






Document Classification with H2O VL Mississippi: A Quick Guide

In this tutorial, we'll explore using H2O.ai's Vision-Language model (H2OVL-Mississippi-800M) for document classification (for example, in document processing automation). Despite its relatively compact size of 0.8 billion parameters, this model demonstrates impressive capabilities in text recognition and document understanding tasks.

Mississippi Model Architecture: This diagram shows how input images and text are processed. Images are resized and cropped in three ways: (a) closest original size, (b) different aspect ratio, and (c) thumbnail.
Background
In today's business environment, organizations deal with an overwhelming volume of documents in various formats - from invoices and contracts to resumes and technical documentation. Processing these documents efficiently requires AI solutions that can understand both textual and visual elements. Vision-language models open up numerous possibilities for document processing automation.
Why Smaller Vision-Language Models Matter
Before diving into the implementation, let's understand why models like H2OVL-Mississippi-800M are particularly valuable:
Diverse Document Processing Applications
Document processing pipelines often include tasks such as:
Intelligent Document Routing: Automatically sort incoming documents into appropriate workflows:
- For example, invoices to accounting, resumes to HR, etc.
- After a document is classified, it is routed to the appropriate downstream model. For example, in insurance claims:
- First, classify whether the submitted documents are bills, prescriptions, etc., then:
- Medical Bills → Billing Extraction Model
- Prescriptions → Prescription Extraction Model
Data Extraction: Pull structured data from:
- Purchase orders and invoices (vendor details, line items, totals)
- Medical records (patient information, diagnoses, prescriptions)
- Financial statements (account numbers, transaction details)
Document Quality Assessment: Identify poor scans, missing pages, or incorrectly oriented documents
Form Processing: Handle various types of forms, including:
- Tax forms (W-2s, 1099s)
- Insurance claims
- Loan applications
- Government documents
Table Understanding: Extract and structure tabular data from:
- Financial reports
- Scientific papers
- Technical specifications
- Product catalogs
- Medical lab report
Strategic Role in ML Pipelines
While larger language models (LLMs) offer impressive capabilities, using them for every step in a document processing pipeline, when dealing with a large number of documents, can be computationally expensive and inefficient. A more strategic approach is to use smaller, specialized models like H2OVL-Mississippi-800M as efficient pre-processors:
Initial Triage: Use the smaller model to:
- Extract key text and data
- Identify relevant sections
- Identify relevant sections
- Focused Processing: Pass only the relevant extracted information to larger models for:
- Complex reasoning
- Natural language generation
- Decision making
This pipeline approach offers several advantages:
- Cost Efficiency: Minimize the use of expensive computing resources
- Speed: Process documents faster by using the right tool for each task
- Scalability: Handle larger document volumes without proportional cost increases
- Reliability: Smaller, specialized models often perform better at specific tasks
In this tutorial, we'll walk through an example of classifying documents so you get a feel for how it works.
Model Overview
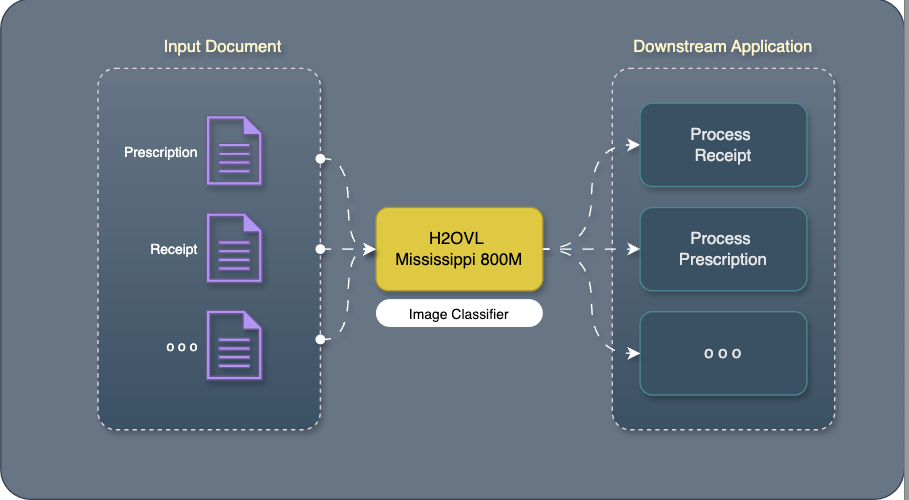
Automated document routing process for insurance claims
The H2OVL-Mississippi-800M is a vision-language model that combines text and image understanding capabilities. Key features include:
- 0.8 billion parameters, offering a good balance between performance and efficiency
- Trained on 19 million image-text pairs
- Specialized in OCR, document comprehension, and interpretation of charts, figures, and tables
- Built on H2O's Danube language model architecture
- Model Card: https://huggingface.co/h2oai/h2ovl-mississippi-800m

