







H2O Release 3.36 (Zorn)
There’s a new major release of H2O, and it’s packed with new features and fixes! Among the big new features in this release are Distributed Uplift Random Forest, an algorithm typically used in marketing and medicine to model uplift, and Infogram, a new research direction in machine learning that focuses on interpretability and fairness in Admissible Machine Learning. This release also brings improvements to our existing algorithms, with the main focus on RuleFit, Model Selection, and AutoML . There are also many technical improvements under the hood, such as improvements in MOJO import and Java version support.
This release is named after Max Zorn .
New Algorithm: Distributed Uplift Random Forest
Distributed Uplift Random Forest (Uplift DRF) is a classification tool for modeling uplift: the incremental impact of a treatment. This tool is very useful in marketing and medicine, and this machine learning approach is inspired by the A/B testing method.
To model uplift, the analyst needs to collect data before the experiment, then divide the objects into two groups. The first group, or treatment group, receive some type of treatment (for example, the customers in this group get some type of discount). The second group, or control group, is separated from the treatment (the customers in this group get no discount). Then, the data are prepared and an analyst can gather information about the response: in this case, whether the customers bought a specific product.
There are several approaches to model uplift: Meta-learner algorithms, Instrumental variables algorithms, Neural-networks-based algorithms, and, last but not least, Tree-based algorithms. Uplift DRF is a tree-based algorithm, which means in every tree, it takes information about treatment/control group assignment and information about response directly into a decision about splitting a node. The uplift score is the criterion to make said decision (similar to the Gini coefficient in the standard decision tree).
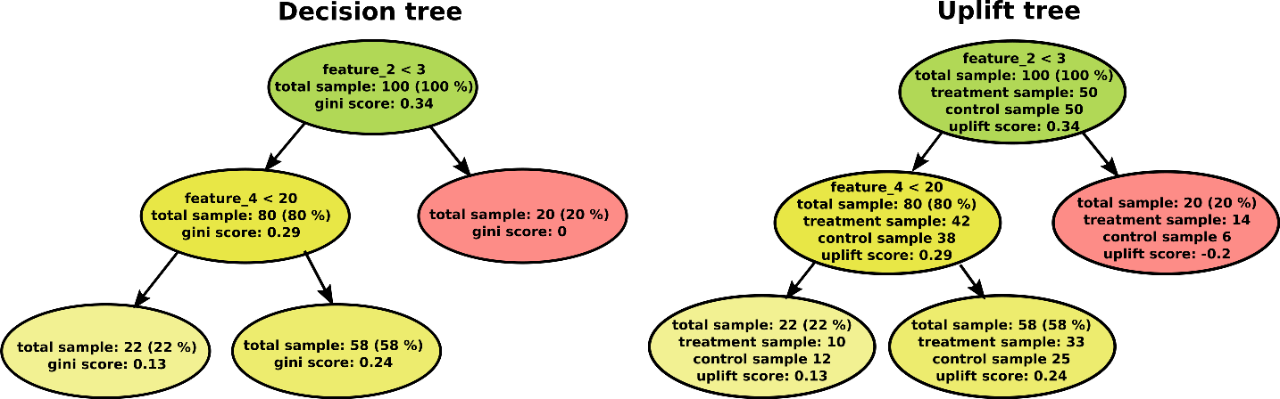
The current implementation of Uplift DRF is based on DRF because the principle of training is similar to DRF. Uplift DRF generates a forest of classification uplift trees, rather than a single classification tree. Each of these trees is a weak learner built on a subset of rows and columns. More trees will reduce the variance. Classification takes the average prediction over all of their trees to make a final prediction.
Currently, only binomial trees are supported, as well as the uplift curve metric and Area Under Uplift curve (AUUC) metric. We are working on adding regression trees and more metrics (for example, the Qini coefficient, normalized AUUC, and more).
