




Model Selection | Routing you to the best LLM

Learn how h2oGPTe routes user queries to the best LLM based on preferences for latency, cost, or accuracy for chat and retrieval augmented generation.
Welcome to Enterprise h2oGPTe, your Generative AI platform for interacting with a wide range of LLMs for chat, document question answering with Retrieval Augmented Generation, new content generation, and more. In this post, we’ll summarize a new feature in the 1.5 release that intelligently routes users to the best LLM based on their preference of latency, cost, and accuracy.
This blog post is based off of our recent Enterprise h2oGPTe feature video: Optimizing Model Selection in H2O Enterprise GPTe - Balancing Accuracy, Latency, and Cost
Model Selection: The Basics
At H2O, your data and prompts are owned by you. Each customer has their own Generative AI platform available on-premise, managed by you in your favorite cloud, or managed by us. In your platform, a wide-range of LLMs are available, ranging from small language models, like H2O Danube, to open source LLMs like LLama3.1, to private LLMs like Claude Sonnet 3.5. This list is customizable at each organization to make sure you and your uses have access to exactly the models you need! In the platform, LLM and Vision models are supported.
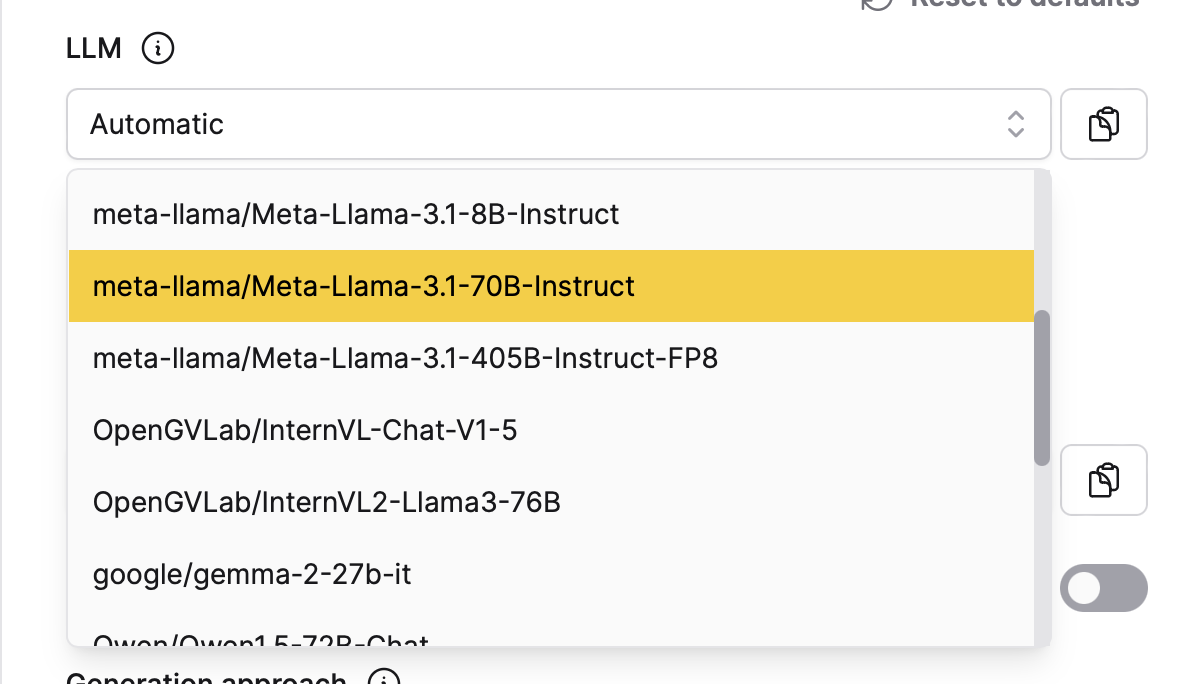
For each model in your environment, the platform is tracking the model’s accuracy on a RAG performance benchmark, the cost per tokens, and the latency of responses. Using this information, h2oGPTe automatically routes user interactions to the best LLM for their query.
