







H2O LLM DataStudio: V5.0 Release: Automatically Create your own Evaluation datasets (Custom RAG Evals)

Introducing new 'Custom Eval' - Create your own evaluation datasets effortlessly from various document formats, or existing datasets.
H2O LLM DataStudio’s new Custom Eval component is a no-code capability that empowers users to generate evaluation datasets with different evaluation types (Question Type, Multichoice, Token Presence) from any unstructured data or existing datasets within their organization. Leveraging the H2OGPTe Large Language Model, Custom Eval automatically generates diverse evaluation datasets suitable for evaluating LLMs across various document types, including annual reports, presentations, audio or video files.
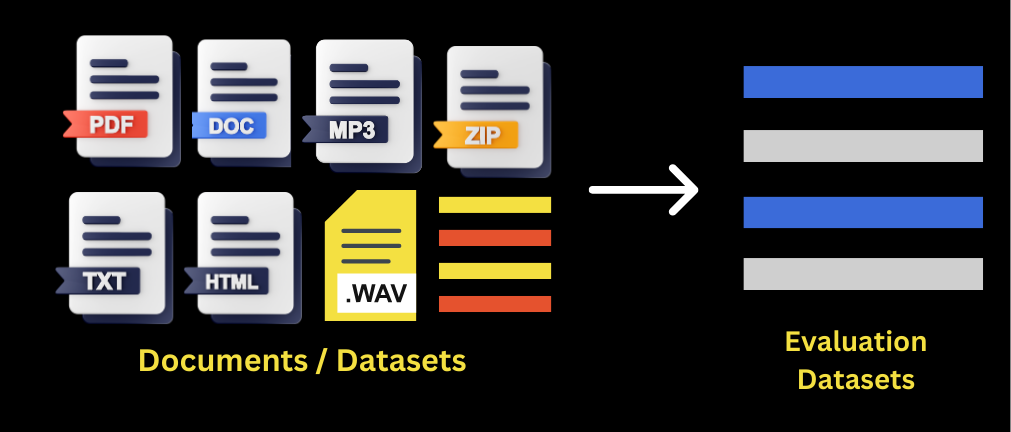
Key Functionalities of LLM DataStudio Custom Eval
1. Variety of data input
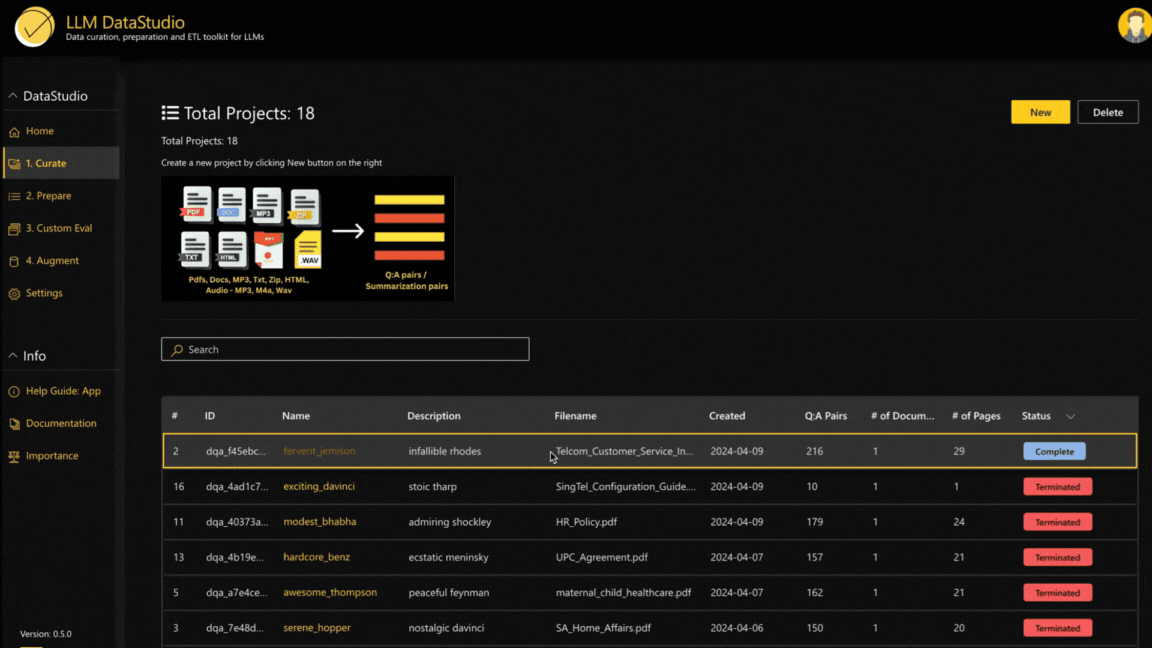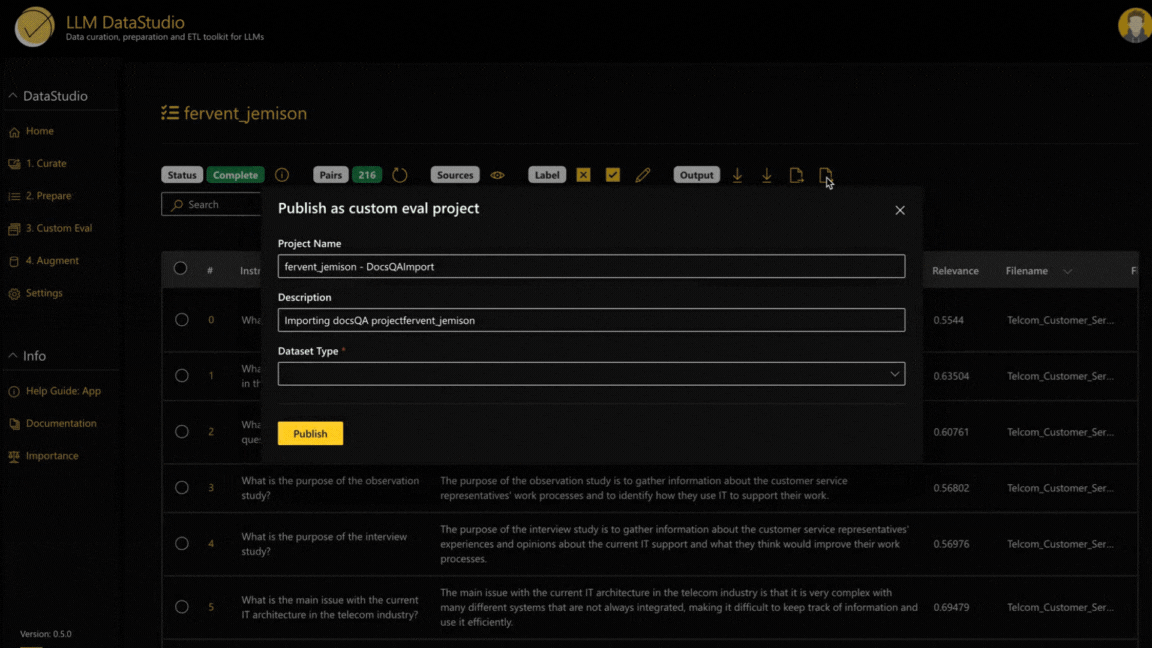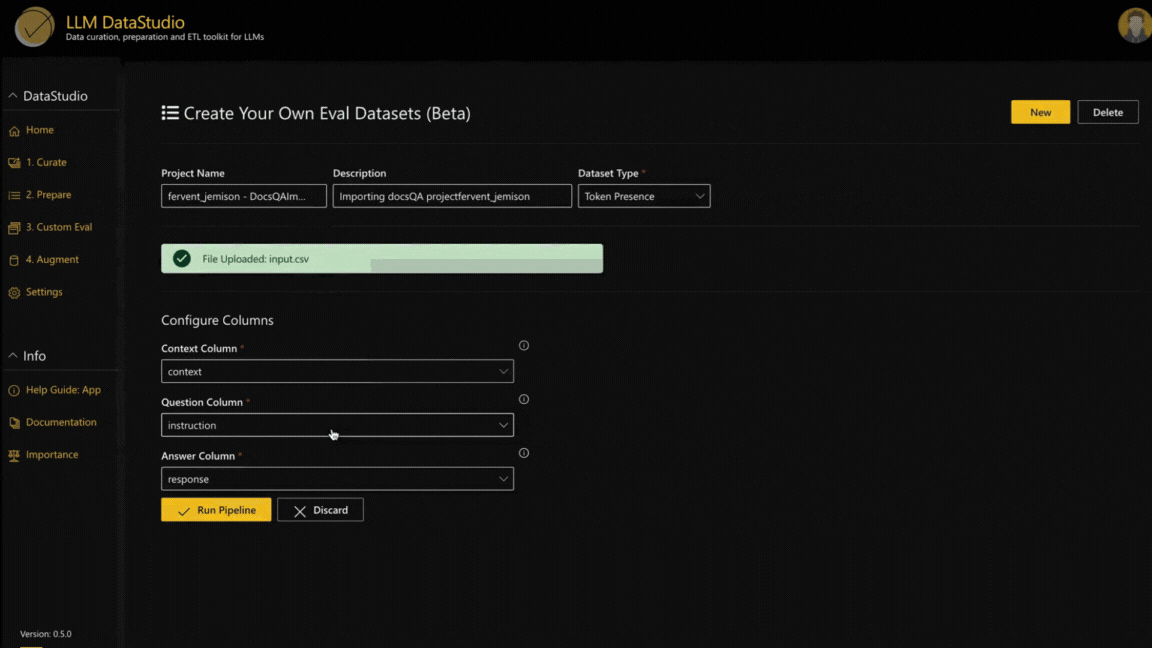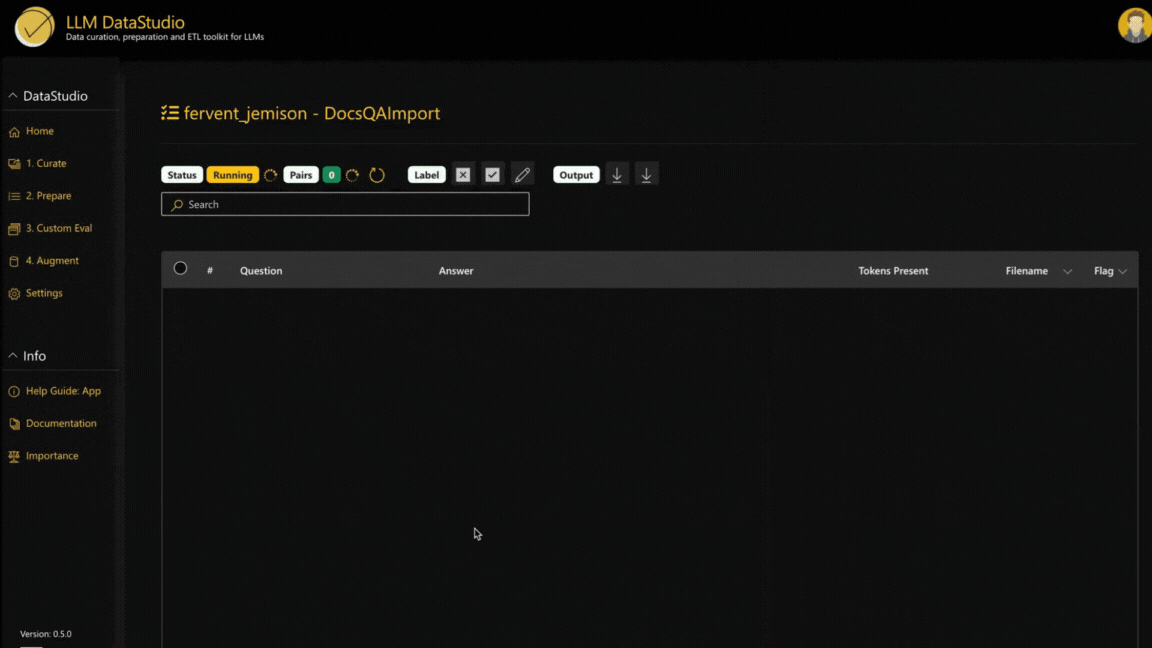
Users can utilize existing Question and Answer datasets (in CSV format) or any document in formats like PDF, DOC, audio, video files or website URLs linking to documents to create evaluation datasets.
2. Different types of evaluation dataset types
- Question Type - Generates three different types of questions with customizable distributions.
- Conditional Question: Increases question complexity by incorporating scenarios or conditions affecting the context.
- Compress Question: Makes the question more indirect and shorter while retaining its essence.
- Multihop Reasoning Question: Increases question complexity by requiring multiple logical connections or inferences.
- Multichoice - Provides multiple choices for questions, with one correct and three incorrect choices.
- Token Presence - Extract the minimum tokens necessary for accurate answers for the question.

3. View and customize the output
- Flag: Flag whether a row is relevant or irrelevant.
- Edit: Customize and update any row in the generated evaluation dataset.
