






Agenda:
H2O AI Cloud – 2:54
H2O AI Feature Store – 15:14
H2O Driverless AI – 32:20
H2O-3 – 40:25
H2O Hydrogen Torch – 54:51
H2O Document AI – 1:10:52
Model Validation – 1:28:36
H2O MLOps – 1:45:19
H2O Wave – 2:03:08
H2O AI AppStore – 2:24:22
H2O AutoDoc – 2:37:20
H2O Health – 2:45:03
H2O AI Feature Store Demo – 3:01:31
Read the Full Transcript
Good morning and welcome everyone to H2O's Innovation Day Summer 22 Summer 2020 to broadcast we have a great program teed up for you over the next couple hours. My name is Tara Beatty, and I'm part of the marketing team here at H2O. And a couple of different things before I introduce our first speakers, you will see at the bottom of your screen, you have the ability to both ask questions and to chat and interact with those who are here, including our speakers. So feel free to ask questions throughout the event. And what we'll go ahead and do is either have our speakers, answer them as content is displayed, or we'll have some time at the end. So again, we have a great program set up, we're going to kick it off with several of our H2O customers. And they're going to share how they are undertaking AI transformation within their organizations. And then we will hand it over to our product leaders. And you'll have the ability to hear some of the latest and greatest features and announcements coming out in H2O solutions with questions at the end. So with that, I would like to introduce our first speakers, Reed Maloney and Vinod, younger, can you go ahead and join us?
Thanks, Tara. Hey, Vinod how are you doing?
I'm good, good. How about you?
I'm doing great, we got a great show for you all. Today, we're going to run through some of the some of the innovations that have that have passed to build our entire AI cloud. And then we're gonna jump into the customers that have been driving an immense amount of success in their organizations, using H2O and drive it and building off a huge number of business use cases across industry. So I'm really excited about the panel. And because we got an hour to go through all the new innovations that Vinod and his team have gone through in the next hour. The other thing I saw the note is we got people from all over the world.
Yeah, I'm just seeing this from Canada. Cute like lately. Last one. So like, you know, Quebec, Canada, Montreal, Greece, Germany,
Germany, and then and then someone said they're from North Carolina. I didn't see that. It was I got a quick glimpse. I went to school there. I went to Duke. I miss it, but I do not miss it in the summer. So I am out of Seattle. We are having we had the worst spring ever. Great now that I know how many people are on here. It's like 75 Everyday right now. And that's like, we get eight weeks of that. And then all of a sudden, we're back into knots that so we have summer and not summer here. And I know that is not your case. For now.
It is much, much nicer. Yeah, we got great weather. Today is a little cloudy. The morning. I'm in San Francisco Bay Area, California. So welcome everyone that says jelly, very sunny, and we're gonna call it sunny California. But today's a cloudy day. But hopefully it'll get sunny before we get too far along. Absolutely. Well, this is great.
So you want to get into what we want to do is just sort of show a little bit about the maker culture and just how innovative H2O is and sort of why we innovate as well. And you know, really comes back to helping the customers be successful. And so it really started with H2O Three, H2O Three is our open source distributed machine learning. It's really what made H2O famous as a company. We believe we have a million data scientists using H2O. And it really comes from the fact that this is the easiest way to run machine learning across a broad data set. And as we built out H2O, and we had a huge number of customers using it, we started listening to what they needed. And that led to H2O driverless AI. And so instead of driverless AI helped our data scientists and our community build even faster and often find insights in their data that maybe they hadn't seen. And then they were able to go and move much more quickly in terms of solving business problems and delivering value to the business. And honestly, in the last couple of years is even like the last few years, we built so much more this year, we built H O hydrogen torch, which is no code deep learning. Just talk a little bit more about today, we've built a show document AI, which helps helps to build intelligent document models. So you can have a wide variety of formats. And if you're looking at the B roll video we just had started with and that was Bob Rogers talking from UCSF, they're able to take this huge variety of referrals coming in, they all look different. And they as able to say this is a referral and then also find where the information it needs on the on the fax even though it's in different places. So it's really unique. And that's why we think about as intelligent document models. And then we've also wants h2 a wave. And this is this helps our makers make AI apps. So we're able to have the AI consumed much more easily by the business user. And that also helps to bridge a communication gap, which we're likely talk about on the panel today between the business and the data science teams or the analytics teams that are trying To help them solve those problems, and that's such a common issue. And Shawn, I know we've talked about this. And I want to do Shawn in a second. That linking that that business unit with the data science often leads that doesn't happen leads to challenges. In a lot of organizations about getting AI adopted and H2O Wave is really built, and built to help bridge that bridge that divide. And we've lost a whole set of innovation around helping customers operate AI at scale, or on Hu ml ops, or H2O ai feature store. And so prince who, who's really involved with that from AT and T, and as a co created product, we'll talk a little bit more, he's on our panel today, it's awesome. And then we've been able to deploy this where you can basically run your models that you're building and score them anywhere. So you could score him in snowflake, you can score them in your Java environment, you can score them on a shoe on the lops. And then you can run it on any cloud. And then we've launched our a COA App Store. So we're again, helping the business find the apps that they can use to consume the API. And then we have a huge set of pre built applications, not just for, for a whole variety of different departments, but also different industries like financial services, insurance, etc, health care that you can go in and use to help accelerate your journeys even more. So it's really exciting. And this is all happened, everything I just sort of went through one by one. That's all happened the last couple of years. And again, that's just to make that's the maker culture here. We're really innovative. And that pace of innovation as we grow and as our customers adopt is only accelerating. And so, again, why are we building what we're building? Well, it comes down to meeting the requirements of our customers for them to be successful. So what we hear from customers is they want us to support all use cases, everything from big data to text and audio data, time series data, we support it all. We want to be able they want to be able to deliver very quickly, but they want to be able to deliver quickly on on projects that matter to the business. And so that's that's different interfaces. No no code, deep learning, like we just talked about one click to deployment advanced auto ml that we support. We want to support multiple users so they can democratize AI, which we also have, it's easy to explain, monitor and govern provides the highest level of accuracy, which gives them the most business value. And they're able to integrate into their existing data apps and tools.
And so when we look at that all that innovation we put together into the AI cloud, why they issue a cloud provides the fastest time to value for any use case, across having multiple interfaces, having the best auto ml having intelligent document AI, no code, deep learning, optimized recipes, a huge plethora of pre built applications. It's really designed to help you deliver value to your business, we have the most comprehensive set of Explainable AI capabilities, so that you can trust the AI that you're building. And then we have the most flexible architecture. So we can integrate across any of the systems you have, you can score anywhere, you can run it in any cloud. And so we really built it so that and again, it goes back to open source as well. You're just providing flexibility, so it can work within the systems that you have to drive business value. So with that, let's talk to the customers who are really driving you know, helping to drive our roadmap and driving our innovation and are doing some really cool things with AI. So we have Prince Prince is a VP of data insights from AT and T. Shawn welcome, Director of Advanced Analytics from AES and Chris, welcome. Thanks so much for being here. He's the Managing Director, Head of Global Head of data science from Casselton commodities International. And you know, what we're going to do is just kick it off. Jensen, we'll go we'll go in that order. If you don't mind. Just you can introduce yourself, the company you work for, I'm sure no one no one's ever it. And a little bit about your role, you know, what are you doing? And where are you on your journey? You know, from the from an AI maturity perspective, you know, how far along are you just getting started? Are you really do you have 1000s of models in production? Do you have business units creating their own AI? Are you guys mainly doing it centrally? And just add a little bit of that and then we'll go deeper into some other questions about how you guys are driving success?
Sure, thanks. This isPrincipal Raj from AT&T. I lead the data science team here for fraud prevention and detection and take care of global supply chain management, AI standpoint and tracks and then various across you know, be yours. We kind of play as another role and how each and every business unit or innovate with the data and AI. So that's pretty much what I do in ATMP. to their office. And talking about little bit innovations. Obviously, we've been spending quite a lot of time and putting AI and data first in terms of any business industries that we are doing an ATM fee, as a good result, and I will say that even we partner with a hedge to wall to develop the AI Peter. So of course, I'll be talking about a bit later when with my friends here, but overall, in talking about the maturity, we are doing a great job and they're part of a journey. But still, we need to room to grow, do you want to make AI is being integrated every part of our business, and really adding a lot of value to our core business. And we want to be at the fabric of the company. So that's the goal we are going towards. But we are seeing ourselves great now I mean, in terms of scaling up, big time across enterprise, but we want a world more. So that's the current state of na TNT and what we're doing it.
Great. Thanks, Prince. Shawn, do you mind going next?
Yeah, Director of analytics today. Yes. Basically, though, I'm responsible globally for all things AI and ML at the company. We do think globally. So we're in about 13 Different countries that makes it fun with different languages that we execute with. And we do power generation commodity, we own a few utility companies are really broad in the energy industry, lots of fun, crazy, difficult challenges. It's exciting. It really is. I love what we do. And the work that we have, when it comes from a transformation. We've been on our journey for about two and a half years, building things up from the ground. We've made a variety of mistakes. But I think we've also made some good successes. So be happy to talk about those.
Thanks for sharing, Sean. Yeah, ideally, what we'll talk about is some of the mistakes our audience can, can avoid those and also the successes, so they can learn from some of the cool innovations and ideas you've come up with, to help you know really get AI going and scaling within the organization. Chris, you go next.
Sure. Hi, Chris Throup, I'm Global Head of managing director of Data Science here at CCI, similar to Shawn we are in the energy space. But we focus on everything from not just energy, but also natural gas, petroleum and all the derivatives. So it's been an exciting summer, I will say that, you know, we've we've used data for many, many years, and many of the commodity space us have used data for for quite some time. You know, we've spent the last three and a half years transforming to a common platform, and then applying AI on top of that to drive better business decisions. Historically, you know, the primary focus has been, you know, front office decisions around, you know, our natural gas plants, or how we want to handle the markets. But we're also now currently exploring with H2O, some of the middle and back office capabilities, specifically around document management, etc. Because we have a lot of contracts for debt data, etc. I think that one challenge that we face, and I'm sure Shawn maybe faces some of the same is, you know, we bring in hundreds and 1000s of datasets from around the world, including governments, vendors, etc. And so we spent a lot of time not just on the, the data, AI side of things, building that out, but also, you know, getting our data curated and organized and structured, so that it can be properly analyzed. So that's been kind of a joint effort and ongoing effort. It's very boring work and painful. But, you know, we're starting to see the value of it, as we apply H2O to a variety of use cases.