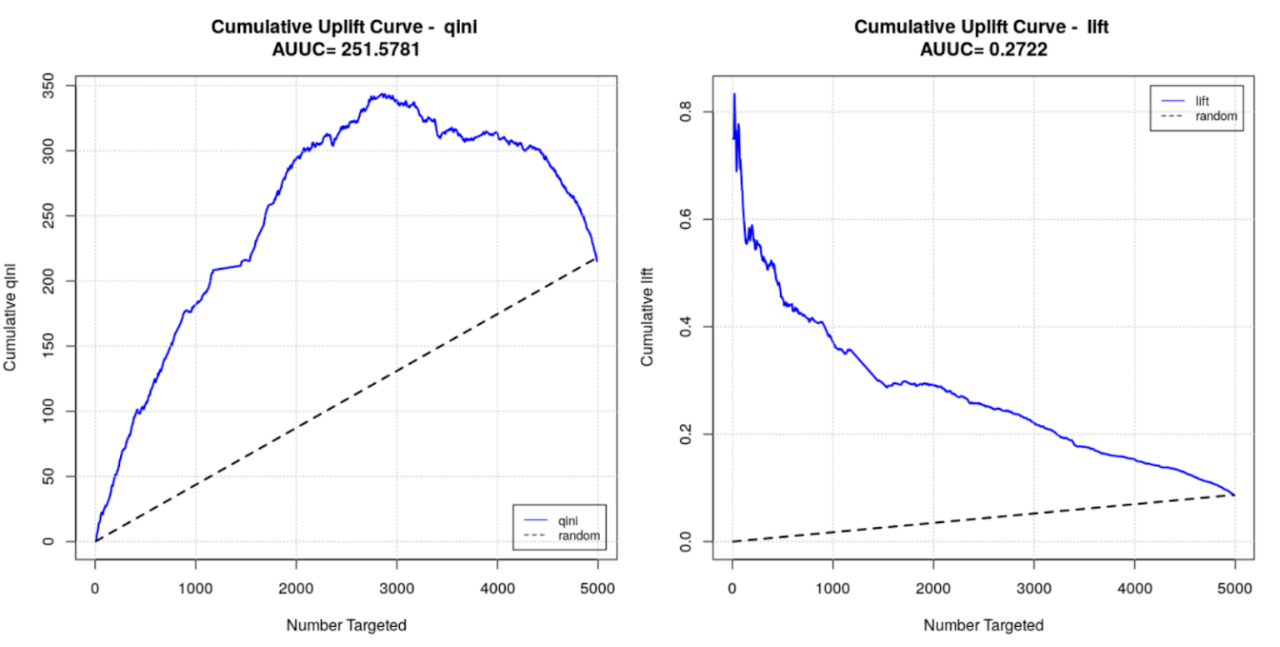
You can find a demo on uplift where H2O Uplift DRF is compared to implementation Uplift RF from CausalML library here . You can also read more about Uplift DRF in the User Guide .
New Algorithm: Infogram & Admissible Machine Learning
We have developed new tools to aid in the design of admissible learning algorithms which are efficient (enjoy good predictive accuracy), fair (minimize discrimination against minority groups), and interpretable (provide mechanistic understanding) to the best possible extent. The infogram is a graphical information-theoretic interpretability tool which allows the user to quickly spot the core, decision-making variables that uniquely and safely drive the response in supervised classification problems. The infogram can significantly cut down the number of predictors needed to build a model by identifying only the most valuable, admissible features.