Setup and Dependencies
First, let's install the required packages. You'll need transformers, torch, and several other dependencies:
pip install transformers torch torchvision einops timm peft sentencepiece flash_attn
Import the necessary libraries:
import json
import re
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib.patches as patches
from PIL import Image
from sklearn.metrics import accuracy_score, confusion_matrix
import torch
from transformers import AutoModel, AutoTokenizer, AutoConfig
Loading the Model
The following code initializes the model and tokenizer:
model_path = 'h2oai/h2ovl-mississippi-800m'
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
config.vision_config.use_flash_attn = False
model = AutoModel.from_pretrained(
model_path,
torch_dtype=torch.bfloat16,
config=config,
low_cpu_mem_usage=True,
trust_remote_code=True
).eval().cuda()
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True, use_fast=False)
There are other helper functions that we use throughout this tutorial that you can find here: ![]() utils/helper.pya-ghorbani/nb-mississippi
utils/helper.pya-ghorbani/nb-mississippi
Preparing the Data
For this tutorial, we'll use a subset of the RVL-CDIP dataset, containing 15 images across three document categories. You can access these images in two ways:
- Through Kaggle: Add the rvl-cdip-small dataset to your notebook inputs
- Directly from GitHub: https://github.com/a-ghorbani/nb-mississippi/tree/main/data
Assuming you are running your notebook on Kaggle kernel, here's how we structure our data:
files = [
("/kaggle/input/rvl-cdip-small/data/invoice/0000036371.tif", "invoice"),
("/kaggle/input/rvl-cdip-small/data/invoice/0000044003.tif", "invoice"),
("/kaggle/input/rvl-cdip-small/data/invoice/0000080966.tif", "invoice"),
("/kaggle/input/rvl-cdip-small/data/invoice/0000080967.tif", "invoice"),
("/kaggle/input/rvl-cdip-small/data/invoice/0000113780.tif", "invoice"),
("/kaggle/input/rvl-cdip-small/data/news article/0000002844.tif", "news-article"),
("/kaggle/input/rvl-cdip-small/data/news article/0000011128.tif", "news-article"),
("/kaggle/input/rvl-cdip-small/data/news article/0000039666.tif", "news-article"),
("/kaggle/input/rvl-cdip-small/data/news article/0000081773.tif", "news-article"),
("/kaggle/input/rvl-cdip-small/data/news article/0000087166.tif", "news-article"),
("/kaggle/input/rvl-cdip-small/data/resume/0000000869.tif", "resume"),
("/kaggle/input/rvl-cdip-small/data/resume/0000566434.tif", "resume"),
("/kaggle/input/rvl-cdip-small/data/resume/0000279204.tif", "resume"),
("/kaggle/input/rvl-cdip-small/data/resume/0000157511.tif", "resume"),
("/kaggle/input/rvl-cdip-small/data/resume/0000279241.tif", "resume"),
]
Since we already know the target value for this dataset, we can use the utility function evaluate_model to compare the predictions with actual values. Here is an example of how you can do this:

