




'Ask Craig'- Determining Craigslist Job Categories with Sparkling Water, Part 2

This is the second blog in a two blog series. The first blog is on turning these models into a Spark streaming application
The presentation on this application can be downloaded and viewed at Slideshare
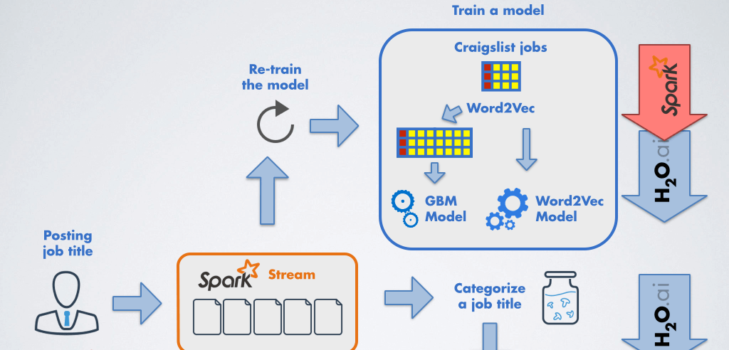
In the last blog post we learned how to build a set of H2O and Spark models to predict categories for jobs posted on Craigslist using Sparkling Water.
This blog post will show how to use the models to build a Spark streaming application which scores posted job titles on the fly.

The last blog post produced two models – H2O’s GBM model and Spark’s Word2Vec model.
We will use both models and construct a Spark stream which accepts messages containing a job title.
The stream will transform each incoming job title by the Word2Vec model into a feature vector , and then use GBM model to score the vector and predict a job category.
So let’s build a streaming application!
The first step is to get prepared models and extract additional information – in this case svModel represents GBM model, and w2vModel is Word2Vec model (see previous blog post ).
// Build model
val (svModel, w2vModel) = buildModels(/* See previous blog post */)
val modelId = svModel._key.toString
// Collect output categories
val classNames = svModel._output.asInstanceOf[Output].classNames()
In the next step, we create a Spark streaming context which will handle batches of messages every 10 seconds. When the context is ready we can create a Spark socket stream which will be exposed on the port 9999:
// Create Spark streaming context
val ssc = new StreamingContext(sc, Seconds(10))
// Start streaming context
val jobTitlesStream = ssc.socketTextStream("localhost", 9999)
Now, we have to define stream transformation which will handle a batch of messages. The good thing is that Spark stream API exposes similar methods as regular Spark RDD. In our case each non-empty message is classified and result is transformed into user-friendly message. The stream definition is finished by the print call which outputs results in periodic intervals.
// Classify incoming messages and print them
jobTitlesStream.filter(!_.isEmpty)
.map(jobTitle => (jobTitle, classify(jobTitle, modelId, w2vModel)))
.map(pred => "\"" + pred._1 + "\" = " + show(pred._2, classNames))
.print()
To finish stream definition we have to define two additional methods classify and show. The classify method tokenizes a given job title, applies the Wor2Vec model to produce a feature vector representing the title and then uses GBM model to classify the job title. The method returns a predicted job class and array of probabilities for individual classes:
def classify(jobTitle: String, modelId: String, w2vModel: Word2VecModel): (String, Array[Double]) = {
val model = model = water.DKV.getGet(modelId)
val tokens = tokenize(jobTitle, STOP_WORDS)
if (tokens.length == 0)
("NA", Array[Double]())
else {
val vec = wordsToVector(tokens, w2vModel)
hex.ModelUtils.classify(vec.toArray, model)
}
}
The method show simply generates a user friendly string representation of predicted job class:
def show(pred: (String, Array[Double]), classNames: Array[String]): String = {
val probs = classNames.zip(pred._2).map(v => f"${v._1}: ${v._2}%.3f")
pred._1 + ": " + probs.mkString("[", ", ", "]")
}
The stream definition can contain additional definition which
terminates stream if a “poision” message is received:
// Shutdown app if poison pill is passed as a message
jobTitlesStream.filter(msg => POISON_PILL_MSG == msg)
.foreachRDD(rdd => if (!rdd.isEmpty()) {
println("Poison pill received! Application is going to shut down...")
ssc.stop(true, true)
sc.stop()
H2O.shutdown()
})
Now we are ready to launch the application!
We need to submit it to Spark cluster:
> $SPARK_HOME/bin/spark-submit --master "local[*]" --packages ai.h2o:sparkling-water-core_2.10:1.3.6,ai.h2o:sparkling-water-examples_2.10:1.3.6 --class org.apache.spark.examples.h2o.CraigslistJobTitlesStreamingApp /dev/null
And then launch an event producer – in this case we are going to use NetCat:
> nc -lk 9999
Now, we can send job titles directly from NetCat terminal. For example:
Sales manager P/T
And application will output:
-------------------------------------------
Time: 1435822700000 ms
-------------------------------------------
"Sales manager P/T" = administrative: [accounting: 0.087, administrative: 0.538, customerservice: 0.261, education: 0.010, foodbeverage: 0.071, labor: 0.033]
You can find full source of the example in Sparkling Water GitHub – CraigslistJobTitlesStreamingApp .
Enjoy and let us know how it works for you!
-Michal and Alex