Driverless AI can help you choose what you consume next

Last updated: 09/06/19
Steve Jobs once said, “A lot of times, people don’t know what they want until you show it to them’. This makes sense, especially in this era of constant choice overload. Consumers today have access to a plethora of products just at the click of their mouse. These innumerable choices can sometimes turn out to be confusing and hampering and do more harm than good. For instance, a company may offer millions of products on its website, but how does a consumer find a new and appealing product from amongst those? Also, wouldn’t it be great if the company could provide choices to every consumer based on their past shopping history? This would not only save a lot of time but also provide them with highly personalized experiences. Such a customized filter relying on modern machine learning techniques constitutes a Recommendation System, and we shall see how Driverless AI can be used to create one.
Recommender Systems
Recommendation Engines try to make a product or a service recommendation to people. In a way, Recommenders try to narrow down choices for people by presenting them with suggestions that they are most likely to buy or use. A lot of companies today depend on their recommendation engines to help users discover new content on their sites.
Please note that in this article, the terms recommendation engine, recommender system and recommendation system will be used interchangeably and signify the same underlying idea.
Benefits of using Recommendation systems
By using an effective Recommendation System in place, companies can target and personalize content and product recommendations for its consumers. This results in increased customer engagement, increased loyalty, and hence increased sales. Some of the businesses that can benefit from effective recommendation systems are:
Some of the businesses that stand to gain from Recommendation Systems:
Types of Recommender Systems
There are many kinds of recommenders being employed in the industry today. The vital decision, however, is to decide which type suits our needs and what kind of data is available with us. The selection primarily depends on :
- What we want to identify and,
- What kind of relationship is specified in our data?
Some of the common approaches used for recommendations include:
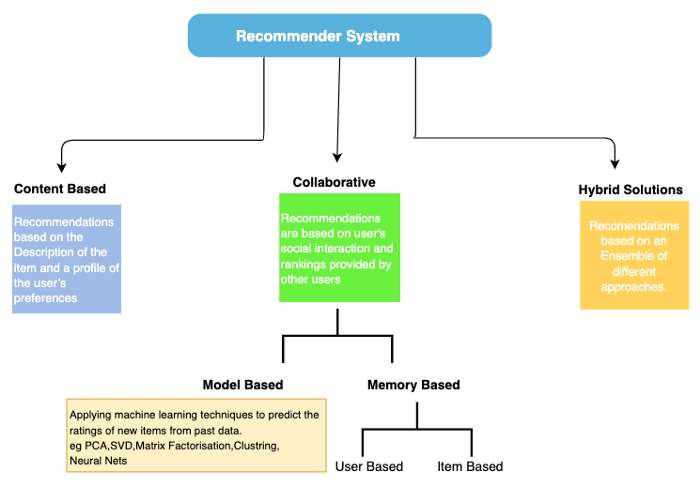
Approaches used for Recommendation systems
Let’s have a brief overview of each one of them:
1. Content-Based Filtering
Content-based filtering involves recommending items based on the attributes of the items themselves. Recommendations made by content-based filters use an individual’s historical information to inform choices displayed. Such recommenders look for similarities between the items or products that a person had bought or liked in the past to recommend options in the future. The system recommends items similar to what a user has liked in the past.