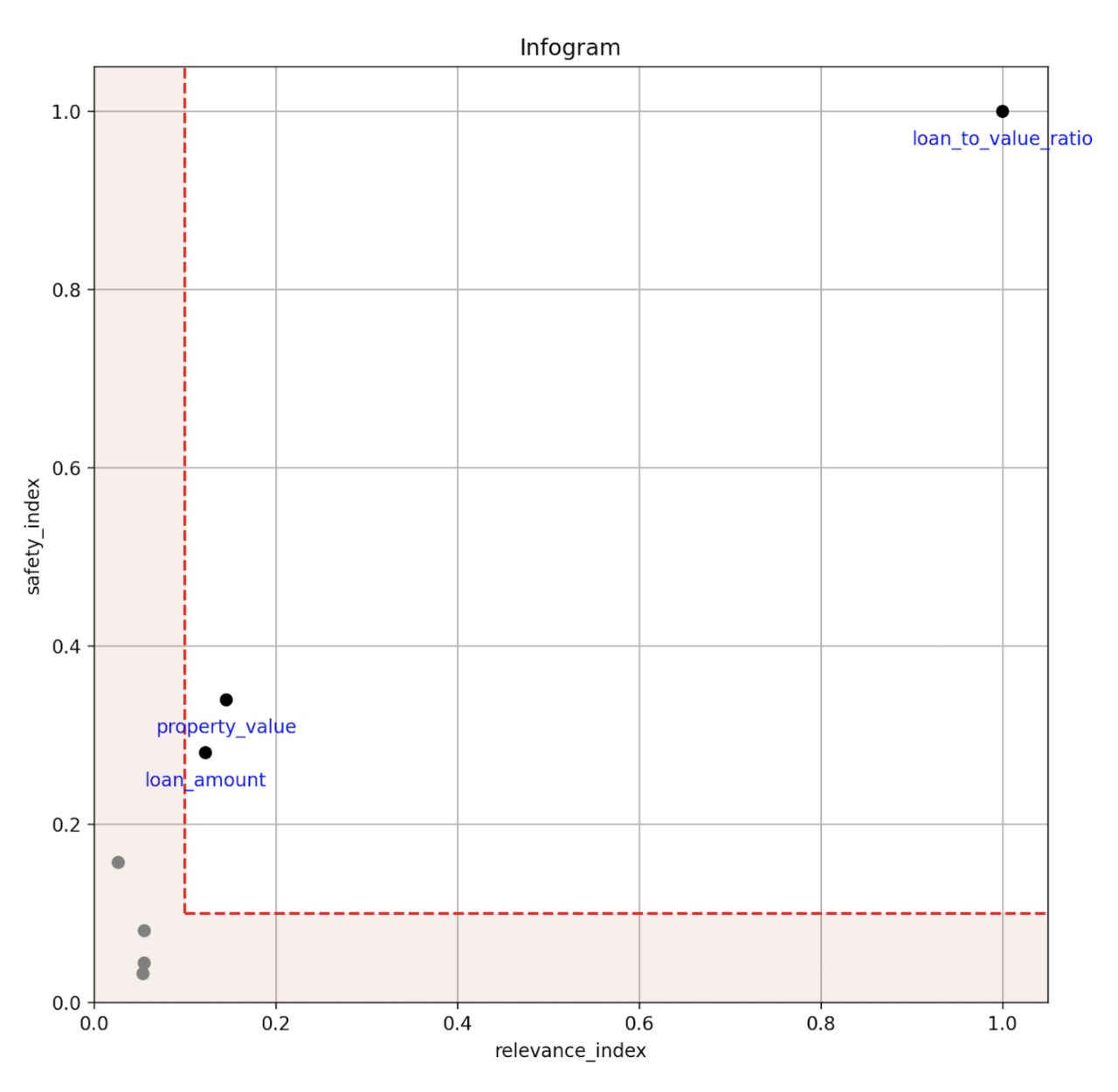
When protected variables such as race or gender are present in the data, the admissibility of a variable is determined by a safety and relevancy index, which serves as a diagnostic tool for fairness. The safety of each feature can be quantified, and variables that are unsafe will be considered inadmissible. Models built using only admissible features will naturally be more interpretable given the reduced feature set. Admissible models are also less susceptible to overfitting and train faster, often while providing similar accuracy as models built using all available features.
You can read more about Admissible ML in the User Guide .
RuleFit Improvements
RuleFit has improved since the last major release through tuning both the multinomial classification algorithm and the model output. We extended the output with rule support which represents the proportion of training observations to which the rule applies. This represents another factor of rule importance apart from the LASSO coefficient. The h2o.predict_rules() method was added to be able to evaluate the validity of the given rule(s) on the given data. This offers an even more detailed look and is applicable similarly to the already existing h2o.predict_leaf_assignment() method. RuleFit was also optimized in such a way that rules do not contain redundancies anymore, making the model output more compact. Apart from that, automatic rule duplicities processing was added. The lambda parameter for LASSO was also exposed to have better control over regularization strength when our automatic setup is not fully satisfying.
Stay tuned for future improvements — specifically RuleFit-specific tools for importance and interaction examination!
