







Make with H2O.ai Recap: Getting Started with H2O Document AI
Product Owner, Data Scientist, and Kaggle Grandmaster, Mark Landry presented at the Make with H2O.ai session on getting started with H2O Document AI.
The session covered an overview of H2O Document AI , a tool to extract insights and automate document processing. The session also included a product demo, looking at documents as data sets, how to do annotation with the tool, how to create targets, modeling and feedback, and publishing a pipeline.
H2O Document AI Overview
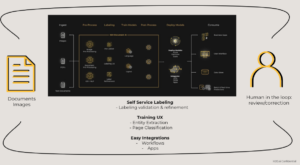
H2O Document AI can work with all types of documents such as PDFs, pictures of documents, faxes, and text documents. The process consists of pre-processing that is built into the tool, optical character recognition (OCR) models, labeling, training models (incorporating multiple models into the same pipeline), and post processing, taking the results of those models and deploying them.
The tool is not just for data scientists and annotators but as Landry puts simply, “the intent of our tool is to be simple enough to … train other people familiar with data, but not necessarily data scientists to be able to operate this tool as well.” The real value in H2O Document AI is that the tool is completing document processing tasks that humans are doing today. Beyond this, there is a REST API for deployment, which allows flexibility for how the data is consumed, whether that be in a data store, building a user interface on top of it, or integration with business applications and other tools. Lastly, there is a human in the loop: review/ correction aspect built into the tool “so you can stand up a model, and then work it better and better and better as you collect more documents … we can annotate from scratch, or we can annotate from predictions.”
Example: Medical Referral
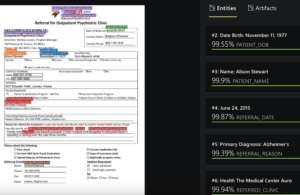
The image above is an example document of a physician referral from a use case with UCSF . Physician referral documents are sent from one practice to another and there is no control over the format, it is not templatized. As such is the case for most customers across various industries who have a situation where they receive thousands of different document formats, but this tool can handle the various formats.
There are likely multiple classes the customer is interested in pulling from these documents (116 in the case with UCSF). H2O Document AI uses deep learning models that can handle 116 classes of information with the same efficiency as 5 classes. The tool can pull information from various types of documents. See another document example below:
Model Generalizes Other Formats
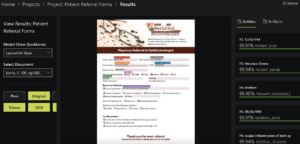
The format here is totally different from the referral form above, though each of these forms contain similar content.
The tool uses advanced deep learning models, transformer models, and high end NLP models (very similar to BERT). These documents aren’t read in typical reading order, reading left to right. The models are understanding the structure of the documents as a whole and table structures featured in the documents. Using transfer learning, the variants are pretrained models that have seen 11 million documents previously. The tool can process different document types, even documents that are more difficult to read can be managed with the OCR, shown in the examples below:
Any Document Type

H2O Document AI is saving customers thousands of hours compared with having humans complete these tasks.
Watch the product demo and recap of the Make with H2O.ai session: Getting Started with H2O Document AI. Attend an upcoming Make with H2O.ai session .