The diagram above(source) shows that if a user likes a book in the ‘Literature’ category, it makes sense to recommend books in the same category to the user. Also, recommending books released in the same year and by the same Author would also be a great idea.
2. Collaborative Filtering
Collaborative filtering uses the combined power of ratings provided by many users/customers to present recommendations. Collaborative filtering relies on the user-item interaction and relies on the concept that similar users like similar things, e.g., customers who bought this item also bought this.
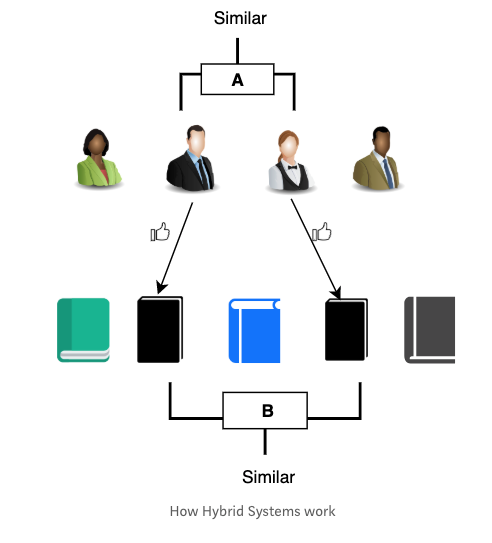
3. Hybrid Filtering
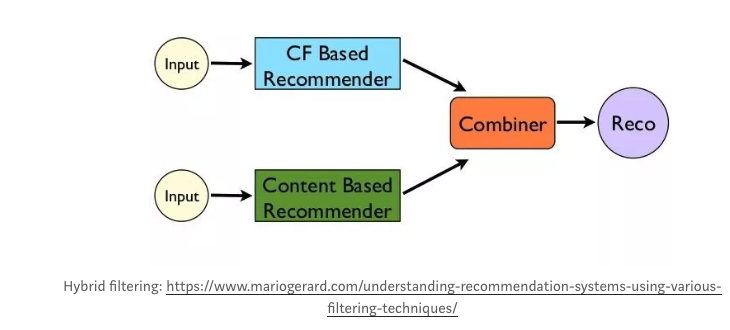
Both Content-based and Collaborative approaches have their strengths and weaknesses, and one can end up with a better system by combining many algorithms in what we call a hybrid approach. Hybrid systems leverage both item data and transaction data to give recommendations.
For instance, in the figure below, recommendations are not only based on what people’s reading and searching habits(collaborative systems)but books sharing similar characteristics(content-based) are also recommended.
Creating a Recommender system using Driverless AI
H2O Driverless AI is an artificial intelligence (AI) platform for automatic machine learning. Driverless AI automates some of the most challenging data science and machine learning workflows such as feature engineering, model validation, model tuning, model selection, and model deployment.
Driverless AI(1.7.0 and above) implements a key feature called BYOR, which stands for Bring Your Own Recipes. Recipes are customizations and extensions to the Driverless AI platform. One can create their own recipes, or select from several recipes available in the https://github.com/h2oai/driverlessai-recipes repository. We shall use one of the available recipes to develop a Recommender system with Driverless AI.
Objective
Let’s build a Movie Recommender system. The system has no prior knowledge of the users or the movies but only the interactions that users have with the movies through ratings given by them. The idea is to learn from data and recommend best movies to users, based on self and others’ behavior.
It is important to note here that this is a regression problem. However, where we would want to predict if the user will buy a particular item or not, it will be a classification problem.
Dataset
The dataset belongs to the famous Movielens site. MovieLens helps you find movies you will like. One can rate the movies to build a custom taste profile, and then MovieLens recommends other movies for you to watch.
The original data contains over 20 million ratings from 138,000 thousand randomly-chosen, anonymous users. However, for this article, we shall only be using a portion of the original data so that others can quickly reproduce the experiment. The sampled dataset data can be accessed from here. Here are the first few rows of the training data:
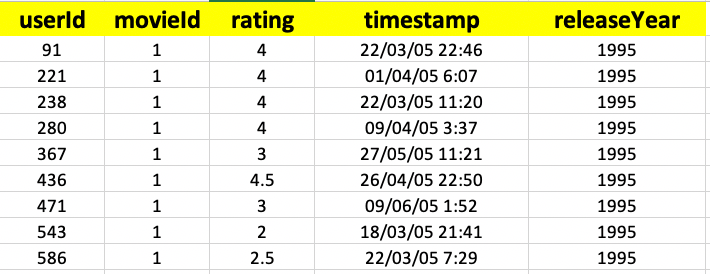
First few rows of the training data
- userId: Customer IDs
- movieId: Unique ID for every movie
- rating: On a scale from 1 to 5. This is also the Target variable.
- timestamp: Date and time on which the ratings were given.
- releaseYear: The year in which the movie was released.
Driverless AI Recommender System recipes can be used to create Collaborative, Content-based as well as Hybrid Recommender systems.
Collaborative Filtering Methodology
Let’s briefly go over the methodology of the Collaborative Filtering Recipe.
1. Uploading data into Driverless AI
The training and testing data is loaded into a new Driverless AI instance. A collaborative filtering model requires data to be in the form of a user-itemor “utility” matrix where each cell represents a user’s degree of preference towards a given item. Hence, we shall only use the following columns from the dataset for implementing collaborative filtering where the rating is the target column.
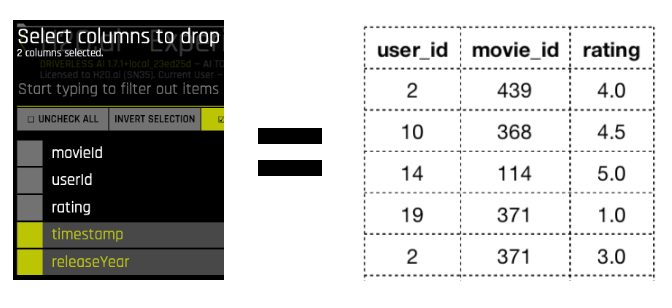
Columns selected for Collaborative Filtering
2. Uploading Custom recipes
Download the recommendation recipe file from the Github Repository on to your local system. Make sure to edit the user column name and item column name in the transformer initialization, to match the column names in the dataset. Since the user and item in the Movielens dataset are mentioned as userId and movieId respectively, we shall replace the user and item in the code file with them.