Benchmarking Models: Accuracy vs. Cost
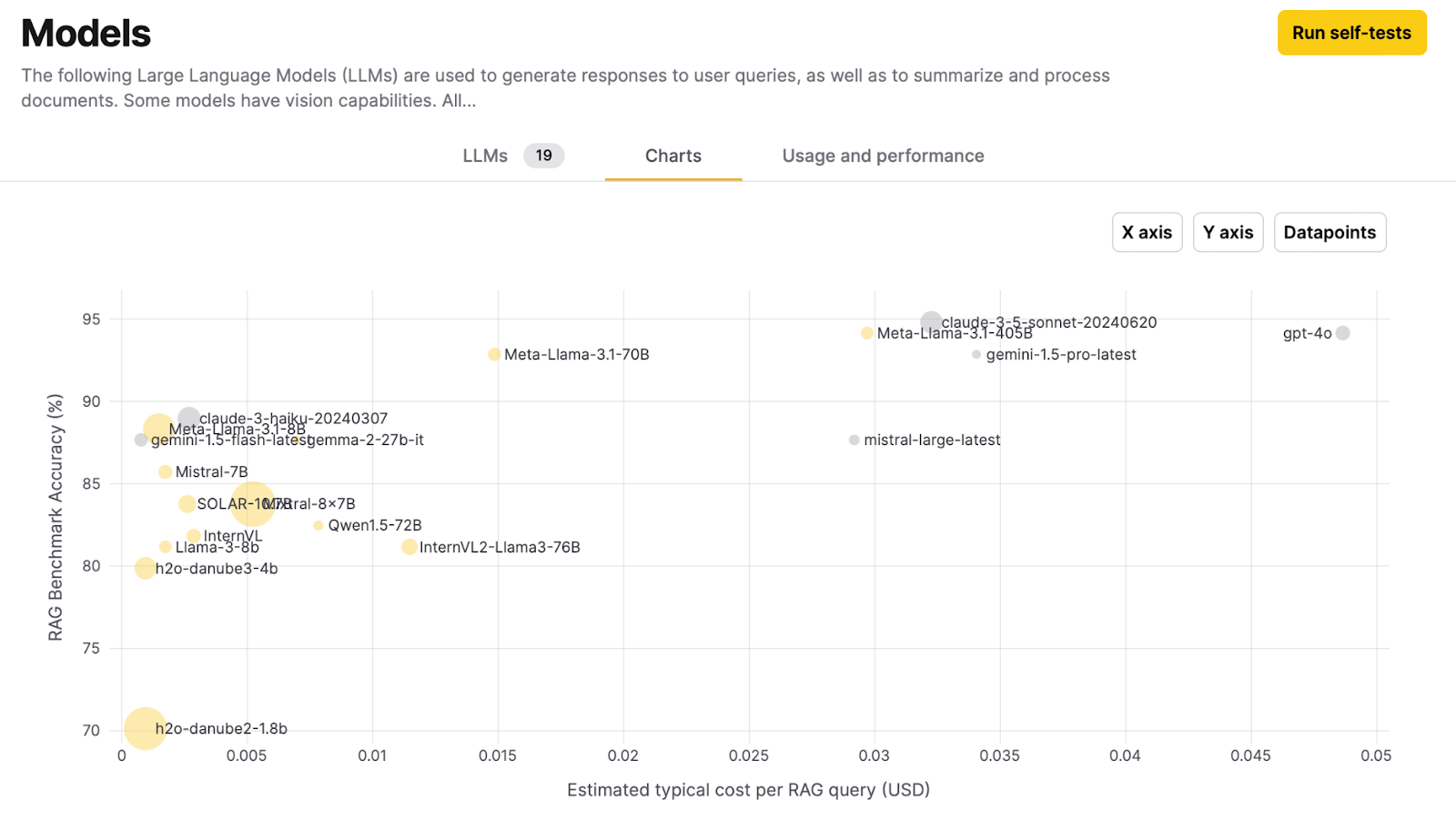
h2oGPTe’s model selection process involves benchmarking various models against each other. The accuracy of standard RAG benchmarks is plotted on the Y-axis, while the estimated typical cost of a query is shown on the X-axis. This allows users to understand the trade-offs between accuracy and cost when manually selecting a model.