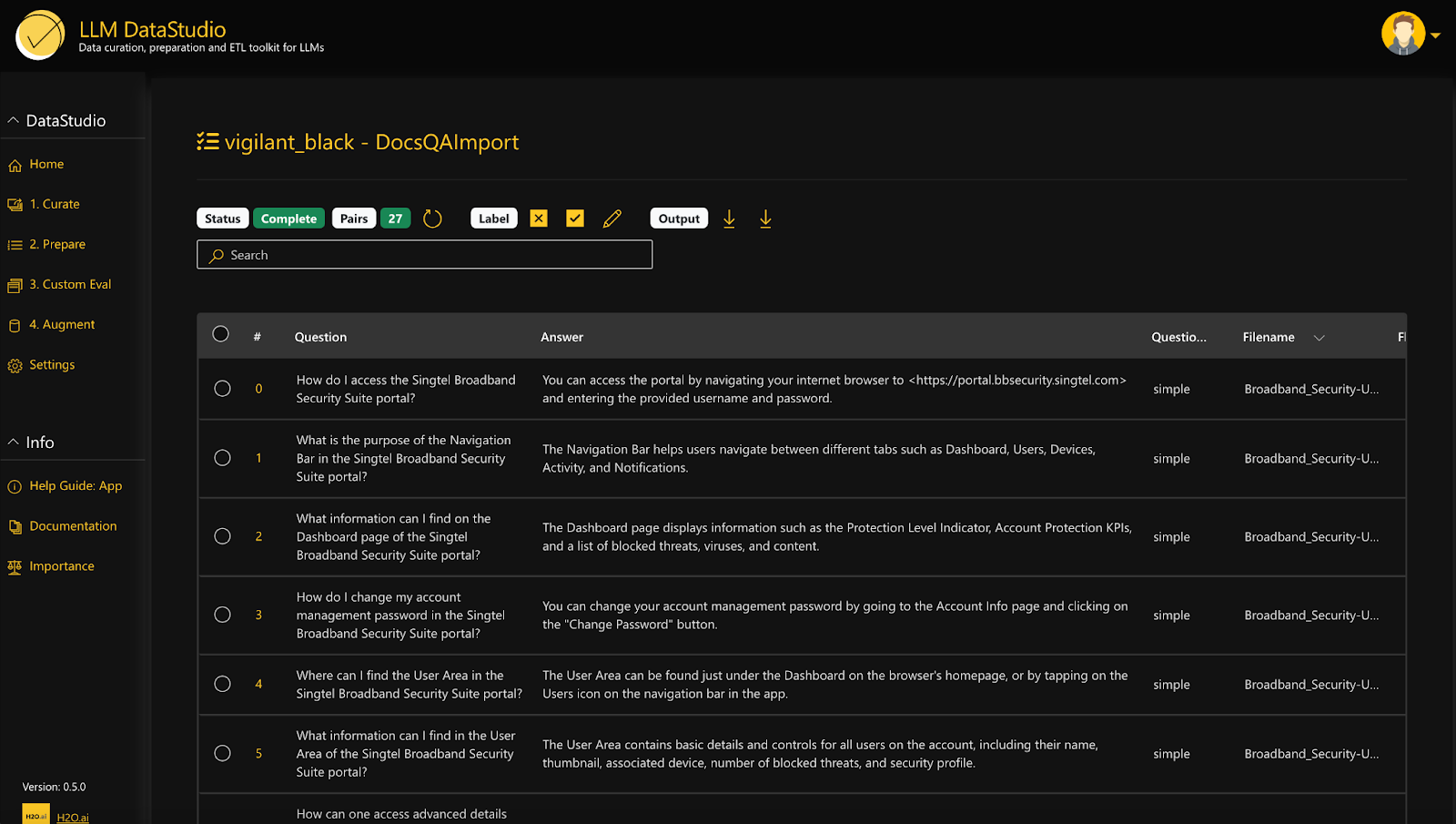
4. Download evaluation dataset
The generated evaluation dataset can be downloaded in CSV or JSON format. These evaluation datasets can be easily integrated into Eval Studio using JSON downloads.
5. Tight Integration between Curate and Custom Eval component.
The QA pairs generated using a project in the Curate component can be used to create a new project in Custom Eval and it can be used to generate the evaluation dataset of the desired evaluation type.