Great, thanks. Thanks, Chris. Appreciate that. We'll definitely dive into it. When we get there. I know we're going to talk about some challenges. And I saw Shawn, you nodding your head, like full agreement about this being one of your biggest challenges. And I hear this when I talk to a lot of our customers as well. So we'll get into that more in depth. The note, I know you got a couple questions you want to jump in on so?
Yeah, definitely. I mean, well, first question is since the group I had came to mind for the current macroeconomic climate, market conditions and a lot of pressures, impatient being high and you know, there's fears of recession coming about I'm just curious because in the in the past thing, you know, AI was kind of like a nice to have but now I think we believe that do you think that AI is becoming more and more critical to help organizations operate better, more efficiently? Maybe even like, be smart about where they spend their money what to do? I'm just curious like, how are you seeing that how are you using AI are seeing the economic climate impact and what changes are you bringing to your journey?
Alright, so I would say that I know we are going through some sort of an a tough time in omics standpoint. But first AI is not a nice to have an AI. In fact, you want to have AI in all the places. And now being inserted this AI and all the machine learning models part of our business process, right from our sales, you know, it's playing a huge role, you know, across a TNT, either it's a fraud or churn or, you know, bringing some customer insights or global supply chain management or field operations, it's everywhere, it's out there. So, it is very important for us and difficult time like this. But now, in fact, you will, we are thinking we want to move faster, right? I mean, you want to improve our operational efficiency, we want to really look at our ML operations, what how we do it. And when millions of transactions been, you know, coming through daily basis, you can think of company like an AT and T produced integrated part of our sales channels, you know, just taken a fraud as an example. Or, like more than 10 million transactions every day, it's been scored in real time, you know, the help of H2O, the module and the ML ops and all those things that needs to really work fast. So we are in a situation now we want to actually improve the operational efficiency, and we want to move faster. And we want to identify the faster patterns in real time and, and go and put the new model in place. You know, either we are retraining or putting a new model in place. So that's the kind of sentiment what we have here, though, in all of the things that are happening. In fact, it's encouraging us to, you know, move faster. I mean, if you want to fail, I mean, you want to fail faster, so that they can recover it, and really improve operational efficiency.
That's, I'm curious, what are you? Chris, I know, from the trading side, are you seeing headbands? And how are you like using this to change your models? Maybe they're, like, you know, you're listening about like a black swan events where we need to backtester all our models or change all our models, and give us what you're doing?
Yeah, so one of the reasons we chose going back to the beginning of H2O was, you know, we saw, you know, the need for faster data science, I think, Prince hit on it, you know, we saw a changing environment, we saw that many data scientists kind of, you know, my team is, you know, people are comfortable, they write custom code, they use it packages, they investigate features, and it's a lengthy process. And so, you know, I wanted to rapidly like, kind of just revolutionize that, because as we see the market changing, we see new datasets coming to bear, you know, every day, there's, there's new datasets, whether they're satellite based data, you know, new weather products, all kinds of different things that are happening out there. And so as we look at this kind of changing economy, we've got to be testing data, and new datasets all the time to try and understand what's going to help us better predict the future. And, you know, it's a real challenge. You know, we're, we're not at&t, I'm sure Prince has a team of hundreds, if not 1000s, you know, or as you know, so we have a small team of, you know, three or four data scientists. And so we need to be highly efficient and highly reactive to what's going on in the market and look at things and come up with projections, impacts of inflation, in fact, you know, impacts of slowing GDP, you know, etc, etc. So it's, it is absolutely driving us to be even faster. And h2 is very important to me, as part of this process, because it truly accelerates the feature engineering and model selection.
What do you show me any thoughts?
I would be echoing both of what has been said already here. You know, Chris, when I had mentioned a little bit about the data challenges, I like in H2O is to the fast checkout lane in the grocery store, okay, going in identifying everything that I need. And now okay, I've got it, let's move. And it helps enable that. You know, you originally asked me about the economic environment impacting the AI journey, being in the energy space, there's a lot of turmoil going on right now, a lot of changes. And I think it's going to continue changing how we use energy is going to change, which is going to impact how responsive we in our business need to be. And H2O was pivotal to that. But along with, you know, dovetail what Chris said, you know, also getting people to understand the power of using a tool like this is also part of the transformation. And I made a little joke to the data scientists the other day, more of a little bit of a jab at them, because one of them was complaining about the business. They're like, doesn't the business see how important this is and how easy it helps them do their work? And I'm like, yeah, it's kind of like getting a data scientist to figure out that H2O. helps them move faster to you guys. It goes with all right to che point taken, you know, getting them to understand that I think is important. And it's an evolution overall and a journey that we're all on. You know, Shawn,
you say that, Shawn, I'm sorry, sorry, I didn't mean to cut you off. But I think adoption by data scientists have a platform is one of the hardest challenges that that, that I've faced. And I'm really proud of my team, because I asked them to, to put aside their historical reliance on code and coding everything in total control, and trust in the platform. So it's a, it's been a real journey on that.
It has been and I have a data scientist, particularly with the Pythonic way of doing things that H2O is enabled outside of other tools. I mean, that helps them do the code monkey stuff that they like doing. But I've got a data scientist who loves it. He's like, every new day, I've got a new model that I get to, you know, see what H2O comes up with for the project that we have. But yeah, adoption is, is a challenge, but it's fun.
And maybe you find out a little bit, too, Shawn, you said the adoption? Yes. One is this, you know, the platform and data scientist? And if we go a little bit north, you know, we have the business customers there. Right? I mean, the domain expertise, I'll just use one example that, you know, the fraud. Yes, I mean, this machine learning models are scoring in real time and predicting whether it's a fraud or not. And based on the results, you know, the fraud analyst remedied the situation, particular transaction with a customer. Right, but, but, I mean, what is the threshold that fraud analyst should work with? Right? I mean, should I just use the range, anything about 80 percentage, you know, because it's, it's a balance activity that we're going to give it to the customer experience as well. You don't want on either customer too much because of our AI suspecting, you know, suddenly person for fraud. And so for balance activity, but at the same time, okay, now, the data science understands this, you know, AI, and it's always the predictions, but now, if you think about from the business angle, the fraud analyst, even the product analyst needs to adopt, you know, the to let the AI is giving me a recommendation using that now, I'm gonna take some some trepidation. You know, and I want to keep the customer, you know, the frictionless experience as well. So it's a kind of a challenging definitely, when the AI is really playing in real time, in a world of a situation. But But everybody's learning I mean, for example, I will say in this situation, what we have done, we use H2O. And our data scientists in a put together, they used to have a app, and they explained it and show them each and every pressure, what is the value of it to a fraud analyst. The business standpoint, the fraud analyst understood those, the pressures where they need to play a role, because they they go really tight the process, they're going to have a lot of color to the Caribbean, you know, they can they handle the volume. So it's kind of a balance activity. But definitely, it's to they want to sort of the explanatory tool really helping us to build a bridge between the data scientist and the platform and the business.
Yeah, I mean, I think that's a great one to sort of dive into maybe even more, which is, you know, what are some lessons learned for the audience, as you look to scale AI within your organization's you talked about helping the data scientists and science science teams go from code to sort of using a platform, and they still might use code as you were talking about Shawn, but they're using elements of the platform to help accelerate or the fast checkout lane? As I think you said, to move through that, you know, what are some things that that could help the audience say, Look, when you're trying to operationalize AI at scale? How is this going to, you know, what are some things they can they can avoid, from a pitfall perspective that maybe you guys ran into? And what are some maybe unique solutions that you came up with, to? To address those pitfalls? So, Prince, I don't really just to keep going on? Where were you were like, do you have just a couple of points to help maybe help the audience out if they're trying to operationalize and scale AI right now?
Yeah, I mean, you know, definitely this problem was there, I mean, just taking this AI, you know, into the business process. In the scale of like, I talked about millions of transaction, which should be scored in real time and things like that. But if I talk about a little bit of a technical challenges that what we have faced before even going there, you know, our data scientists, we always say that, okay, the typical process is again to data, then do the feature engineering, the magic happens, then we build a model, and then we hand it over to another team. So they're gonna take the model, and they're gonna put it in production. Right. So in other words, we kind of see it. This process is kind of duplicated. I mean, in the sense, you're coding twice, actually part of your training, and then part of the scoring time. So we want to avoid that. I mean, we see that, you know, data scientists building on model and an ML engineer is kind of putting into production because the data is not going to be, you know, clean and easy and during the time of your training, and it's not going to be the same during the demo for scoring. So we definitely look at, you know, how we can avoid that sort of a problem, right? I mean, that is a one lesson learned. We don't want to quote twice. And sometimes even we see it in the same team, that you have two different data scientists and developing the same feature, they're working on the same variable, right. I mean, we see that duplication also happens, that's one of the challenges that we are seeing. And always the speed to market is very important, you know, because like, like Chris mentioned at the beginning, and Shawn to the data is changing, you know, before COVID, during COVID, after COVID. You know, when you have a company like AT NTV, how many channels, they have retail stores, we have digital platform and care, things changes, we close down all the datasets during the pandemic, okay? Now, the fraudsters are taking a different pattern of things to victimize our customers. So, so this change is all happening. And at the same time, the speed that we are developing this machine and models, and we don't want a duplication of work, and we don't want to quote twice the same sort of work we do. So these are some of the challenges that we have seen. And, and when we saw those challenges, and definitely worked with H2O, and and then discussing because we are, you know, a big fan of the history module, and we use various tools and technologies from you guys. And that's where the core development started happening. Kind of an innovation from both our side Peter store, isn't it?
