







Improving Search Query Accuracy: A Beginner's Guide to Text Regression with H2O Hydrogen Torch

Although search engines are vital to our daily lives, they need help understanding complex user queries. Search engines rely on natural language processing (NLP) to understand the intent behind a user’s query and return relevant results. By formulating a well-formed question, users can provide more precise and specific information about what they are looking for, thereby helping the search engine’s NLP algorithms better understand their intent. This can result in more accurate and relevant search results. A possible solution to this problem, as suggested in the paper — Identifying Well-formed Natural Language Questions — is to train a model that utilizes the lexical and syntactic features of the text to predict whether a given query is a well-formed natural language question. This is a critical use case for NLP, and in this article, we shall see how H2O Hydrogen Torch can help us in this regard.
We’ll begin by getting an overview of the H2O Hydrogen Torch tool, covering an NLP use case, and demonstrating how to build and inspect an NLP model rapidly. While this article will focus on NLP use cases, Hydrogen Torch, a deep learning framework, supports much more than just textual data, including images, videos, and audio.
H2O Hydrogen Torch
The H2O Hydrogen Torch is an AI tool that enables data scientists of all levels to build deep learning models quickly without compromising on quality. It helps users unlock the value of their data by building state-of-the-art deep learning models in areas such as natural language processing(NLP), computer vision(CV), and audio analysis.
H2O Hydrogen Torch was developed to democratize deep learning and bring it to a broader audience. With a large amount of unstructured data being generated, many companies need help to analyze it due to the limited availability of skilled individuals in AI and deep learning. The tool is designed to cut through the difficulties of using PyTorch or TensorFlow and deliver deep learning models to companies lacking the resources to deploy deep learning projects independently. Additionally, users can keep their data and model within their environment without sharing it with any external company, thereby ensuring privacy and security.
Natural Language Processing with Hydrogen Torch
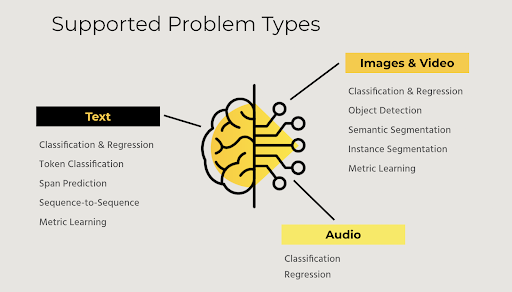
Natural Language Processing or NLP refers to applying computational techniques to analyze and understand human language, including text and speech. NLP involves using algorithms, statistical models, and machine learning techniques to extract meaning and insights from text data, allowing machines to understand and respond to human language more naturally. Hydrogen Torch supports many common use cases in NLP predominantly :
-

- NLP use cases currently supported by Hydrogen Torch
You can read in detail about the various use cases in the official documentation , which is pretty exhaustive.
Case Study: Identifying whether a natural language question is well-formed or not ?
We will build a deep-learning model to predict how well a question is shaped based on the given data. The input will be the text column, and the output will be a rating defined in the range between zero and one. This is a classic case of a text regression problem where the goal is to predict a continuous numerical value.
For this case study, we will use an example dataset that includes short texts consisting of questions and their corresponding manual ratings assigned on how well-formed the question is. This means a ‘0’ rating indicates a poorly formed question while ‘1’ denotes a well-formed query. The dataset comes from the publicly available Query-wellformedness Dataset , which is a dataset comprising 25,100 queries sourced from the Paralex corpus (Fader et al., 2013) that have been labeled with human ratings to determine if they qualify as well-formed natural language questions.
The sequential steps involved in an H2O Hydrogen Torch experiment, starting from its creation to deployment, can be summarized as follows:
Importing the dataset
H2O Hydrogen Torch provides multiple data connectors that allow users to access external data sources.to access external data sources. To import data into your Hydrogen Torch instance, you can select one of the following options:
- Directly upload datasets from your local system,
- AWS S3 bucket,
- Azure data lake or
- Kaggle.
Additionally, the upcoming April release will enable data ingestion from H2O Drive , which will offer even more connectors. We’ll use a demo dataset already uploaded into Hydrogen Torch for this article.