Document Classification
Our classification approach is straightforward:
- Load each document image
- Send it to the model along with a prompt
- Parse the model's response to get the predicted category
- Compare predictions with actual labels
The prompt we use is quite simple:
"<image>\\nExtract the type of the image, categorizing it as 'invoice', 'resume', or 'news-article'. Type:"
-------------------------------------------------------------------------------------------------------------
generation_config = dict(max_new_tokens=500, do_sample=False)
prompt = "<image>\nExtract the type of the image, categorizing it as 'invoice', 'resume', or 'news-article'. Type:"
response, history = model.chat(tokenizer, image_file, prompt, generation_config, history=None, return_history=True)
Since we already know the target value for this dataset, we can use the utility function evaluate_model to compare the predictions with actual values. Here is an example of how you can do this:
model, tokenizer = initialize_model('h2oai/h2ovl-mississippi-800m')
prompt = """Extract the type of the image, categorizing it as 'invoice', 'resume', or 'news-article'. Type: """
accuracy, confusion_df, predicted_labels = evaluate_model(model, tokenizer, files, prompt)
print('Confusion Matrix: ')
print(confusion_df)
--------------------------------------------------------------------------------------------------------------
Accuracy: 100.00%
Confusion Matrix:
invoice news-article resume
invoice 5 0 0
news-article 0 5 0
resume 0 0 5
CPU times: user 50.9 s, sys: 1.34 s, total: 52.2 s
Wall time: 49.3 s
Results
Running our evaluation on the test set yields impressive results:
Accuracy: 100.00%
| invoice | news-article | resume | |
|---|---|---|---|
| invoice | 5 | 0 | 0 |
| news-article | 0 | 5 | 0 |
| resume | 0 | 0 | 5 |
The model achieved perfect accuracy on our test set, correctly classifying all 15 documents into their respective categories. While this is a small test set, it demonstrates the model's strong capability in distinguishing between different document types.
Note: It is not typically expected for a model to be 100% accurate all the time, especially since we only used 15 images. For a more comprehensive evaluation, we need to use a more diverse set of images. Nevertheless, it is still impressive to see how an 800M model can be used effectively in a broader LLM-based pipeline and for automation tasks.
In the appendix, you may find this exercise on more datasets (1000 images), with an accuracy of around 97%.
Model Performance Comparison
While the H2OVL-Mississippi-800M is significantly smaller than Qwen2 VL 2B (one of the leading vision-language models in the 2B parameter class), our benchmarks show interesting insights. Although Qwen2 VL 2B demonstrates superior capabilities across general vision-language tasks due to its larger parameter count, H2OVL-Mississippi-800M performs remarkably in specialized document classification tasks. Not only does it match or exceed Qwen2 VL 2B's accuracy in our document processing tests, but it also has substantially faster inference times - a crucial advantage for production deployments where processing speed and resource efficiency are important.
qwen_model, qwen_processor = initialize_model('Qwen/Qwen2-VL-2B-Instruct')
prompt = """Extract the type of the image, categorizing it as 'invoice', 'resume', or 'news-article'. Type: """
accuracy, confusion_df, predicted_labels = evaluate_model(qwen_model, qwen_processor, files, prompt)
print('Confusion Matrix: ')
print(confusion_df)
---------------------------------------------------------------------------------------------------------------------------------
Accuracy: 93.33%
Confusion Matrix:
invoice news-article resume
invoice 5 0 0
news-article 0 5 0
resume 0 1 4
CPU times: user 1min 24s, sys: 3.55 s, total: 1min 27s
Wall time: 1min 27s
Important Considerations and Limitations
Prompt Engineering Requirements: Smaller models like H2OVL-Mississippi-800M are more sensitive to prompt engineering than larger models. Given their relatively small size in the world of generative language models, they typically require more careful, prompt engineering to achieve optimal results. Consider:
- Being more explicit in instructions
- Including relevant examples in prompts, although you need to be concise in when working with 0.8B models
- Testing various prompt templates and iterate
For example:
"<image>/nClassify the image and categorize it as 'invoice', 'resume', or 'news-article'. Type: "
doesn't yield good results as the model tends to be more verbose that breaks the pipeline.
Data Contamination: When evaluating model performance, it's important to consider potential training data overlap. While we cannot definitively confirm whether specific rvl-cdip data was used in training Qwen2 VL models. Certain images from this dataset were part of H2OVL's training dataset (though not specifically for classification tasks). This might influence model performance and response quality, as we saw above.
As usual for production deployments, it's crucial to conduct thorough testing on truly holdout private test datasets, as it is a challenge these days to find public data that is not used in training (vision) language models.
Conclusion
The H2OVL-Mississippi-800M model proves to be highly effective for document classification tasks. Its moderate size makes it practical for deployment while maintaining excellent accuracy. The simple prompt-based approach makes it easy to adapt to different document classification needs.
For the complete code and example dataset, check out the full notebook on GitHub.
Looking Ahead
It's important to note that real-world document classification often presents more complex challenges than what we've covered in this tutorial. Many scenarios require examining multiple pages to accurately categorize a document. Conversely, we frequently encounter situations where a single scanned page contains multiple distinct documents, such as insurance claim combining receipts, prescriptions, and ID documents. Stay tuned for our next tutorial, where we'll tackle these use cases.
Resources
GitHub: https://github.com/a-ghorbani/nb-mississippi/tree/main
Kaggle Code: https://www.kaggle.com/code/aghorbania/nb-mississippi
Complete Dataset: https://www.kaggle.com/datasets/uditamin/rvl-cdip-small
Subsampled Dataset: https://github.com/a-ghorbani/nb-mississippi/tree/main/data
Appendix
Let's try running the code on more data to get better statistics regarding the accuracy measures.
files_1000 = sample_files_from_directory('/kaggle/input/rvl-cdip-small/data/', {'invoice': 333, 'news article': 333, 'resume': 334})
prompt = """Extract the type of the image, categorizing it as 'invoice', 'resume', or 'news-article'. Type: """
accuracy, confusion_df, predicted_labels = evaluate_model(model, tokenizer, files_1000, prompt)
print('Confusion Matrix: ')
print(confusion_df)
---------------------------------------------------------------------------------------------------------------
Accuracy: 96.80%
Confusion Matrix:
invoice news-article resume
invoice 332 1 0
news-article 7 318 8
resume 9 7 318
CPU times: user 1h 3min 5s, sys: 10.8 s, total: 1h 3min 16s
Wall time: 59min 50s