Great. Thanks, Prince. Shawn, what about you? Miss, I think,
I think it's, I mean, mistakes, you can took a look at it from like people process technology. And at the end of the day people are making are what make things happen. And I would say, for the last year, when I talked with business, and they talked about a project that they want, I say, okay, AI ml, it changes your business process, are you ready to change? And if they say, Well, what do you mean? I said, Well, let's take a look at your business problem that you're trying to solve with a tool called AI ml. And trying to reframe the conversation to help them see that this isn't just something that you pull off the grocery shelf, that it is something that you invest time energy into, and that it requires additional subject matter experts on their team, because data scientists don't know everything about the business side. So I think the you know, I look at the mistakes is not engaging the business in the proper way. From a people side, I think from the technology side, we did a good job of getting in data and creating data pipelines and a data lake that even the business could leverage at the same time that the data scientists are leveraging. And that allowed us to bolt on technology to to accelerate, and that's really what I call H two O is an accelerator of things. And, you know, then it gets into the challenges. Now as we're executing projects, I sometimes lead data scientists play too much. They experiment, that's what they love to do. So that's kind of how to keep them focused on the business value to with life. Yeah,
how have you been able to increase? I saw you nodding. So maybe I'll actually throw this question to you. But like, how have you been able to bridge that divide between the business and the data scientist or improved communication? Is that like a requirements doc? Is that using things like H2O Wave to help, you know, show and demonstrate and prototype? Or, you know, how are you guys start tried to, you know, if that's one of the biggest problems to scaling? Have you guys tried to find solutions to that that work?
Yeah. So I had a list of mistakes that we've made that was almost endless. So I'm glad you've, you've redirected me know the, you know, we've spent a bunch of time upfront. And a couple in a couple matters. And it's outside of H2O for a lot of it, but some of it isn't H2O. First and foremost, I've aligned my team into domains, right, so that my data scientists kind of rework in the same area over and over so they learn the content from our domain owners. So whether it's natural gas, shipping, etc. I think that is a key thing. Secondly, and directly to your point, we've actually built out a Data Science portal, and a data catalog all integrated into one tool set. So end users can investigate all the data products that are available, they can see and put in data science projects, and the point that Shawn made about scope is a huge one. So actually in our data science project, Um, we've we've created we use a local tool called Zuhdi, to build basically a whole platform for this. So we have straight through processing on everything from, you know, a data subscription request all the way through to a data science project. And the methodology is all instantiated in this platform. And we have, we basically forced the identification upfront of what is the target, and what is the business goal, and they have to be filled in by the commercial users. So we put in place processes and controls to help with that. And then I think when I think about H2O, some of the things that have been super helpful from my point of view, you know, along this process is one is explainability. Right? So we record all Shapley scores on every run. Right. So, you know, that's just one example of where we use the tool set to help communicate back to the commercial users, they can see the features that were impactful they can understand. And they can help kind of QA. And it's just, you know, it's been useful. There was one question that came up here on the side, I just wanted to hit on somebody said, can auto ml apps make data scientists lose skills. And I would actually say, at least from my experience, it's the exact opposite. What's happened and I've seen is that my team, instead of doing a single, simple, take Single, single spending, you know, weeks creating a single table forecast, you know, that basically shows seasonality, and growth. Instead, what we're able to do is push that to H2O, get that out of the way quickly. And then focus on combining multiple datasets, disparate datasets, really complex problems, having them really focus on the hard problems. And I just want to say this, and maybe this is going to break the marketing speech that you guys are doing. So apologies in advance to H2O, because they probably shouldn't have invited me, I guess. But this is not a dataset, this H2O is not a platform where you can just hand over to an end commercial user and say, Hey, go do machine learning. And you'll get perfect results. It is a sophisticated toolset. It's got a lot of features and bells and whistles. And that's actually what's helped with the adoption of my data scientist because they, they can see how it helps them solve problems by by tweaking the features and the you know, the settings etc. So it's a it's a very sophisticated accelerator. That's really good at it good results. It's not, it is not a Data Prep engine, like data IKU. It is not a, you know, a framework, like sage maker is a true auto ml and ml ops engine, which is exactly what we needed.
That's amazing, actually. Oh, that was a really interesting question from the audience. I thought that'd be we'll just ask it live to this group. The question was basically, do we think that the goal for AI and most organizations is to fully automate the decision making or augment human decision making? Think security against that line of thought you brought up especially in the channel and I would love to hear your thoughts on that.
I'll be happy to jump in at least start off. And I echo completely your sentiment there, Chris, that I think it matures, the data scientist even more. And it really embeds more passion in what they do by using a sophisticated accelerator like H2O. You know, what is the goal for AI ml? In most organizations? First, it depends on the organization, it depends on the maturity of the organization. I truly believe that it all right, my background, I got a PhD in psychology. So you're gonna get some psychology thrown at you here. As we take a look at people and how people react in the the evolution of work itself, we've always been on the way of accelerating things that we do to get to value and removing things that that add non value. And so is, is I look at AI ml, there are things that are going to automate jobs, right. And that's what we call middle work. But you've got low end work that's just very hands on stuff that you cannot automate away. I mean, we're still gonna have construction. But can we put in their understanding and automate, use AML to make our construction projects go faster? Or better or be more efficient? Yes, we can. Can we identify pre identify equipment failures on a construction project so that it maintains its time? Yeah. So there's things that we can do on that side, has that replaced a human or has that actually enabled us to be more efficient at our jobs? Okay. And then, I've got on my side, we've got wind turbines, right? We design models that predict failures for components on wind turbines and a technician wakes up in the morning and they're like, What should I go look at? I can never replace that technician, but I can focus him in the right direction. Saying you get these five wind turbines here are the probable faults that that are occurring. Or here's a potential gearbox, which for us is an expensive replacement, go and do something. So I don't have to bring in a crane, that's $150,000 At the start to replace that. So it's, it's more human augmentation. But I hesitate with that word, it's more human in the loop, it's making us be better at what we do. And you know, which, with all of this information, it's helping us cogitate through things faster, it's helping us identify things, I see it's going to be a fun evolution over the next 2030 years, and AI is going to be that mainstay that continues to help us be happy, do our jobs more effectively, efficiently. It'll be just be a part of our life, like Excel is today, which we can get rid of, I don't mind.
I agree with everything, except for getting rid of Excel. I love Excel, I have to admit it. I know, I know, it's caused so many problems. But it's so great, anyway. No, and the other thing I would just point out that it's helpful for us on is, you know, we're a smaller organization, you know, about 1000 people. And, you know, historically AI has required a huge infrastructure build, to really do at scale and prints, I'm sure you guys probably have quite quite some some servers and compute capacity. One thing that, you know, that we're really focused on is utilization, we use snowflake as our back end. And we are very, very focused on the product innovations that Eric and his team is leading with the usage of snowpark, from snowflake. And it to me, that is the future of machine learning is in database, hyper scalable infrastructure, compute infrastructure, from from a toolset like snowflake, managed, you know, by H2O. So, you know, to me, this is it's all the things that John said about kind of like, making people's job higher level and doing more insightful analysis that allows us to gather, you know, trillions of rows of shipping points, or weather points, or whatever, whatever the case is, and really processed them at scale. And that used to take 10s of millions of dollars of infrastructure build, and now we're starting to see a world where we can do that kind of in a in a very much more attainable, achievable fashion, without the massive infrastructure build. And that's scary to some people, right? Many people have, you know, some maybe on the infrastructure team, you know, built their life on maintaining an Oracle database or servers and things like that. So you, you will face resistance with some of these visions, not just on the data scientists, but also potentially on your database or infrastructure teams. And, you know, hopefully they get that vision of they can elevate their skills, but I don't think people always can. A prince, you guys have massive, massive servers, I assume? Oh, yours, you're on mute.
Yes, Chris. I mean, sorry, I was new to whatever you said, because it's easy, you know, the moving to the cloud, and, and bringing all the data in one place. But definitely, you know, the cost will play a big role for your computations, and how efficiently you know, you run your queries and, and manage that, you know, the workload, it's really important. I mean, that's a big lesson, you know, we all learned I mean, we burn our fingers, not only in snowflake, we use data bricks. And we use Palantir. I mean, do some strategy additions, you know, the valuation of technology, we have multiple cloud players in place. But But But overall, when I look at it, I mean, either I look at Palantir, or I look at their products, or I look at snowflake, or even Salesforce in the science standpoint, I mean, all those things we see. We don't want to duplicate the data sets in all over the cloud. I mean, we are looking for a platform. I mean, that's another thing that why it makes a lot of sense for us to partner with H2O is to have some sort of, you know, technology, which can really work along with all these pipelines. Right? Some people do this machine learning and barrel breaks, some people do it in snowflake, some people do it in typical Jupiter, some people doing and Palantir. But doesn't matter where you do. And as long as the data, the features that the machine learning assets that we create, that is, you know, we are able to democratize across this platform and keep it in one place and share it and that actually brings the, you know, the real power of a democratization. So, knowing this disturbance and knowing this technology, you know, evolution that we all going through, but something that we want to appreciate and and keep To our machine learning assets in one place. And still we need to drive, you know, we don't want, we want to avoid the duplication. We don't want to eat a swamp. But at the same time, use it efficiently. That's the big challenge. And that's what we are currently experiencing, or pretty much trying to get the job done there.
called, I like a two pronged question. Maybe and I think was lead say nicely to the next question. That really right. Yeah. Do you want to ask? Yes. So we have built this really nice AI maturity model. And I think we've worked very closely with adnd, and other customers as well. And as part of that, as you know, we help customers find out where they are on the curve. So the first question I have is, if you were to like, if I posed you to all three of you, you have to give feedback, let's say someone starting new someone in the audience has behavior, like really ahead, like, like starting out in the amateur career, like step one or step two, how do you go about this, right, so what like, let's say one piece of advice, or a couple of pieces, advice you would give someone to get started.
Maybe I'll jump in quickly on this. So, so we started this journey, exactly what you said, you know, the basic thing, what we have done is, we didn't worry about the automation, you know, we didn't worry about, you know, using sophisticated tools and technology. But we started with very simple, we were like, Okay, let's get the data. And in a platform where we can actually, you know, do the model, and show the results. So always we started with a POC, any business value that, you know, we want to just go in front of the business, and say that, hey, I can bring some value, so that we always go start with a POC, and do a POC and do the show and, and show the value the value or the cost avoidance or cost savings, you know, what are the value that's gonna bring it and then so that and that really helps the leadership are it's kind of a change in the culture, right? In our company and our people, we've been working on a different enterprise style of, you know, making things happen, pretty much rules driven, you know, pretty much, you know, logic driven approach, but you're again, getting into the predictive side of it. So really, what it helps is doing a simple POC to the show and, and make the leader to understand and and then, you know, go there from from from the POC. So that's what really helped us. And we have done many POCs, I would say in beginning of in cheated office, across various views, but I can see the results now after the fact we did all this good work. But now, we are really in the curve of you know, the maturity model to get into their well wishes.