Model Selection
The ModelSelection toolbox aims to help users select the best predictor subsets to use when building a GLM regression model. Given a maximum subset size K, ModelSelection will build K models with the best predictor subset of size 1, 2, 3, …, K based on the R2 value. If you set mode='allsubsets', ModelSelection will return the best predictor subsets of size 1, 2 …, K and is guaranteed to have the highest R2 value. For a given subset size, subsets of all combinations are considered. However, this method is not scalable due to its computation complexity. If you set mode='maxr', ModelSelection will return the best predictor subsets of size 1, 2 …, K but is not guaranteed to have the highest R2 value. A sequential replacement method is used to choose the predictor subset for mode='maxr'. This method is scalable but may not always return the predictor subset with the highest R2 value.
Technical Improvements
Support of Java 17
This release of H2O-3 adds official support for the latest version of Java 17 LTS. Production-ready binaries of Java 17 have been out since September 2021 and will be actively supported until 2026 or later . As you may know, the cadence of Java releases is pretty heavy. Since Java 18 is scheduled for March 2022, we prepared the sys.ai.h2o.debug.allowJavaVersions parameter which allows you to experiment with H2O-3 on the latest Java version the very day a new version is released. Be advised that this option is only for power users, and we cannot guarantee anything without official support from our side.
MOJO Import
Importing (older) MOJO models into newer versions of H2O is an important functionality that lets you compare the performance of your older models to the new ones you trained on new data. In this release, we also added support for importing GAM models into H2O. For those users who prefer to use POJOs for generating predictions in production, we added support for importing POJOs and using it in-H2O to score on new data. H2O will automatically compile the Java code and let you use your POJO model for scoring as well as for calculating PDPs, ice plots, and other functionality that is common to all models.
CDP Improvements (IDbroker)
We have implemented support for the S3A delegation token refresh to access S3 buckets in deployments on CDP (Cloudera Data Platform) with IDbroker security. You can enable this option with the refreshS3ATokens argument, and, when enabled, H2O acquires and keeps refreshing access delegation tokens. For more information, please refer to the documentation .
AutoML Improvements
AutoML has a major change in terms of the validation and stacking strategy under resource-constrained environments, where the default 5-fold cross-validation strategy might be too slow or memory/compute intensive. In cases where the dataset is large in comparison to the compute resources available, we automatically shift to a blending strategy using a holdout frame versus the traditional method of stacking with k-fold cross-validated predictions to generate the Stacked Ensembles. This is an automated version of using the blending_frame argument in AutoML. If your AutoML runs only produced a few models in the past, you may notice a larger number of models trained and improved performance on your datasets. The criteria used to determine which ensemble strategy should be used is a function based on data size, number of cores, and amount of time given to AutoML.
AutoML also has improved error handling in this release. If there are problems with your data which cause errors, AutoML will detect and fail earlier than previously, helping the user debug their data/problem more quickly. Lastly, a change that was added in a recent 3.34 fix release, is that we now tune the scale_pos_weight parameter in XGBoost models inside AutoML for imbalanced datasets when balance_classes is turned on.
Sparkling Water Improvements
This new major Sparkling Water version brings improvements in its pipeline API. H2O Word2Vec has been rewritten to follow the same design as other feature estimators (such as H2OPCA or H2OGLRM).
The SW pipeline API communicates better now with end users during model training. It reports the progress of the trained model and displays warnings coming from the H2O-3 backend.
Users can also get a better insight to the details of H2OMOJOModels because this new version added several getter methods to H2OMOJOModel types for accessing particular details. For example, getRuleImportance() on H2ORuleFitMOJOModel reveals details about trained rules and their importances, and getCentersStd() on H2OKMeansMOJOModel returns standardized positions of final centroids. See the Sparkling Water documentation to learn more about other methods.
Documentation Updates
With the addition of new and improved tools comes new and improved documentation: Uplift DRF , Admissible Machine Learning and Infogram , and the updated ModelSelection section can all be found in the H2O-3 User Guide.
Credits
This new H2O release is brought to you by Adam Valenta , Bartosz Krasinski, Erin LeDell , Hannah Tillman, Karel Nechvile, Marek Novotný, Michal Kurka , Sebastien Poirier, Tomáš Frýda , Veronika Maurerova , Wendy Wong, and Zuzana Olajcova.







