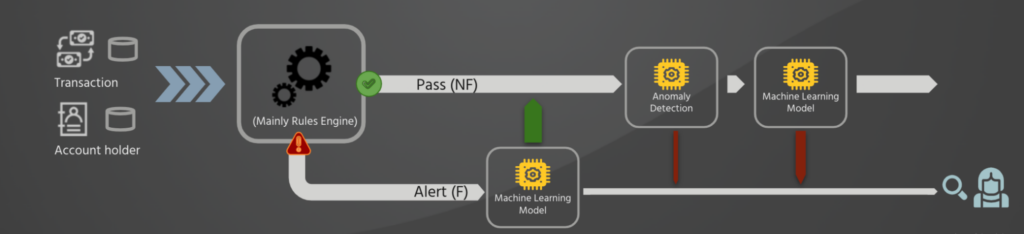
As a result of implementing such strategies, organizations can expect an appreciable decrease in false positives, thus reducing operational costs and improving customer experience. Machine learning, therefore, offers promising advancements in the continuous battle against financial fraud.
Conclusion
By implementing these strategies, our customers have successfully reduced false alarms by 64% while cutting actual fraud by 50%. This represents a substantial saving in transaction monitoring. With platforms like H2O AI Cloud, we’re empowering enterprises to build, deploy, and understand ML models quickly and accurately through automation. ML-based solutions not only enhance fraud detection but also help fraud analysts be more efficient. All in all, by combining machine learning and advanced analytics, we can reduce the cost of false positives and fraud, making financial transactions more secure and hassle-free for everyone involved.
As the adoption of AI becomes an increasingly strategic imperative for enterprises, we at H2O.ai stand ready to support your journey and address the unique challenges of your organization with our robust, user-friendly, and adaptable AI platform.
Next: Building Fraud Detectors with H2O AI Cloud
Stay tuned for our forthcoming blog post, where we will provide a practical, step-by-step guide on how to create the fraud detection systems we discussed in this post using H2O AI Cloud.
References
- The financial cost of fraud, 2021, Crowe LLP https://www.crowe.com/uk/insights/financial-cost-fraud-data-2021
- AT&T Transformed into an AI Company with H2O.ai /en/case-studies/att-transformed-into-an-ai-company-with-h2o-ai
- Source: Javelin Research https://javelinstrategy.com/research/addressing-threat-false-positive-declines
- Solving the False Positives Problem in Fraud Prediction Using Automated Feature Engineering https://link.springer.com/chapter/10.1007/978-3-030-10997-4_23