On this Model’s page, users can change the metrics they would like to compare so they can understand the tradeoff between quantitative measures like cost, max output token length, speed, and more.
Considering Latency
Latency is another crucial factor when choosing a model. While third-party hosted models usually have consistent latency, hosted models like Llama3.1 may experience increased latency during periods of high demand at your organization. In such cases, users can opt for faster models like Mixtral, even if they're slightly less accurate.
Automatic Routing and Customization
h2oGPTe automatically selects the best model for your needs based on the preference for speed, accuray, and cost set by the platform admin or overwritten by the individual user. However, users can specify a preferred model or adjust the importance of speed, cost, and accuracy in the configuration settings. The default settings are determined by the system admin of your organization.
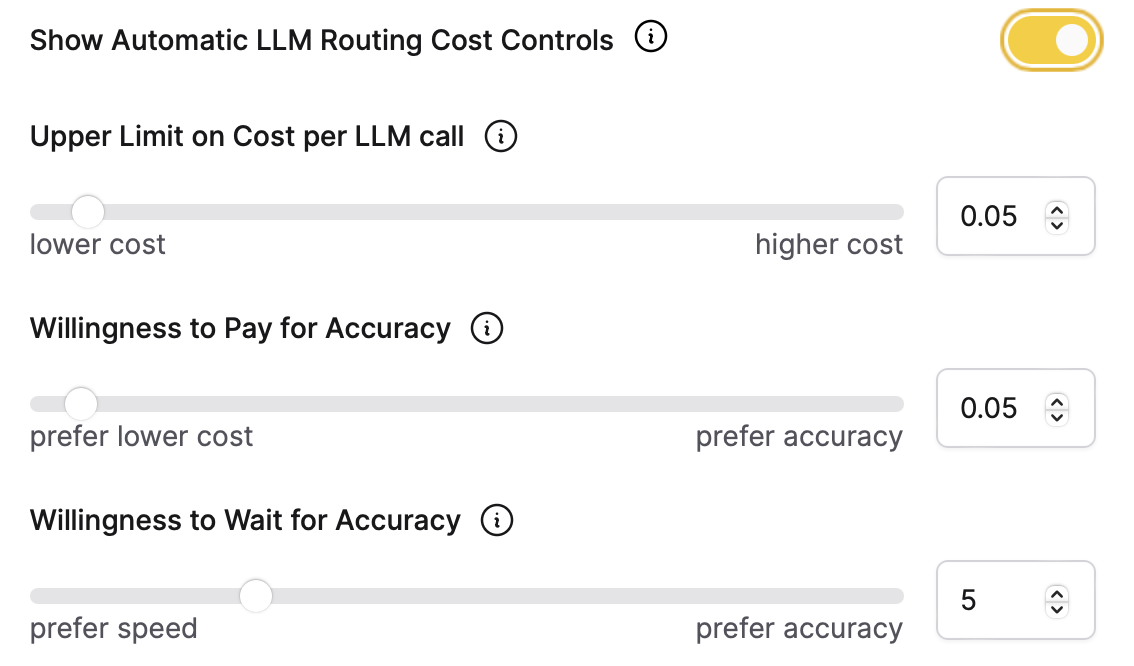
Prioritizing Accuracy in Important Projects
If cost is not a concern for a particular project, users can adjust the preference settings to prioritize accuracy. This will result in the system using more accurate models more frequently.
Wrapping Up
h2oGPTe’s new features and capabilities offer users an efficient and intelligent way to interact with large language models and leverage retrieval-augmented generation. By considering factors like accuracy, cost, and latency, H2O GPTe ensures that users get the most suitable model for their needs, ultimately leading to better decision-making and more productive conversations.
Try it out today in our Freemium environment at h2ogpte.genai.h2o.ai - just login with your personal Gmail or Github ID.