That's great. Thanks, Prince. First of all,
I I agree with everything prince said we did some POCs actually, we we made a mistake there. We showed too much value. And so some things were done too quickly. And so people just assumed Oh, well, data science can all be done now in two days. So you know, it was kind of ironic, that we actually oversold actually, internally with the POC process. But that's a whole different discussion. You know, I think a couple thoughts. You know, one thing that, you know, I had my team layout, end to end was a methodology and process. And we instantiated that through a tool. I mentioned that earlier. So if you're getting started, you have to start with a data. But you also have to start with a methodology and governance model. And the problem with this is it sounds great. And if you meet with commercial leadership, and they say, we're going to prioritize, this all sounds great. And if you start with a data, and you get good quality data, and you're properly tagged, and organized, and good data quality, and you do all these things. And then you build a methodology at all, it's great, and it solves some of the problems around too much exploration, etc. The other challenge that it creates, though, is your business users may feel disenfranchised. So they may never make it to the very top of the priority list for the data science function for the team to work on. You know, we don't have unlimited capacity. So you know, what we've done by documenting all this, as we've a few people are very frustrated, because their projects never get to the top of the list. So you know, thinking about a hybrid engagement model, where maybe two thirds of the team is focused on strategic projects. And then 1/3 of the team is focused on tactical point in time, you know, really rapid market ascent, you know, things setting, working with commercial leadership to set aside kind of capacity. And that passion, I think, can be helpful, because as good as the tool is to accelerate the analysis, there's always more, there's always more to do. And so prioritization is important. So I think that's the lesson we learned along the way is that we, we built a platform, we had a platform approach, you know, my data scientists push all data engineering into you know, views, we use machine learning views, we don't use, you know, code to transform we did I think a lot of things right, but we also didn't necessarily be He's responsive to all of our commercial users. And that caused some frustrations, some real frustrations.
That's a great, thanks. Thanks for sharing that, Chris. Shawn, what about you? Like what, what helps you guys really get get going and then scale?
I think, you know, we, we started at least with the data, you know, if somebody ever asked me today, how do you have a new company? And how do I start my AI ml practice? I've never done it before? Is this brand new? Part of me wants to say don't design a model for 12 months. Okay, start off talking about advertising, get the foundation set up, which is how are you going to run your compute? How are you going to create your endpoints, where's your data, what's doing, you know, start bringing all of that in, start working with all the DBAs get them in from an infrastructure level to start pulling that data in, and then start creating some models. Because to Chris's point, as soon as you give them candy, they want more candy. And sometimes these guys are kids in a candy shop, saying, let's do this, let's do this, can you do that? Yeah, we can, that's gonna take five months that may take a month, you know. And then you're pausing. Sometimes, because you're stuck on the data side, I always have a hesitation with governance, the wording I like to use is minimum viable governance, back to the point that Chris was making is that you can get disenfranchised business people, which is not what you ever want to have happen when you're doing this, because then they start doing their own shadow AI ml. And that I almost fear is more destructive than the shadow IT department. So, you know, how do you how do you help keep that engagement? You know, one thing that I that we did at the very beginning was we created Design Thinking sessions. And so we went to the business, and we're going to just talk for hours about your problems, and they just talk about them. I say, Okay, that is good. That is not that works. And then we just talked about some value, and some timing. And we talked about creating expectations. So it's a lot of conversations in the beginning. And now every 1218 months, we hold a design thinking session with the group, and they all love coming to it, because we get to discuss things and talk about prior successes and where we are. And then here's all the new things on the horizon. But at the same time, it's how do you help enable some people who, who aren't getting that feedback? And one of the things that we've been doing on our maturity, I would say is, I call it enabling it, or I call them Python enabled people. All right, we're getting more people into the workforce that can leverage and use Python, but they're not data scientists, but they can do some things with Python. So how do you help enable them for some of the simple things that they may be doing, but that also helps elevate their maturity overall. And it also helps identify people who have good potential to upskill in data science inside of a company. We're not even talking about finding data scientists, that's a whole nother panel discussion in and of itself.
It's probably going we actually had a blog recently on just hiring and retaining Data Science Talent come out, because it is such a such a topical issue, you know, just sort of going back into the the POC, concept prints and Christina, you're talking about, you know, your first, your first project adding so much value, you know, this is something I've seen talking to a lot of our customers is, you know, they're really start by getting the first few Lighthouse wins that really actually show value is what's helping them scale, you know, is it do you feel like there's a number like is that like two or three? Like, how many projects do you think you need to like really have that business value in to really help the organization say, Oh, yes, we need to make a much bigger or faster investment into AI ML to really help drive the businesses? Can you do that with just one project? Or is it typically like a small handful?
I think it's started with always one project and, and, and it's like, you know, I will tell you, it's not necessarily such project needs to be a, you know, super predictive model, or a beautiful forecasting model or some optimization problem you're trying to solve it could be you know, finding a needle in a haystack problem, okay, so, so it's not necessarily, you know, how big of the problem you're trying to solve. It's all about you know, like, like Sean mentioned customers and I mean data is also plays a very important role right? So so if you can able to get like three months history of data like multiple data sets, and then join them and bring some features and then build some model on that, so do something that's small and show the value and once you get the value then people are you know, seeing the candy and then obviously, they want more candies like and then you kind of dictate the terms and say, Okay, now what not me to do that I need more data sets to coming in. Like three months it's taking to build the model and and of course, once you have more data coming in place, definitely the building the model and the lifetime is reducing it and and the two It's like h2 or what we use it right? I would, I would, you know, I always say that it's I'm a big fan of h2 abajo. Because you guys made us to run these models in production. It's not an experimentation, right, we are running these models in production. So we need to run this model in 60 milliseconds, 200 milliseconds, 500 milliseconds. So that's the sort of speed we needed. So you're not going to do that speed while you're doing this POC, but our data scientists focused on building those models, but use the H2O technology, where we can scale that POC to production in quite reasonable and I would say, sometimes it's much faster, I mean, we are able to, you know, take to the model very fast to the production now. So, so yeah, I mean, it started with the one model show the value, you get more candidates than ask them more in terms of the data and assets that you want. And with the help of tools, like it's too, you know, then we can scale it up to the bigger level.
No, related to that, Chris, you know, you talked about that one, you know, you had that use case that had this super strong value to get started, like, how did you select that use case? You know, I think that's an area where other people struggle, which is, you know, how do you with those, get your ones to get started? How do you get the right business problem to start with to know that you can then bring that up to leadership and start building the function?
That's where, you know, you have to have I think, as a head of a data science group, you have to have strong relationships back to your commercial owners. So I went through a process of talking to each of them and finding out what was kind of the the areas where there was a pain point. And where I could find an intermediate sized problem, I didn't want them something that was so simple, that everyone would look at and say, well, that's, that's no big deal. Why should we spend money on this, we can use open source packages to solve this problem. On the other hand, I didn't want a multi year, or a multi month project that would take you know, six months to assess so. So we really spent a little bit of time talking to the commercial owners, and then figuring out our model. And the other part that was, you know, good about this is, or I would talk about a little bit about is how we communicated the results. So what we actually did in this POC is we did, we took, I had one of my data scientists do the project and measure all their time, in JIRA. Then we took four different platforms. And we assessed them. And we had the same project done. And we actually did the timings through the different platforms. And then we also looked at the actual RMSE. To compare actual results and accuracy. And H2O, as I said before, came out extremely well, on the automation of the feature engineering and the model. And, you know, it was the only platform with those features that came out with an RMSE that was basically the same as my data scientists could do on on his own. So that was a pretty credible result. But then going back to take the POC back what we did, we created several different decks. For our, for our COO, we created the time savings and efficiency deck for for our, for our sophisticated commercial users who have a technical mindset. We showed Shapley scores for our commercial users who only under you know, our more Excel type and, you know, really more fundamental in their their skill sets. You know, we actually created visualizations, which showed visually how much closer the forecasts were, versus existing existing work that had previously been done. So, you know, we really prepared multiple messages off the same work product, and that was tailored to the commercial needs, but it was, there was a fair amount of time and needed to go communicate. And I you know, because I always get the pressure, well, why do we spend money on a platform, I could just go hire another data scientist for the same cost? Right? That was a real question internally. And we have all this free open source. I've read about this, why, you know, our CEO is like I've read about this open source revolution, why can't I just go do that? So you know, I really had to show the value of the platform in terms of end to end process, not just engineering or not just a but ml ops side as well. So those were all messages that I had to listen for my commercial leaders and then prepare communication to
write no thanks for that. I think that's a really common challenge that many, many companies have Getting started is that communication piece, so that's a great, that's a great insight. Um,
I think one of our mistakes is that we weren't able to find the right t shirt size project to work on. So our projects were nine to 12 months, which was a little bit longer than what was needed. I think it needs to be a little less than six months, but it's okay. I would say to show value iteratively alright, because, you know, we had one project act where, you know, the business was doing about 65%. On accuracy we came in, we moved it up to 70%. I'm like, Hey, that's a little bit more, you know, does that prove that we can show? You know, we know we can improve that? Right? We had a strategy behind that. And it slowly got the business involved. I mean, sometimes you're not going to have these big Whammies. So you've got to go for smallness. But, you know, as you as you pose your question there read, I think what's important to note, I'm going to go back to my psychology side here is that business can only change so fast. And we did something successful with one business unit. And they said, Okay, we want to do this. And I said, but you're not done actually working, fixing out or, you know, figuring out what we did on how to implement it. No, go spend three months doing what we already gave you, then let's go talk. And they were a little bit miffed at it, but three months, they came back, and I said, Okay, tell me how you what happened over your three months, they're like, well, thank you, you know, we actually spent time using it. Now we know what we want on this next iteration more so than we thought we did. It's important to keep in mind that we're humans, we can only change so fast. If I give a business five projects in a year, I'm going to overwhelm them. So you know, there's a balance to play in this. And it's nice that I can move fast. But you need to work on how to, you know, keep this holistic with the organization.
