







Announcing H2O Danube 2: The next generation of Small Language Models from H2O.ai

A new series of Small Language Models from H2O.ai, released under Apache 2.0 and ready to be fine-tuned for your specific needs to run offline and with a smaller footprint.
Why Small Language Models?
Like most decisions in AI and tech, the decision of which Language Model to use for your production use cases comes down to trade-offs. Many Large Language Models are excellent at solving a wide-range of Natural Language Understanding use cases out-of-the-box but require sending your data to a third party who is hosting the model, or having enough GPUs to run the large model privately. On the other hand, Small Language Models are more compact, nimble, and take significantly fewer resources to deploy - these smaller models are great at handling specific tasks and can be tailored to perform well within a narrower scope. When you have an application where resources are scarce and your use case is well defined, SLMs can be the way to go.
At H2O.ai, democratizing AI isn’t just an idea. It’s a movement. By releasing a series of small, foundational models that can be easily fine-tuned to specific takes and which are lightweight enough to run on your phone, we are expanding the freedom around the creation and use of AI.
H2O-Danube2-1.8B is built upon the success of its predecessor, H2O-Danube 1.8B, with notable upgrades and optimizations bringing it to the forefront in the 2B SLM category. We make all models openly available under Apache 2.0 license further democratizing LLMs to a wider audience economically.
What is H2O Danube2?
The H2O Danube series consists of compact foundational models, each containing 1.8 billion parameters. These models are designed to be lightweight and quick to respond, making them suitable for a broad array of use cases. Initially trained on 1 trillion tokens, the Danube models offer robust foundational capabilities. H2O Danube2 represents an incremental enhancement, having been trained on an additional 2 trillion tokens to refine and expand its learning.
H2O Danube has a context of 8k tokens and can be fine-tuned to support a wide range of use cases including:
Retrieval augmented generation
Open-ended text generation
Brainstorming
Summarization
Table creation
Data formatting
Paraphrasing
Chain of thought
Rewrite
Extraction
Q&A
Chat
In addition to the base foundational model, we have also released H2O Danube2 Chat. This model has been fine-tuned using open source H2O LLM Studio for chat-specific use cases.
Model | Description |
Base model which can be fine-tuned for a wide range of natural language understanding use cases. | |
Instruction fine-tuned model for chat use cases. |
What’s new in version 2?
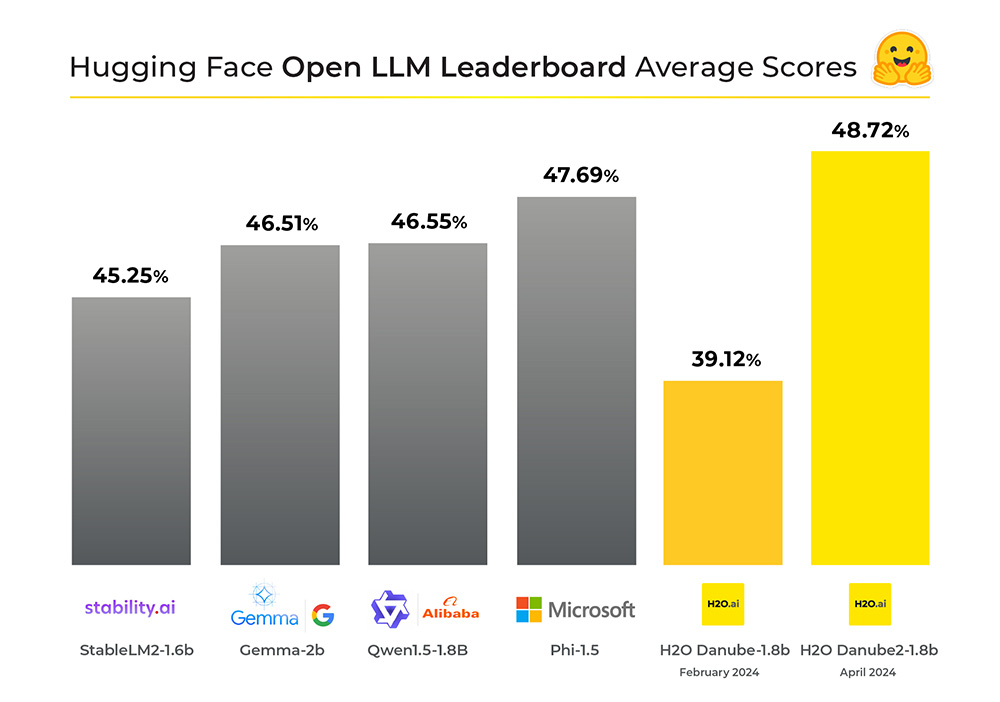
The latest release of these foundational models focus on improved accuracy, increasing performance on the Hugging Face Open LLM Average Leaderboard by 9% percentage points making it the top performing model under 2 billion parameters.
In addition to general improved performance, users will see better performance for long-context behavior as well.
On the technical side, here is how Danube2 has different and improved from its predecessor:
Improvements in long-context behavior: By removing the sliding window approach for attention, we effectively improve the retrieval capabilities in long context. H2O Danube2 models can handle a total of 8K tokens for input and output size combined.
Leverage Mistral Tokenizer: The choice of tokenizer is a crucial aspect of large language models, transforming and compressing the input text to token representations consumed by the language model. We found that switching to the Mistral tokenizer improves downstream performance, while keeping the same vocabulary size of 32000.
Improved Filtering: Better filtering and deduplication of training data by using advanced heuristics, as well as machine learning models (GBM and BERT) for predicting the quality of text and using predictions for filtering.
Data Curation Improvements: Significant improvements in underlying data curation leading to a three stage training of H2O-Danube2. At each stage, we gradually decrease the percentage of noisy web data in favor of higher quality data.
For details, please refer to our Technical Report.
Conclusion
Small Language Models allow organizations to solve natural language problems without the resources needed to use Large Language Models. H2O Danube2 is here to help users create the tailored solutions they need faster, and with less resources.
Whether you're looking to integrate advanced AI into your business processes, develop new ways to interact with data, or simply explore the potential of machine learning, H2O Danube2 provides the tools necessary to transform ideas into reality. The model's improved accuracy signifies our commitment to delivering cutting-edge technology that not only meets but anticipates the needs of our users.
Available for download and integration today, H2O Danube2 is ready to help your company be an AI company. We invite developers, researchers, and businesses to explore the possibilities with our community of innovators who are as passionate about AI as you are.