Recommender recipe
Edit these values in the code file, save it and then upload the recipe to the Driverless AI experiment as follows:
Uploading Custom recipe
Next, select only the RecH2OMFTransformer and deselect all the other transformers by navigating to Expert Settings>Recipes>include specific Transformers.
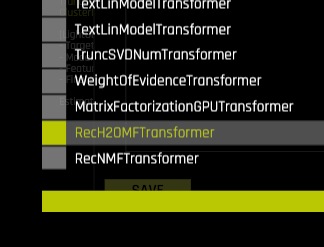
Selecting RecH2OMF Transformer
Select Regression as experiment type and RMSE as the scorer and launch the experiment.

Collaborative Filtering Experiment in Driverless AI
Let’s try and understand very briefly, what the Matrix Factorization transformer does under the hood.
- It first converts the movie rating dataframe into an user-item matrix, also called a utility matrix as follows:
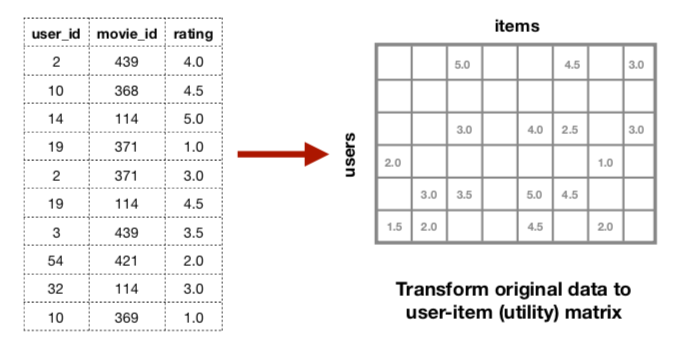
Every cell of the matrix is populated by the ratings that the user has given for the movie. It factors a sparse rating matrix X (m by n, with N_z non-zero elements) into an m-by-kand a k-by-f matrix, where Latent factors are represented by K. This reconstructed matrix populates the empty cells in the original user-item matrix, and so the unknown ratings in the sparse matrix are now known.
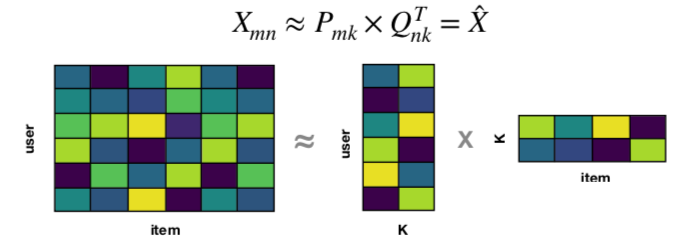
- Implementing the MF technique through H2O4GPU
Matrix Factorization is a commonly used technique in collaborative filtering for decomposing the user-item interaction matrix into the product of two lower dimensionality rectangular matrices. The idea behind matrix factorization is to represent users and items in a lower-dimensional latent space.

In Driverless AI, the Matrix Factorization technique is implemented through h2o4gpu.solvers.factorization module. H2O4GPU is an open-source project consisting of a collection of GPU solvers by H2Oai with APIs in Python and R. The Python API builds upon the easy-to-use scikit-learn API and its well-tested CPU-based algorithms.h2o4gpu.solvers.FactorizationH2O implements Matrix Factorization on GPU with Alternating Least Square(ALS) algorithm.
Content-Based Filtering Methodology
Content-based filtering involves recommending items based on the attributes of the users and the items themselves. Therefore this time, we shall include all the columns of the given training data except the timestamp column.
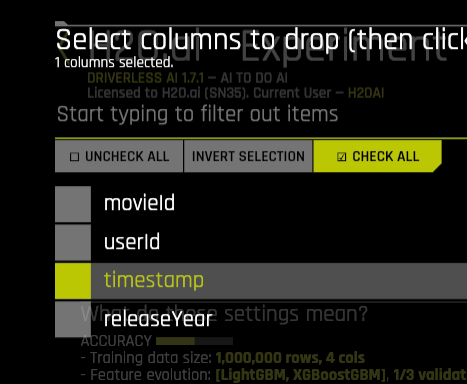
Next, we shall deselect the RecH2OMFTransformer while keeping all the default ones intact. Keeping all the other parameters, the same as the previous experiment hit the launch button.