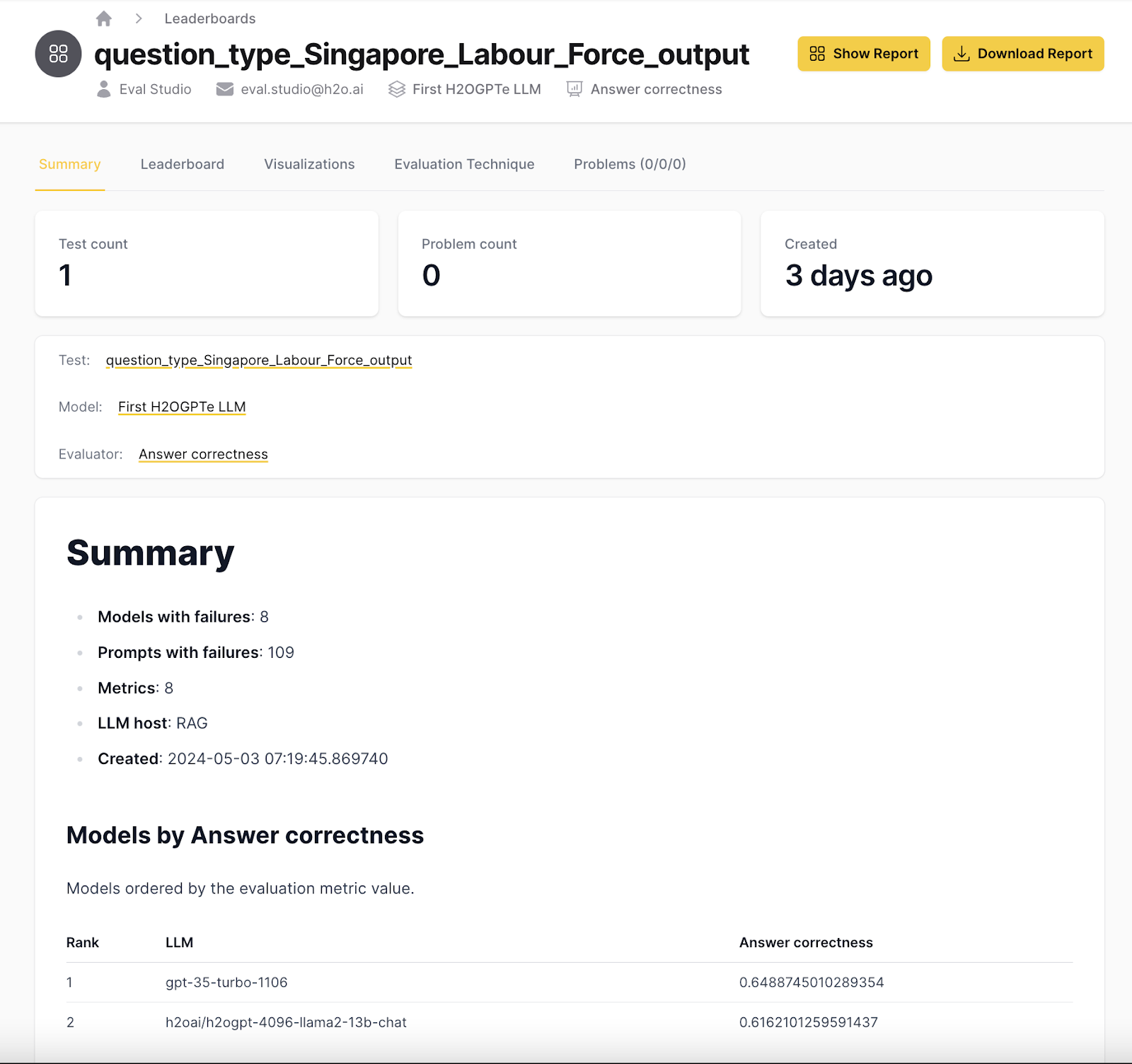
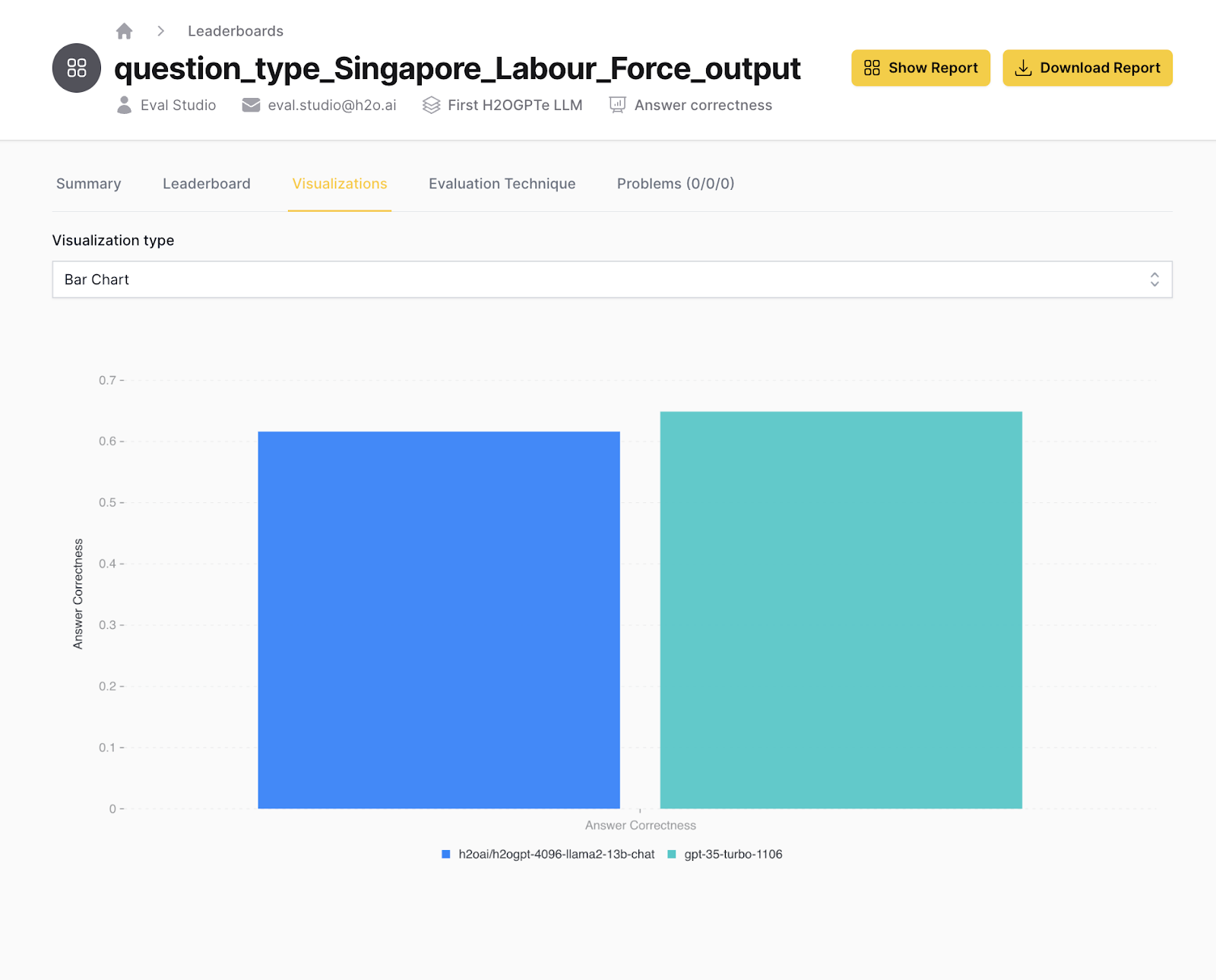
Integrate the downloaded evaluation dataset with Eval Studio
LLM DataStudio has been designed to ensure an ease of integration into H2O EvalStudio. Once you’ve finished reviewing and finalizing your eval dataset, you can take the json output and effortlessly import it into EvalStudio's "Tests" tab. From there, you can explore your test cases and documents, and launch a new leaderboard by filling in essential details like name, description, model selection and evaluator type (e.g., Answer Correctness or Token Presence).
What’s Next?
In addition to the LLM DataStudio Custom Eval, a Github Repository with the collection of evaluation datasets of different evaluation types for a range of different documents from different industries including Banking, Risk Management, Telecom, Government, Legal, Health, Finance, and Security is created. (Stay tuned as we will soon be adding 50 evaluation datasets to the repository). Examples of the different types of documents used for some of these different industries are as follows,
- Banking - Financial Statements, Annual Reports, Broker Agreements.
- Health - Healthcare Standards, Healthcare Regulations
- Legal - EU AI act, IRS Filing policy document, Contracts, Agreements
- Government - Home Affairs document, Constitution, Veterans Affairs document
- Finance - Financial records, Product Disclosure Statements
- Telecom - Technical reports, Regulation documents.
H2O LLM DataStudio Custom Eval Demo