Now, it makes sense.
And only almost untampered close out the one question for everyone. What's next? What's the next innovation that you guys are working on? Maybe you can share a sneak peek of something cool that you're working on? Shawn, I think I know. You've been doing some really cool stuff with like drones, streaming the different drones to do like improved like, you know, predictive maintenance and stuff. RFPs something you're happy to share or maybe something cooler you're working on. Maybe it's same for others as well.
You want to talk about innovation, where we're going? How do we use graph DBS and integrate them more? I think that's important. There's a lot of relational things going on inside the data. How do we leverage that? Drone data's has been fun, I'm actually excited more about satellite data on what can be done. Satellite data can actually reduce drone data costs. There's a variety of things out there that that are the technology is being becoming more available, where the resolution is there, that you can get it and you know, honestly, for 20 grand, I can start tasking some satellites to do stuff. That's not a big number for our organizations in testing and trying new things. So I'll leave it at that.
Thank you, cool. Crispin's? Yeah.
I'll jump in. So yeah, for us the innovation are part of our a maturity model, right? I mean, we are in a phase where how we can democratize AI, across our enterprise, right? I mean, internally, we run a program called as a service. So definitely, you know, that's why we figure it out, in order to scale, such a big level. And when I say the democratize AI, it's not just our data scientists and data engineers, just using from the platform standpoint, but it's more like how citizen data scientists in our business, people can really use the AI part of their day to day operations, right. So that's the journey that we are, you know, going through, and definitely the innovation there for development, you know, with your team on H2O Flixter. That's really a big one for both of us. And we are putting a lot of our efforts to innovate that product, and really, you know, help us to take to the journey that, you know, what we are going on that that's from our fine.
I think from our side, you know, unstructured data is very, very interesting. I've wasted a lot of my time of my life on NLP projects in the past. So, you know, I'm hoping that with some of the new tool sets out of H2O, maybe we can start to explore that truly as a value add versus a time suck. So that's one area I think that we're going to explore. Secondly, as I mentioned, we're we're obviously investigating middle and back office use cases where I think there's some data anomaly detection, I think we don't have a retail focus that maybe like prints might have. So we, we don't have fraud, but we have, we have other potential uses. I think there maybe in terms of, you know, glitches from our brokers or whatever. And then really, third, I would say the biggest and most important focus for us in terms of innovation is and I mentioned earlier, is creating the most scalable platform possible, right? Because, as I said, we're a somewhat smaller organization. I mean, I'm sure AT and T has like 1000 People just in one call center. So you know, we are you know, much smaller and so We need to take the tool sets that we use, which is snowflake in H2O, we need to use them together and use them to attack larger and larger data problems is like Shawn, we're in the internet of things, right? The real world, that world world of commodities is all about the real world. And so as you can imagine, there's almost endless data in the real world, that that can be pulled in. So these abilities to take on larger and larger datasets, without kind of a huge cost infrastructure built is a core focus of ours. And really, frankly, when we compared it not to sell H2O, but when we compared H2O to some of the other different products out there, you know, we saw that tightness of partnership and utilization, maximum utilization of, of, of, of the new upcoming feature sets within snowflake. So that was a big decision point for us last year.
Thank you, I think we are at the top of the hour, I really want to take the time to opportunity to thank Chris, Shawn and Prince for joining us for this amazing panel. It was a great discussion, I think. Yeah. And some great questions as well. I think the audience is super engaged, a lot of questions will out, definitely try to answer those questions offline, or maybe even after the panel. But once again, thank you for joining us chatting your insights, just fun, as always. And I hope you'll stick around for the rest of the hour, where we are going to talk about some of the product innovations, and share some of new innovations that are coming up as well. Okay. Thank you all, then, Prince. If you want to stay on for a bit, we can talk about feature store real quick. That's one of the first things in the proclamation.
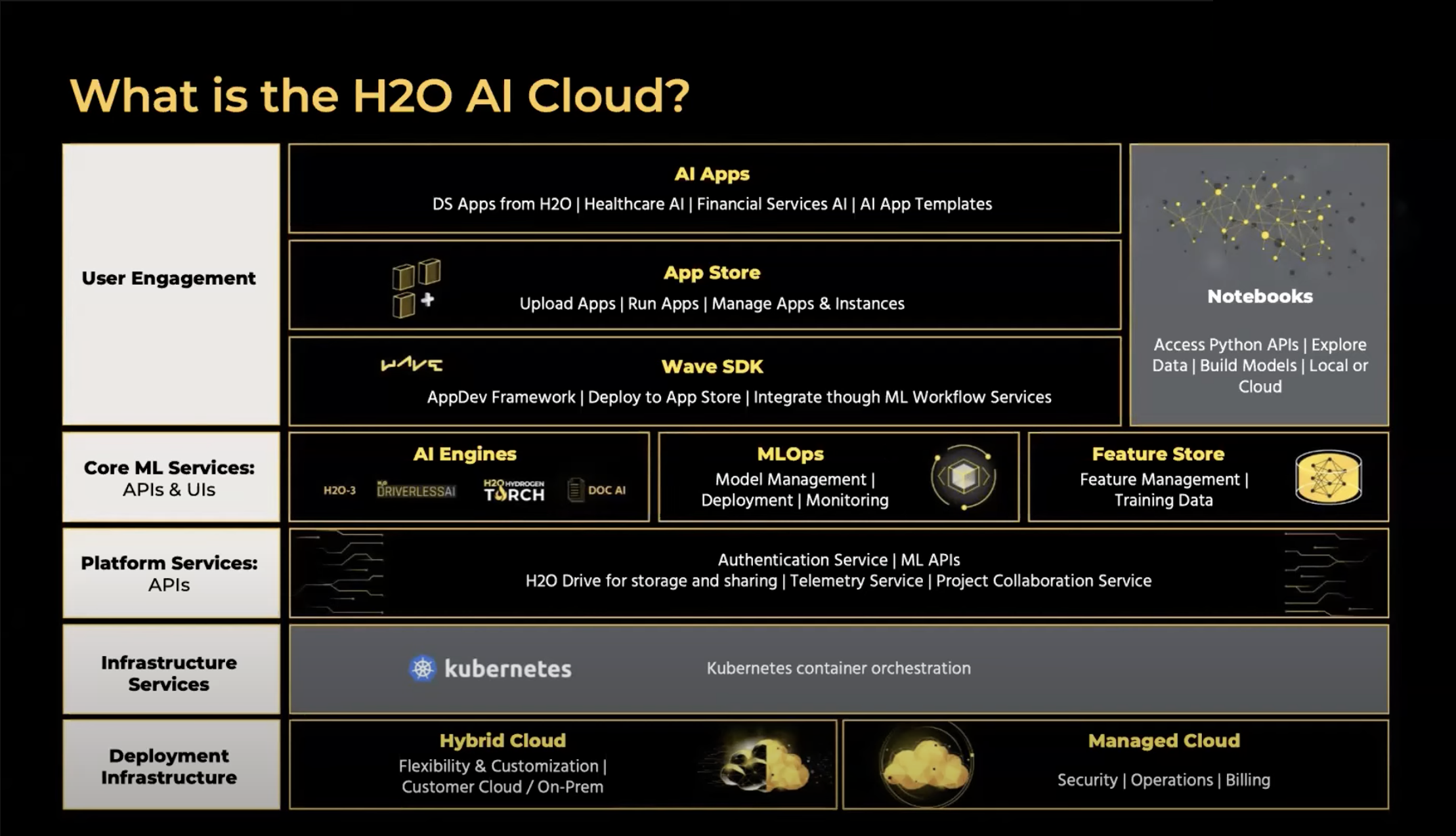
Thank you, Shawn. Thank you, Chris. All right, we go ahead and kick it off. All right, so we got a fun agenda coming up a bunch of new products, like our existing products, and new innovations on those products with solid features are obviously good. Hydrogen targe, document ai, h2. And Cloud, of course, is to wave Remo labs, responsible AI, and then we'll get page two or three. So we got new new innovations, we got PMS waiting, ready to share some of the new innovations and all those different products. To kick it off, just we thought by telling you what we've done in the last sort of year, year and a half. Right? So we've been in this journey for you know, 10 years now. But last year, and have you been announced phenomenal, like set of new innovations, right, so we launched HDX. Cloud, actually, early last year. So it's basically you don't have for the platform, right. So this is our platform for the overdrive, the CH two three, sparkling water and steam all these products. Customers are loved and use for many years, but we brought them all together into a icon. And then we had basically 100 Plus apps in the App Store as well, very quickly. We followed it up with feature store, which was which went live in q3 of last year, joint announcement of the TNT Princess team. We also launched Travelocity at one time, which is a big release phenomenal ton of improvements and of new innovations there.
late in the year, we launched our managed cloud, which is a big announcement as well, this is first time we have a disclaimer, software as a service solution, the entire AI cloud fully managed by us. So it's a turnkey solution for customers to come in start using it. We also launched a whole bunch of health apps for our health app store. In June of this year, we announced document AI, which is also co innovation with one of our other customers, UCSF that you probably saw a webinar earlier in the year. We also launched we launched hydrogen torch and q1 of this year, which is no code deep learning platform. We have a lot of innovations coming updates coming on that as well. And then we upgraded our ML ops. So this is all in the field. If you attended our last product day, which was in April, you've probably caught a lot of these things. So what's coming up, right, we have a phenom set of things that we're going to talk about today. But more importantly, we are also introducing things like labeling we are feature store going more generally available for customers stock media becoming generally available, managed cloud with more tiers, auto ml as a service. We can also have more tooling for business users to make it really easy for them to consume the platform. We have a lot of App Tool building toolkits, which will showcase a little bit later like how making it really easy to build more apps and have them available on the platform. Okay, so stay tuned for the entire rest of the hour. I will cover a lot of these things. I want to start off with feature store first. This is a product that we launched late last year in partnership with at&t especially prints and team we've been working on this SWAT actually more than a year and a half, right like those two years of working closely with the team, the gun, a lot of phenomenal requirements, like very core requirements were like we understood what data scientists were doing at scale, what what challenges India was facing when they were launching all these models, with all these datasets that were being taught that upon us models and prints mentioned earlier, right, like, the key was to ensure that the same data that is used for training is made available for inferencing at a really low latency. So with that challenge in mind, Mr. ratable, this is just your, as you can see, one of the key tenants for us along was to ensure that data can come from anywhere. You know, we earlier Chris mentioned how snowflake is a key data store for them, they need the snowflake, data breaks, and all the other tools exist as well. We also saw that customers have data and let's say, environment, Secretary data and Palantir replaces it with a whole bunch of pipelines. So the key was to bring in data from wherever you are, whether it's real time data sources, or batch data sources, we have connectors for all of those different data sources. So you can bring in data to the feature store from wherever they are, whether you're featuring pipelines exist or your data transformation pipelines exist, you can just use the same pipelines to bring in data to the feature store. And once it's in the feature store, we have the offline and online store to support for batch predictions of our training, and then online for the real time predictions. And more importantly, we have a full metadata registry, which allows us to keep all the historical information about the features like information about audits like lineage, whereas the data created, and this is critical for discovery purposes. So one of the big values of feature store is you don't just create a feature pipeline rolls, you reuse it again and again. So someone has created an amazing feature and put it into production. How nice would it be if others can benefit from that without having to recreate the wheel? So the metadata becomes critical to help expose help, discovery and collaboration other features? You want to add a few comments and how it's been working out? And what's the journey been at end?
