




Make with H2O.ai Recap: Validation Scheme Best Practices


Data Scientist and Kaggle Grandmaster, Dmitry Gordeev, presented at the Make with H2O.ai session on validation scheme best practices, our second accuracy masterclass. The session covered key concepts, different validation methods, data leaks, practical examples, and validation and ensembling.
Key Concepts
While the validation topics covered are applicable to most models, the session focused on supervised machine learning models that included “tabular” models, neural networks, and time series forecasting. Gordeev went over datasets noting, “usually in the literature, we describe a data set as a set of pairs, x and y, where x is the predictor and y is the target variable. And our model is just a function, which tries to predict or reconstruct the target y given the target x as close as possible.”
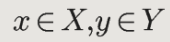
Metrics are critical to assess how well the model is doing. Gordeev defines metrics as “the function . . . that you will use to assess and pick the best model or judge which one is better, which one is more performant out of the models you have to choose from.” You can learn more about metrics in our first accuracy masterclass, Choosing the “Right” Metric for Success .
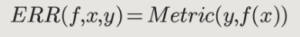
When evaluating models, you must consider all three parts together: the model, the dataset, and the metric. The model is evaluated against a metric on a specific dataset. Furthermore “a model that performs very well on one dataset might perform really poorly on another one.”
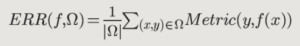
Gordeev describes model hyperparameter as “a set of parameters that define a family of models . . . some of them will drive the model complexity, some of them will not. And the choice of the hyperparameters, it’s quite judgmental, too. Because some of the things might be fixed, given the task, or given the type of the model or by choice of the data scientist.” For additional context, refer to the slide below.

When working on a dataset, the problem should be broken down into three components: training, validation, and test (holdout). Training the original data is used to run the optimization routine to build a model, given the hyperaparaters set. Gordeev provides examples “if we’re training logistic regression, we’re using it to run the optimization routine to find the optimal parameters of the linear model. If we are training a decision tree, then we’re growing a tree and we’re using the training dataset given the hyperparameters, which define the size of the train depth of the tree and we build the structure of the tree and that gives the model. If we talk about neural networks, here, we give the hyperparameter values, we define the structure and then use training to optimize the model weights to the training sample.”

Given the hyperparameter values, the training data will provide a model. “You use a validation dataset to find the best model and given the set of models you produce out of the family, you usually choose the best one, which is the model that has the lowest error.”
The test dataset is used “to evaluate the chosen model. Given the final choice of the model, you apply it to the dataset in order to know how accurate this model is.” Refer to the chart below from The Elements of Statistical Learning.
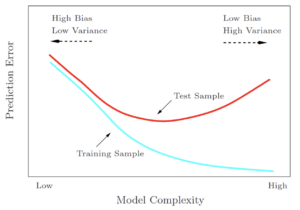
The Elements of Statistical Learning T. Hastie, R. Tibshirani, J. Friedman. Chapter 2.9
Models that have a high degree of freedom (e.g. neural networks), have very high complexity and therefore can overfit. Test sampling accounts for overfitting and finds the best possible model. “The optimal model complexity would be the one that gives us the lowest test error . . . The validation sample can be somewhere in between training and test, the better it is set up, the closer it is to test, but given certain circumstances, it can actually drift a little bit in one direction or the other.”
Cross-Validation
Cross-validation is the standard way to set up validation for your model. When doing cross-validation first, define the holdout sample to ensure the final model is robust and to assess accuracy on the dataset. Second, you work with the full training sample (not a full sample), assuming the holdout is not available yet, and split the full training into parts of equal size, where K determines how many equal pieces you cut the full training set into. You run the training model K number of times, leaving out 1/K of the full training as validation and training the model only on the remaining portion. In machine learning literature, K is also commonly set to 5 or 10.
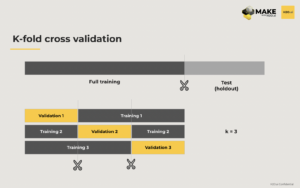
There are pros and cons of cross-validation.