Let’s begin by exploring the dataset and looking at a few training data samples. In the H2O Hydrogen Torch navigation menu, clicking the View datasets tab gives us multiple options to understand our data better. We can look at the sample training data consisting of a text column and its corresponding rating in another column.
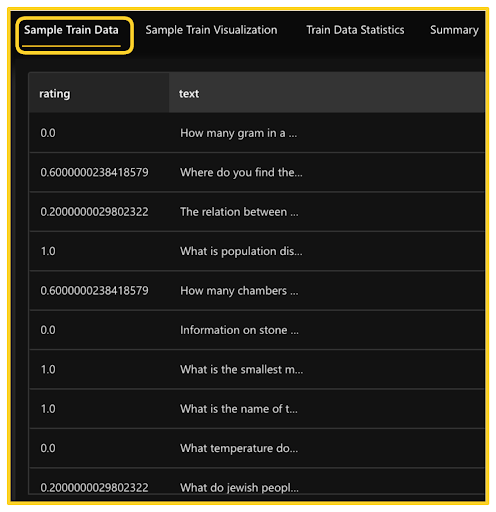
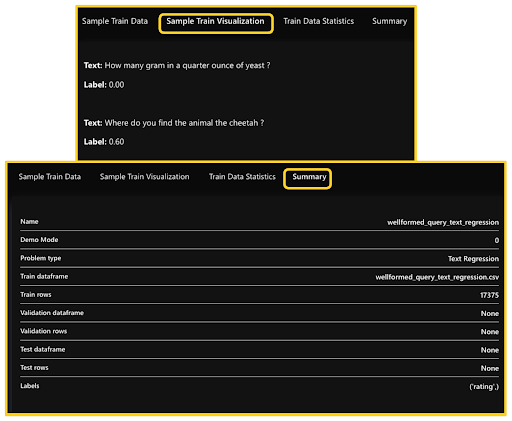
We can also visualize a few samples of the dataset and look at the training data statistics and overall summary. This provides a quick understanding of the dataset and serves as a sanity check to ensure the data has been uploaded correctly.
Training experiment model
Now that we have an idea about the dataset, it’s time to launch the experiment by clicking the Create experiment tab in the navigation bar. The first thing we would want to select is the experience level . Hydrogen Torch is designed to cater to multiple experience levels, from novice to master, depending upon the user’s experience with deep learning. To provide as simple an experience, we’ll select the Novice option. The create experiment page shows information regarding the experiment and some hyperparameter settings. Let’s go through them in order:
- General Settings include dataset name, problem type, and name of the experiment.
- Dataset settings include train dataframe, validation strategy, defining the validation folds in case of cross-validation, test dataframe if present, label column, and the test column to be used for the experiment. Since we don’t have a separate test dataframe for this experiment, we will not utilize this functionality.
- Architecture settings include the backbone architecture. The backbone architecture extracts meaningful features from the data. For an NLP task, we usually use a pre-trained model as a backbone that serves as the base for building more complex models. While Hydrogen Torch provides a list of pre-selected backbone architectures, users can select backbones specific to their domains and use cases. Moreover, the Hugging Face library contains thousands of pre-trained models to be chosen from. We’ll go with the default suggestion, i.e., BERT base uncased model.
- Training settings include the number of epochs the model will run before each validation loop during the training process. We will execute the experiment for five epochs.
- Prediction settings include the metric to evaluate the model’s performance. MAE (Mean Absolute Error) is the recommended default metric, which calculates the average absolute difference between the predicted and actual values in a dataset. A smaller MAE value indicates better performance of the model. MAE is more resilient to outliers, thus making it a reliable measure for assessing the model’s accuracy.
It should be noted that the experiment settings vary based on the selected experience level. We have utilized the default settings for most except for the number of epochs. Currently, our experiment preview page appears as follows:
-
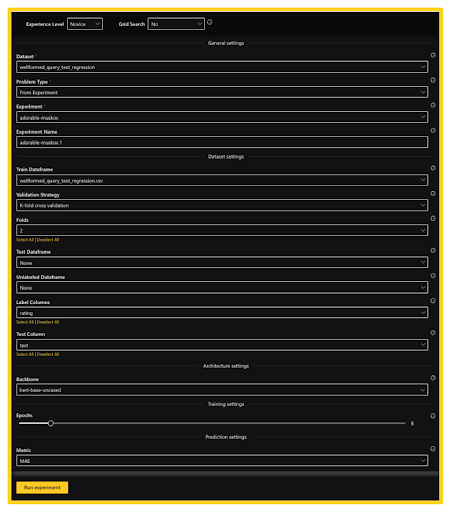
Various experiment Settings
It’s time to run the experiment.