Sure, sure. I mean, I mean, we're not, you know, you nailed it. I mean, you kind of mentioned, all the key functionalities are some of the challenges that we had, and in the past, and how really the feature store is solving those problems. It's awesome, right, so so like, you know, we're not mentioned, we launched this in a TNT internally, we have more than 1000 data scientists and data engineers on this platform, we have more than 10,000 features, it's been in our feature store, across different BU, they have features coming from different the BU like global supply chain fraud and, and customer insights. And and, I mean, it's happening, you know, really a big time right now. So the whole purpose is how we can reuse this features, and how we can, you know, minimize that, you know, the offline online challenge, and how fast we can go, right? I mean, new problem comes in, you know, let me go and, and research what features that I have in features to quickly go on to look at it, I see a couple of feature sets have been posted by someone else. But really, it's useful. Let me combine that and see, oh, yeah, I got a good look to my existing model, or I'm able to put a new model quickly, is there is a already, you know, two three great success stories with at&t Using this feature store. So it's nice collaboration. And I love the daily standup that our team is doing with beneath an SDR team there in order to do this in a code development on daily basis. So it's a really a great journey. And we see a lot of return of investment already for this feature store and looking forward to you know, enrich more functionalities and, and really doing that magic that what we are looking for with the feature store product or as a service.
Thank you for itself slowly. So with that, let me just jump ahead and show a very quick demo of how the feature store actually works and how you can use it. Alright, so if you've come to the feature store, this is the front end for the feature store. This is the user interface where users can come in. And so nice way to look at all the projects you have in place, you can also look at all the feature sets. And there is also a full access control mechanism. We have a full permissioning workflow. So when you create a feature set or project you can, it's it has different tiers and people can try and see who can access access to it right. And I said once the project is created, you can go into the project you can see the individual feature sets that are inside of the project. You can pick one of them and you can open it and you get a whole bunch of details about the feature set right it tells you when it was created, who it was created by the pipeline itself processing interval other information like Time To Live and etc. So, these are all things that can be tracked. But important thing is you can also call track or disk carboard features to be whether they are they are PCI data or or SPI data or special data, right? This is important because if you are want your data to be sensitive, sensitive, you want to track it so that others cannot see the raw values, even if they can see the actual feature set itself. And that's something that's supported out of the box with the feature store. And once you see the list of features, you can obviously go and peek into them, you can get some summary statistics very quickly, like mean, median, etc accounts. And this is useful again, to see the data like get a sense of what the data has shaped the data looks like. We are adding some more innovations over here coming soon, we can actually generate an auto Insights report for you and have it available. So that's nice, because that entire report can be used for us again, to get a sense of what the data looks like. Right? There is the ability to add quotes, artifacts. So this is nice because you can have a report or maybe sometimes you can have like a PRD attached to the project itself, the selected dates, and it's really great set of features, they can put in additional information that will help others determine if that project is useful for them. So you can add links, PDFs, etc. You can also get a code snippet, this is nice because you can essentially create take the PI, the PI spark or Python coordinate to go connect to the client, and then use the feature set from the client, which is how we will most commonly use it right. So if you go to, let's say, your spark environment or your Python environment, you can just pick up the score to start using it. And that's what we'll do today, right will very quickly show you how you will interact with the feature store, right. So if I go to my Jupiter environment you come in, you will see basically, this is a notebook I have I've already installed the feature store client. And I've already logged into the feature store. So it's very easy, you use your autocon and login. If you use Jupiter, it's it's super simple to log in, it'll this will pop up essentially a new window that will help us whether you're, you're using Azure RT or a database or whatever your auth mechanism, you go and login and authenticate yourself. Once that is done, you can then come in as a user, and you can do a few things, you can obviously read datasets, you can extract the schema, you can use that to create a new feature set, register features or schema as a feature set and then ingest data into the feature store. So this is your second canonical workflow. If you're a data scientist, you build a great model, and you have a great set of features, you want to then supply like put that publish the feature set into the feature store. And this is how you do it, you basically do it right. So you would ingest your data, you read the source file, you would run it, basically bring up your credentials, and then you would extract the schema, this is the key part. Once you extract the schema, you can also then this is the opportunity for you to specify whether certain fields are sensitive. So in this case, I'm saying that, hey, gender is a sensitive field and marking it as SPCA field right? That means that it's going to be masked by default. It's easy for you to then change it later. But this is how we start off right. Once that's done, you then go create a project in this case, I created a project called Willow demo. And in that project, I can then register the feature set. As I do that, I have the ultimate opportunity register ingest data into the feature service set. And by default, the data will be ingested into the offline store. But just as easy it is to register the data into the online store as well. So this is how you determine whether you want the data to be online or offline. And this is a call you may make based on your application requirements and stuff. And once the data is ingested into a load of an offline, super easy to retrieve it. So you can as a user can come in and start retrieving it. So in this case, I'm just going to try and retrieve the data from the we're going to do the offline in a minute. But I'm going to do the online example. So sorry.
Of course of the live demo for some reason, but this is the command to retrieve it to retrieve and then quickly show you basically the payload, we can see the actual payload that was retrieved. And this retrieval can happen in like milliseconds, right. So because we are using a really fast online store, you can get the data out in milliseconds. And then you can have some millisecond latency if you need to, depending on the requirement of the model. Well, once the data is in here, I can now do something interesting, I can go to something to like drive a car, for that matter, you can use park or some other tool. And you can just go directly and connect to the feature store, you go and select the project you are looking for. In this case, I'm going to use the minute demo project. And within that project, you can go look at the feature sets that are available, right. So what are features that you want, pick it and start using it. In this case, I already ingested the data. So let me just go and show you. So the data will show up over here. Once you click ingest. That means that the data has been retrieved and put into the into the Travis CI instance. And now I can operate just like any other dataset. I can then do details on it. I can look at the rows, I can build models off of it, and so on. And once I build the model and deploy it to production, I'm ready deployed to production. I I can use the same online store to score it right. So my ml ops instance can basically call features an online store, score the results with our model and then deploy, right. So all this can be done very seamlessly. One other nice thing you could do is, let's say you build a model in driverless AI. And as you are familiar, diversidad, not just builds your great model, it also does feature engineering for you, it can create some really nice features for us, in this case, creating like an interesting feature, cross validate, target encoding, or maybe it's something else that you find useful, you can use the module to publish the features back into the feature store. So if you saw some really nice features created by driverless AI, you can put them back into the feature store. And basically that becomes a new pipeline, you create a new pipeline that will publish features into the feature store. Okay, so that was a very quick overview of what the feature store does. This is again, available in our React clouds available, it's going to be available very soon in our managed products, worlds, if your customer wants to try it out, let us know we'd love to do a POC and like show you how it can help you in your AI journey. Any last thoughts prints on this? Project on mute.
Sorry, one point you mentioned about you showing the demo of the Jupyter Notebook. It can work the same CLI functions across any, any any ml pipeline, right. I mean, whether you're in snowflake, whether you're in data, bricks, or in a Palantir of sales for like, it could be any pipelines. The CLI is makes life easier from feature store. And we use the same piece of code all the time. And it really works. So you can for example, you can create these features, you know, being in Jupiter pipeline, let's say but your scoring pipeline is completely different, let's say in snowflake, but still, you can use the same features using the online feature store or even offline to just store the time of the scoring. So that's why it's kind of a work across all these tools and technology. But keeping all this in one place. And another point that I would also mention is that data privacy and compliance, because this feature is you know, democratizing these features across different views in your enterprise. But at the same time, it is also well handled in terms of the data encryption and security about these features. And, and, and also the PCI RPI and SPI information. And, and there is a little bit of an internal process that you want to do it right. I mean, a company like a TNT forest, it's very important that there are privacy and compliance and even the ethics of this AI. So you know, that's also been baked inside this feature store. That's why it's makes life easier, just a one place and and really helping us bring the data scientist or data analyst, and our business people and the lives on legal everybody in one place. But it's centralized, and it can be reused. So so that's the, that's the power of our future stories here. And that's how it's helping at the end to democratize the, across the enterprise.
And then prince, I think a lot of you can share this, but just talk about scale, right, like think add on, if you're able to share how big of the how many feature sets, you mentioned, a lot of features with like, just from the size of data, how much you're loading?