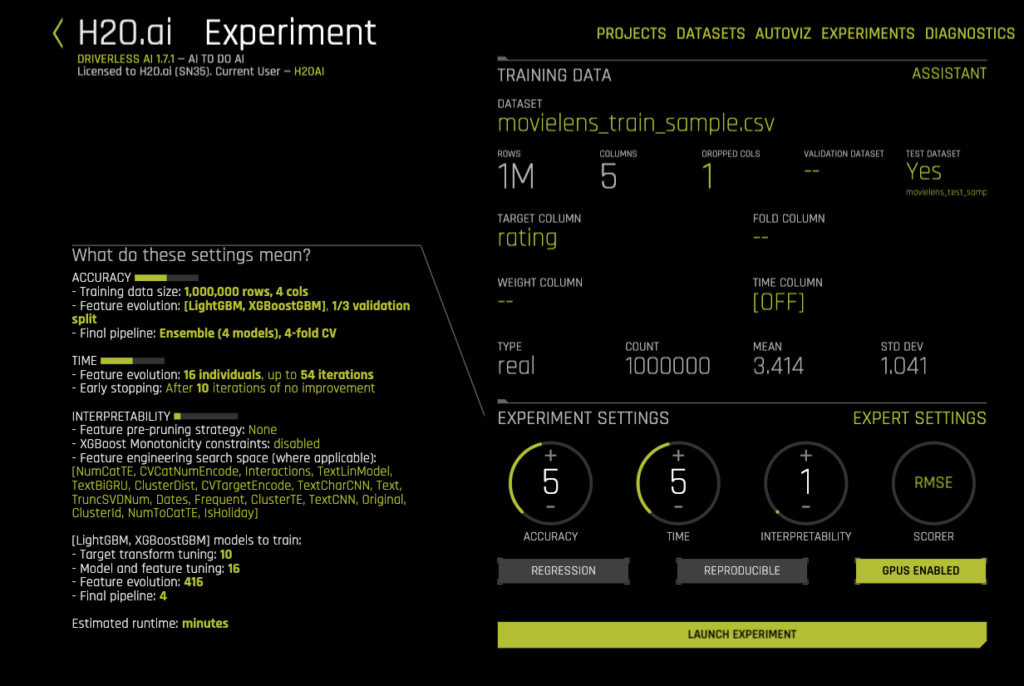
Hybrid Filtering Methodology
As the name suggests, a Hybrid Filtering method combines the properties of both Content-Based and Collaborative filtering methodologies to leverage both user-item and transaction data to give recommendations. For this experiment also, we shall select all the columns of the dataset(except the timestamp column) similar to Content-based experiment. However, the difference here will be that we shall choose the RecH2OMFTransformer in addition to the other default transformers.

Make sure the RecH2OMFTransformer is reflected along with other selected transformers on the experiment page. Go ahead and launch the experiment. Driverless AI will build multiple features using the various transformers and try multiple models to optimize the weights between the content-features and collaborative-features.
Experiment Results Summary
The screenshot below shows the comparison between the Collaborative, Content-Based, and Hybrid Recommender System’s results.

The pure collaborative approach has an RMSE of 0.96 while the content-based approach has an RMSE of 0.94. The hybrid approach combines both and clearly outperforms each with an RMSE of 0.92.
It is also interesting to note that XGBoost scores 0.98 on the raw features while LightGBM scores 0.99 on the same MovieLens dataset. Therefore, it is safe to conclude that Driverless AI’s recommendation recipes combined with its feature engineering and model-optimization perform better as compared to using plain open-sourced algorithms.
Top N recommendations
Once the experiment is done, users can download the predictions, just like any other Driverless AI experiment.

We can then sort all of the predicted ratings and get the top N recommendations for the user. We would also want to exclude or filter out items that a user has already interacted with before. In the case of movies, there is no point in recommending a movie that a user has previously watched.
Conclusion
Recommendation systems provide an effective form of targeted marketing by creating a personalized shopping experience for each customer. They are an indispensable part of any modern customer service, thereby driving user engagement. Driverless AI makes it easy for any utility to incorporate a recommender System in their business. Go through the following resources to know more :
- Learn more about Driverless AI from the H2O.ai website
- Learn more about the Bring your own Recipe feature
- Hands-on tutorial for uploading and working with recipes
Acknowledgments
- Rohan Rao: The Kaggle Grandmaster behind Recommender System recipes
- Mark Landry and Sudalai Rajkumar for reviewing the article.