Inspecting experiment model
With H2O Hydrogen Torch, you can inspect your experiment model during and after training. The platform provides user-friendly interactive graphs that facilitate understanding the impact of the chosen hyperparameter values throughout the model training process. This feature lets you detect the model’s strengths and weaknesses and implement necessary adjustments to enhance performance.
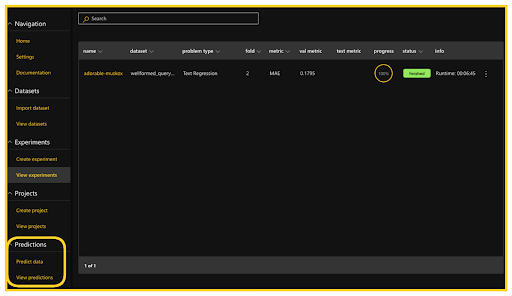
On clicking the View experiments tab, we are presented with multiple options to analyze our experiments. These options allow us to examine various aspects of the experiment, such as the learning rate, train and validation batch losses, and validation MAE. By doing so, we can gain insights about the experiment in real-time as it is running and after it has been completed. Below we can see the metrics both when the model’s training is 70% complete as well as when it is 100% complete.
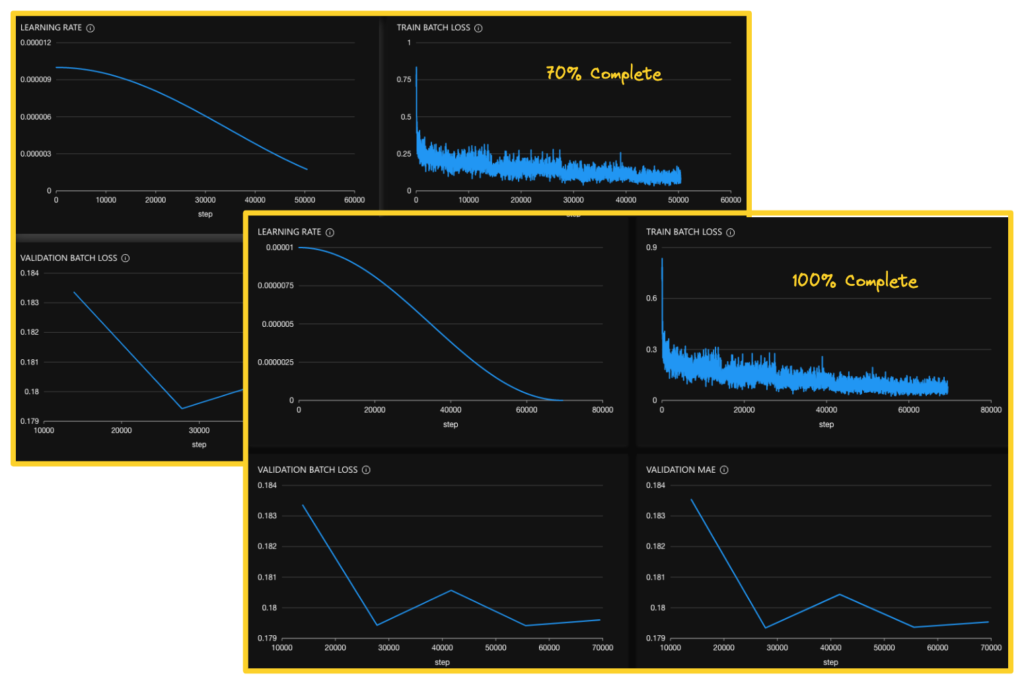
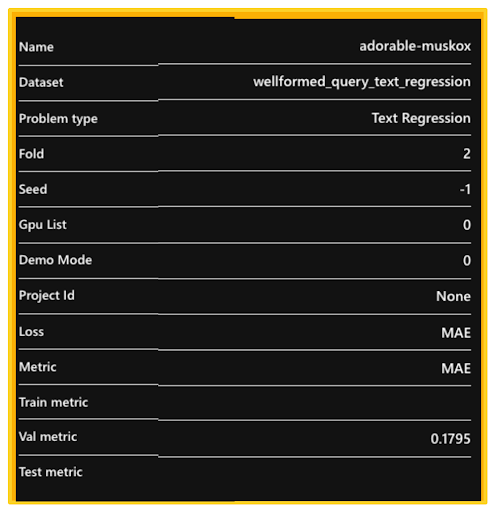
The Summary tab presents a table of summary metrics regarding the chosen experiment. We ran the experiments for only five epochs.