Data “Leaks”
Data Leaks are “used to describe some data-driven issues, or cases, or situations that cause the modulation to be biased and can lead you to overestimate the accuracy of your model.
When these models are used to drive business decisions, data “leaks” become especially problematic. Gordeev provides the following example, “if you’re building a classification model, and you expect that you need certain accuracy of the model to make sense out of applying the model to business, then simply overestimating it may break your use case and basically drive the whole exercise you’re doing non profitable, and you will most likely just drop the model.”
Another problem that data “leaks” can cause is if the model focuses on the wrong thing and dramatically overfits. Furthermore, data “leaks” can create major problems when stacking, where the output of one model serves as the input for the other model. The leaky data or biased predictions of the first model will poorly impact the second model, rendering it worse than the first model. Note, data “leak” is a general term that refers to many different use cases when something goes wrong.

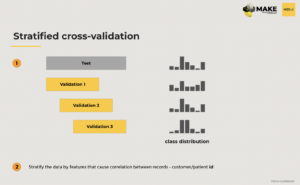
One solution is stratified cross validation, which can improve some of the statistical features of cross validation, as well as fix some of the data “leaks”. The first method for stratified cross-validation is by either a target variable, or other important predictors. The second method is stratification by features that cause correlation between data records.
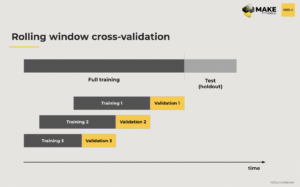
The third method is rolling window cross-validation. It is a way to make your test and validation as close as possible to the production application in case time is affecting the results in some way.
Practical Example
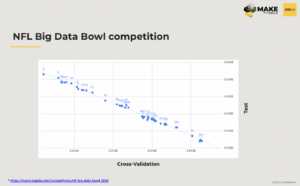
This is an example from a Kaggle competition where teams were tasked with creating a model that predicts the outcome of a specific NFL play during a game. The chart shows the correlation between cross validation and the tests checked during the competition. Stratification was applied here because there were plays that took place during the same game in the sample (cross validation stratified by the game). The test set was built using the rolling window method. The test set came from different games throughout the season while the training data was from previous seasons. The team built around 400 models and the chart confirms that they can trust the cross validation, they’re confident that all 400 models will perform on the test data.
Gordeev covers three additional examples in the on-demand playback of Make with H2O.ai: Accuracy Masterclass Part 2 – Validation Scheme Best Practices.
Validation and Ensembling
When working with complex models full fit vs bag of cross validation fits are important to consider. An alternative, “is to take a look at each of the K models that you built during the cross validation and instead of re-feeding one more on the full training dataset, you define your final model as a bag of the K models you’ve built. So your final prediction will be just an average of the predictions of individuals of the cross validation fitted models. That will allow you not to run a full fit. And that actually would give you maybe even more robust results than a single model. It usually performs equally, but sometimes I believe it performs a little bit better than training a single model . . . it might give you more trust in the model”
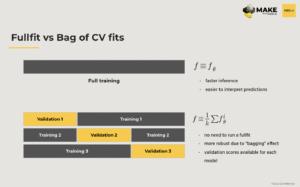
Another important technique is stacking where you “generate a new dataset, using the predictions from the models built, resulting in a new data set of the same size with the same target, but with new features. And you can build a model on top of that, creating a pipeline where the inputs of the first layer of models will be the outputs of the second layers of models.”

Lastly, Gordeev notes nested cross validation is “something you might consider doing if you find yourself struggling with a leak or you want to build a very robust pipeline and build a large stack of the models . . . it’s nothing but running cross validation, winning cross validation. So if you do cross validate, that would mean you will build all K squared number of models, but that can compensate you from introducing a model selection bias.”
Watch the on-demand Make with H2O.ai session on validation scheme best practices. Register for an upcoming Make with H2O.ai session.