Yeah, I mean, it's a different in our teams, they are bringing the data in different sizes, right? I mean, it's sometimes I would say, if I want to just maybe, quote not necessarily internal at&t data, but we also get data from external. And we could able to load, you know, two terabytes of data, like in the form of the features, like there are like two or 200 features and two terabytes of data, we could be able to load it in 30 minutes of time into the feature store. Right? That is a one thing I would say in offline data ingestion interfaces to standpoint. Number one during the online scoring, we want, you know, the feature of lookups at runtime, during the scoring time in less than 50 milliseconds. So that's also happening, right? So it's happening both sides, I mean, whether you're going with the big volume, or how fast you want to retrieve the feature. So. So that's the that's the good numbers, I would say, considering an a big ml operations,
that I think speed and performance are the key, right? That's the fundamental currency, like that's the right. There's all the bells and whistles, but their core is need to be able to handle large volumes of data scale, and then performance, right? So in terms of speed, right, being able to retrieve the features as fast as possible, as required for a particular application. So thank you for taking the time again to join us was as always a pleasure to talk to you and your insights are very valuable for me. And I'm sure the audience as well, God. Okay, thank you.
Thank you. Thank you.
With that, I'm going to bring up some other innovations, we have automated slides. So we're going to call upon Dimitri Gordeev, who's our camera and master and senior data scientist, who's also the lead for pm for our hydrogen torch product. So I'll let him come up to stage and present. Or do Dimitri
Thank you going out. Let me start with sharing my slides. Today I'm going to talk about H2O Hydrogen torch. And we'll focus more on the new features which we have worked on over the past few months. But let me start with a few words about what hydrogen torch is and just to get everyone on board for those who haven't worked with it or haven't seen it yet. Install headers and porches our deep learning engine is it was mentioned it's a no code engine. So it is designed for for junior data scientists, first of all, so for those who don't have much experience in deep learning, to be able to deliver state of the art a world class deep learning models very fast, as well as we also aim at the audience of some Senior Computer Vision engineers with a very heavy functionality we built in into hydrogen porch and we continue to add every quarter with with hydrogen porch at hand, we are enabling our users to solve their own Deep Learning use cases. So we start from ingesting the data, and all the way to the business application of your particular use case. So we start from consuming the data and enable the data scientists to set up the problems to set up the treat the model architectures to set hyper parameters, tune the hyper parameters and make the best out of it. So not only build a predefined model, but also to make the most accurate model possible given given the data. And the and the limitations in terms of how large the model can be. Data scientists can inspect the results, evaluate the models get some insights about how the models work, and how do they make predictions, retrain the models, whenever needed. And of course, seamlessly deploy to our HTML ops, which is running on a cloud or any other Python environment of choice. As soon as the model is deployed, we can it can run on on the hardware of your choice of your choice. So we're we, we care a lot about de latency here as well. So it can support some real time applications as well. And you can consume it either through waves, wave apps, or your own UI interfaces. Or you can just use the REST API calls and integrates deep learning models directly into your back end, front end systems. With deep learning, we focus on the types of the applications where deep learning shines the most, namely unstructured data. So we start with, with textual applications, NLP tasks with computer vision, which, which is applied to images and videos. But we don't stop there, we're going to grow a number of unstructured data types we can consume, and we can build deep learning models for right now we focus on not only images and text, but we also introduced audio as another type of input. I'll mention, I'll talk more about it in a bit. But I want to emphasize that Unlike typical classical machine learning, where we focus usually on classification and regression, in deep learning, we have actually a wide wider range of the problems we are solving. It is caused by the fact that the models are can sometimes output the full texts or images or detects something in the text or images for an audio. So there's like a whole range of problem types that you can solve with deep learnings which go far beyond typical classification and regression. And as you can see from the slide, we cover a lot of those. I believe we cover all the most typical and most common types of the use cases. But of course this list is not not. It will we'll be adding more and more and driven by during bar requests from our customers and, and the use cases we see out there. I'm not limiting by my computer vision and NLP we're also adding we've also added audio support. But of course, we will be adding more and more types of data as well.
Let me talk a little bit more about the audio functionality, which you can find in hydrogen torch now, we've added support of audio classification auto regression tasks to hydrogen torch. So we can upload your audio recordings to the tool and run deep learning models and built state of the art classification and regression models. What we do is actually quite quite an interesting approach which, which has proven to be state of the art approach in the competitive environment. So that's how the best audio deep learning models built these days, we convert the audio into usage on the right hand side into the spectrograms, which are nothing else but images. And we apply computer vision models actually to audio data. That brings us many benefits. First, we applied the best neural network architectures out there because they're well designed and tuned for computer vision tasks. Second, we do transfer learning, which allows you to build better, more accurate models with less data. And third, we can apply older computer vision techniques like data, augmentations, and so forth. To get the most out of the limited dataset you might have attend.
One of the new features you might find in the new release of hydrogen Forge is deep learning interpretability. That's an extra functionality, we're adding to multiple types of the of the tasks. Basically, at the moment, we'll cover all three NLP computer vision and audio analysis with it. So for NLP tasks, for your models, you will be also able to see not only predictions, but also word important so which words in the texts drove the predictions that will help you analyze what drives the model how the model works. So that will give you not only the flavor of how the model behaves, but also can can be helpful if you apply this technique to each individual predictions. So with a prediction, you will not only see what the model believes believes in the true prediction, not only the not the confidence, but also kind of an explanation which words which phrases are are the drivers of the decision made by the model. A similar approach with a completely different technique is applied to computer vision tasks. Here, you see a very simple example of a machine learning model of a deep learning model classifying pictures of flowers. And here we apply a technique called Krabbe camps, which also highlights the areas of the image which drove the prediction made by the model. So which areas of the model which areas of the of the image are important, case by case, and that at first, first of all, helps to validate the model in terms of making sure that the model focuses on the things which are important for us. So we see here that the sunflowers are recognized based on the sunflowers and not the background of the images or something, which is clearly unimportant. So the model is actually learning how the flowers look like and learn is learning how to distinguish distinguish them by the looks. And the third is audio. As I mentioned before, we're applying computer vision techniques to audio. And one of the extra benefits we get here is that we can apply graph camps to interpret the audio predictions as well. So not only you get the predictions, but you also get the highlight areas of which parts of the audio drove the predictions and even which ranges of the frequencies drove the prediction. So that also helps you to understand how model behaves may validate in terms of understanding of what makes the predictions. What makes the most important, highest importance in making predictions for the model. And also to check on examples whenever needed, that the prediction was made, right and using the the correct pieces of the data. We're working on. We're working on more features. For instance, we're adding features for automating the search of the models. Right now you have an opportunity to not only to start a new model, but also trigger a new search and find the best hyper parameters So, can I automatically tune the model and make even better model than you might have out of the box. And with lots of customers, we see that there is a struggle with getting proper sized data sets because labeling is challenging. A very typically data labels are not available or are costly to, to acquire. Therefore, we're introducing a new application which is integrated into HDI cloud and very tightly integrated with hydrogen torch that is focused on data management and data labeling. With this application, you will be able to, to collect your textual or image data, audio data will come with the with the next releases, and do the annotations depending on the type you want. On the type of the task you want to solve. classification regression. And in this example, we have entity recognition where, which is designed to build a models that recognize parts of the texts or individual words, you will be able to utilize this tool already on AI clouds. As I mentioned, it's well integrated with hydrogen torch. So you can you can upload your data, you can manage your data there, you can manage your annotation pipelines there. And you can directly move the data to hydrogen torch and build a model from there.
1:31:32
Together with texts, we're also introducing data labeling for images, also classification regression, but also object detection types of the annotations. Of course, we will be adding more and more types of annotation depending on the requests from our customers. But already now we'll cover most of the typical use cases we face whenever we run QC, or POCs, or projects with our customers. Besides the integration with the platform, I would like to emphasize the fact that this tool runs fully inside your environments. So the data never leaves your environment, you don't have to send it over to cloud to cloud provider or any external company. So it is very secure from the data privacy point of view. And the last point I would like to mention about the data labeling here is that this application will also grow and provide more and more functionality, not only than in the direction of data labeling, but also in the direction of active learning. So we're going to be adding one by one features that will give you AI assisted data annotation techniques. So you will have an AI helping you to get together to make better annotations to make faster annotations and to make them more efficiently. Yep, thanks a lot. And I'm going to pass it back to the notes. And if you have any questions, please paste them in chat. And I will I will answer them
Thank you, Dimitri, for the wonderful presentation, I think, some phenomenal dates there and new innovations there. Next up, I want to introduce Karthik Goswami, who's open source solution engineer. He's going to present some of the innovations and what we have done on document AI. Or do you Karthik?