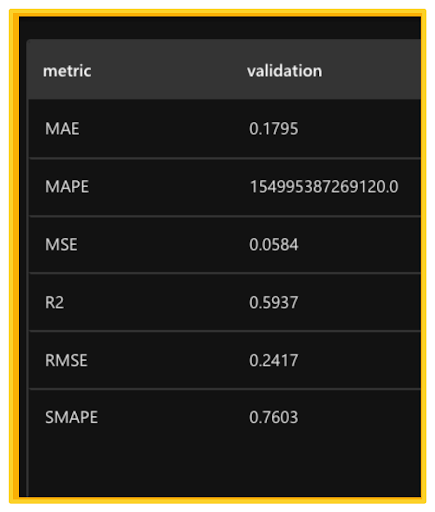
The Metrics tab displays the chosen experiment metric and other metrics applicable to the problem type of the experiment’
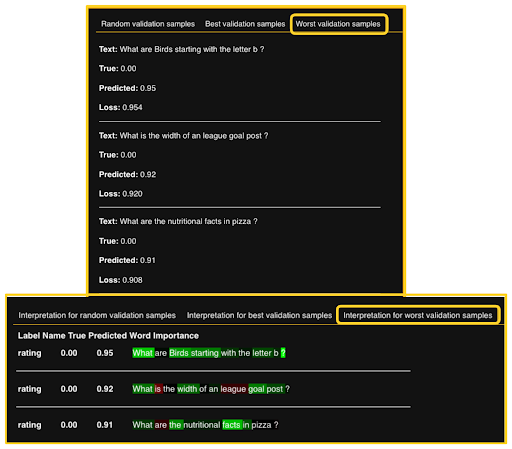
The Validation Prediction Insights tab visualizes an experiment’s validation samples displaying each sample’s loss value. One of the most interesting aspects is analyzing the samples that posed the greatest challenge to the model. This can lead to two possible scenarios — either the data subset is inaccurately labeled, or the model faces difficulties performing well.
Experiment Logs can be accessed via the Logs tab, while the Config tab allows us to view the configurations or to set values used during the experiment.
Making Predictions
Once the model training is completed, multiple tasks can be carried out, including generating predictions on a new dataset, retrieving logs and technical details, and obtaining out-of-fold predictions on the training dataset. The predictions can be downloaded and analyzed externally to optimize the model’s performance or integrated with other external tools.
Deployment
After thoroughly analyzing the model, it can be effortlessly deployed utilizing the H2O Hydrogen Torch user interface (UI) , H2O MLOps pipeline, or using the model’s Python scoring pipeline. Since there are several deployment alternatives, users can opt for the most appropriate option that suits their requirements. Further information regarding the deployment alternatives can be found here .
Conclusion
The Hydrogen Tool is a continuously evolving platform incorporating the latest best practices from Kaggle Grandmasters to bring new features and improvements to users. By leveraging Hydrogen Torch, you can efficiently develop and fine-tune your models to achieve optimal performance and accuracy. With built-in model tuning routines, you can customize and enhance existing models to meet your specific needs. At H2O.ai, our mission is to make AI accessible and efficient for everyone, and Hydrogen Tool is a vital part of that vision.
You can get access to Hydrogen Torch through H2O AI Cloud, or you can even request a demo from an H2O team member to better understand its capabilities.
References
- Documentation https://docs.h2o.ai/h2o-hydrogen-torch/guide/experiments/experiment-settings/text-regression?_ga=2.139785781.787168544.1697407057-536448005.1629701376
- Webinar: Natural Language Processing (NLP) with H2O Hydrogen Torch /en/events/make-with-h2o/on-demand/nlp-with-hydrogen-torch/