Thanks for not Hi, everyone. So what is the document.ai? Solutions clutch product that runs on presto. Okay, so it supports both web interface and, or you can access by API, what it really does is you can actually upload, you know, various image scans, like faxes and PDF docs, or pictures with text, right, or even, you know, Word docs and XML pages and emails and whatnot. And once you upload it, you know, we take it through a couple of stages, that you can actually build a model, and then you'll be able to infer documents and do things like pace classification or token classification. Okay, so before you ask me, oh, is this another OCR? The answer if it's not, it's OCR is a small part of the entire solution. So we do what is known as an ICR. Right, intelligent character recognition, right. So you have heard your products in the past like Tesseract and things like that. It allows you to extract those you know, words and letters and whatnot from the text but it really doesn't understand doesn't have Bachman understanding. Right. So doctrine understanding requires a couple of things. One also have been one part of it. The other part is like, where's the text laid out there? A document and the other one is, and then can you do like named entity recognition and understand, you know, words and keywords and stuff. So this solution combines all of it and stitches together in a very interesting way. It is Sebata code free environment of this means that for most part it works. But if you really want to add some code to enrich the pipeline, you can totally do that at the end. So, let me give you a idea what this can do. Okay. So I have a bunch of documents that I'm going to just pull it up. And let's wait for it. Okay, there we go. Let me move my Zoom. Okay. There we go. So this is a lab test document, right? A scanned, obviously, somebody's standard. And, obviously, all of these and anonymized. So it's pretty cool to show this right? So there's no PII or anything like that. But you can see here, there's various different information like, you know, facility name, first name, last name, that's, you know, all those panel tests, most of us are familiar with. And then there's another lab report that has no facility name, slightly different layout, perhaps somewhat the same information, right. So basically, if you want to sort of generalize this, as I go through it with you, and get into like, very interesting formats like this, right. So all of them have the same information, but just laid out differently. So this makes it very hard for OCR tool, like your, you know, traditional old scaffold to go and pull all of this up, and then format it, and then you can put it in a database or extract information. So this is where document AI comes into play, right? So you can bring all of these documents into the product. And then you can start annotating it right, like create some sort of a schema, you can say, hey, you know, these are test description, right, and you don't have to do it one by one, you can just draw a rectangle on top of these, you know, layouts. And then a document.ai is intelligent enough to understand that it's actually a table and has different roles, and can actually extract those can identify them separately and extracted. You can see like, now we are dealing with document of various different templates, perhaps the same information. So as a user, you need to actually go in and update some of this. So let me quickly show you what that is, the tool looks something like this. And I actually drag and drop all these documents into
this tool earlier. You can see like the tool, this particular one that I'm showing you right now has got 1514 documents, whereas 24 pages, so not all documents have to have the same number of pages, as long as you can find the information in one or more pages, we can totally bring it in, and then you know, and we can actually build models of it. Okay, so let's let me go ahead and click that. So let's see, yeah, the same document that I showed you, it's in the system, right. So one of the things to note here is that we have a document, that's a little bit, you know, you can have documents that are even slightly skewed doesn't have a perfect rectangle. Sometimes I've seen this work, you know, iPhone images, that was a little bit tempted, but you don't really want to make sure that it's readable, right in some way. And then you know, you're gonna have, you can see, like all the pencil marks here. And you know, it's not a perfect document. And that's exactly what this tool is designed to handle. Right, as long as it's readable, as long as reasonably good, you can actually bring it in. Now, once you bring it in, there are two things you can do. Like I said, OCR is a small part of it. And so we have to run the OCR on it. So you can go to this document and say, Hey, run my OCR, it's going to take care of, okay, you're gonna get the OCR. So let's quickly look at the OCR part, and then we'll go to the labeling part. So here we go. This is OCR. Okay, so it basically extracted all the terms that it found all the key words and terms and dates and whatnot and Numerix and all of that, it found it great. It doesn't mean anything, because it does still doesn't know what this table is or what the rows are. So you need to actually tell document or AI that, hey, this is a test, right? Something like that. So let me see how I did that. So once you bring in a document, you can actually annotate it, we have an an manual annotation tool that you can go to the place and pick the regions of interest. And you can give it some names like facility name line, custom, so these are named entities that are creating and associating with regions. Okay. Now, so for zoom in a little bit, you can see like I have already annotated this, it's telling me the facility name. So easy if you want to do a date, we just do this and then a create a label called date and then you add shows up in the drop down box, like a test date, right? Sorry, this date of birth, so maybe you want a date of birth here. For one, two, okay, so you can pull it up. So easily transmitted through in this case, I annotated the entire table, so you don't have to do one by one. So once you do all of that, the next thing we're going to do is to combine the OCR annotations together and stitch it together to create some sort of data that's ready for training. Okay, so here's your OCR labelled data, this was like, there's a way to combine it, I'm not gonna show you like every step. But once you have these tools, you can go and say, annotate and apply labels, and you're gonna get this. So it goes here. And this is the fully annotated and OCR data. So let's go in and look at one of one of the documents. Okay, I know it's crowded, so I'm going to zoom in a little bit. There we go. Okay, you can see a facility name, the text is LabCorp. Right. So basically, it's used it used your annotation and use the OCR, and it created some sort of a connection between the reason your entity and OCR x. So all of those preparations don't document they are the only thing you need to stand at it. Now the question is, do I need to have 100,000 documents? Do I need to annotate repos on optim? For trading? The answer is no. Okay, so because we have pre trained layout Allah models, you can actually label a sample of these documents, that has a reasonable representation of the rest of the documents. And then you can, when we actually train the model, we'll be fine tuning an existing, pre trained model that was already trained on level a million documents, right? So it's transfer learning, and then we're just updating the embeddings by creating a training class, okay. And then once you create a model, it's very easy to go back and then deploy it. So let's go back to the projects.
Okay, you can say published pipeline once, and then it's gonna ask you for a model name to create the model, and then you're gonna get a REST endpoint, okay. And once you have at a certain point, now, from the client or an application, you can basically load a PDF or image, you can upload it, and we'll show you the steps on how to do that there's documentation on that. And then once the document comes to the REST endpoint, the OCR will be done, the model scoring will be done. And you're gonna get a JSON output that talks about which region which named entity that you define, and what is the text that was found, right, that can be used for downstream application. So here's an interesting thing, we just don't do predictions, we also tell you how confident we are, in terms of what we're finding, right, we say, okay, 80%, or 90%, confident that the label that I picked up was in the prediction. So then you can add something like a post processor, you can do it here itself, or you can add a final pipeline to sort of curate the output that is coming. And then you can decide whether you want to present that prediction confidently to the downstream application. So this is something you can do in Python, you can upload it, you get a handle on the JSON, and you can just convert it into a CSV file or whatever format that can go into a database or, you know, to a downstream application. So that's, you know, that's what the tool does. So just to summarize, so basically, if we just look at a high level, what it does, it allows an enterprise to go beyond OCR based template methods, right, and also our robotic process automation, this tools, which are generally focused on memorization, and all the documents are to be the same in the exact same place, this one is highly intelligent, you know, have a much better understanding of the documents. And it also gives you a hand to go and, you know, are Tell, tell it like where to find things initially, not exactly in the same place, but kind of put identities around it like bounding boxes, and then it lands. The whole point is at a lower operational cost. Imagine processing like, you know, 100,000 documents, right? Really quickly, like get through the day, right, I'm able to generate the predictions is a highly efficient, and overall, you know, if you're a business where you have to respond to customer fairly quickly based on what they uploaded. So this allows you to create customer satisfaction, right, much better customer satisfaction. So that's all I have for document.ai. I understand the question, I can answer this question on the chat. I'm going to pass the ball back. Molto, I guess, Vinod and Michelle to an expert. Yeah,
thank you. Thank you Karthik. For the one for everything document is like really powerful technology that can allow us to process you know, all kinds of formats, different innovative and non templated. Use cases so highly encourage you to try it out. It's available again on our managed con and Rei club as well. But then I'm gonna choose Michelle Tanko, who is the product manager for AI cloud and vive And then App Store itself. So she's going to talk about all the innovations coming up there, or to Michelle.
Great. Thanks, Anna. All right. So we've talked about a few different things today. But I want to give a quick overview of our MDM platform, the H2O ai cloud. So everything you've seen so far, and that you're going to see later is in this end to end platform. This includes our feature store for understanding your features and handling feature pipelines. Otherwise develop models so deeply models with Dimitri Karthik to show this document, I will talk to Megan soon about our distributed ml and maybe auto ml as well. And all of these options are available in one place. So this is a scalable platform for your organization. As Vinod mentioned earlier, this can run manage, so hosted by H2O, so you don't have to worry about the Kubernetes, infrastructure, any of that, or it can be hosted in your organization, which some of our larger customers are doing. They have that type of IT support. This runs in Kubernetes. So it scales up and down as your end users need more engines for building models or more apps for showing results to end users. And it comes with everything we've been doing at H2O for the last decade. So AI engines for building your different types of models, whether this is distributed models in our open source platform H2O, three or driverless AI for automated machine learning with that genetic algorithm that finds the best algorithm for you, hydrogen torch for deep learning, and docky AI for our end to end documents solutions. From building these models, I'm so sorry, I'm gonna mute for just a moment.
All right, after we build our models, we can use ml ops to deploy these models. And we'll see that today and run them in production. And our deployed models help us enable the App Store which has our AI applications. These are apps that are built by H2O, and also built by you in our organizations. So we have data science, best practice applications. And then we have core vertical applications in healthcare, financial services and templates so you can easily get started making your own. So with this review, we'll go ahead and get into what's new in the end to end platform. There's three main things I want to show you today. The first is we now have a hosted solution for Jupiter lab. So you can run your notebooks directly from the environment, you no longer have to access API's from your local machines or your local developer station. It's fully hosted by us in the Cloud Platform. And then we have two new features for managed cloud, I want to talk about some improvements for our object storage that allows you to upload your data once and use it throughout the entire platform. And then some admin features that will be interesting for admins in the managed cloud environments. Alright, so here I am in the H2O ai cloud homepage, we talked about this on the last Innovation Day. But this is a landing page for everything you might want to do on the platform. Different types of users might see different things here. But at the top, I can see my main end to end workflow, I can upload data, I can access the different types of money building tools that I want, I can see my deployed models. And then I can also access everything via code. I'm a data scientist or someone that uses Jupyter Notebooks. In the center, I have things that I specifically own, it's just going to be a little bit different for every person. App instances are UIs. For applications that I specifically own, and might want to access regularly, my favorite apps are in the center. And then anything as a developer that I personally uploaded will be here so I can access it easily. And we can see other interesting things lower in the cloud. So the first thing I want to talk about is our new managed notebook solution. So directly from the app cloud, I can go into the details of the H2O ai notebooks, which is instances of Jupiter labs. Now why instances is interesting is because each person can run one or more Jupiter lab environments. So here I can see several people have public instances of Jupiter labs running. And if I go click visit, it will go into my latest version of it. In this environment, it comes automatically setup to easily use the app cloud environment. So we are using the data science Docker image. So it comes with things like psychic learn and other model building tools installed if you want it, we also have access to all of our API's. So there's some example data that you can use for playing around. We also have example notebooks, an end to end demo that shows you how to get into driverless AI, how to build a model, how to then deploy that model into ml ops and start scoring predictions. And then we have deep dive tutorials for each of our products. So how to manage your AI engines and keep track of resources, how to build and understand automated machine learning and so forth. And then if you're not familiar with Jupiter labs, it's really easy to take one of these tutorials, just duplicate it, and then change it to your own use case, and you can run all your Python code directly from here. You don't have to install any libraries or anything, although you can because you have access to this environment. One of the things I wanted to show you related to this, though, is you have control for each of your instances of Jupiter labs, and of all apps in the App Store to say if it's only for you, or if it's for all users. So I can go into my instances, which is the app instances that I specifically own. And I can see that I actually have an instance of Jupiter labs That's private. So I have some notebooks in here that I don't actually want other people to run or look at, I'm not ready to share them yet. But when I have an instance, that's all users, then what I can do is I can send the link to a notebook to one of my colleagues, and they could run it, or they could copy it or use it in their own environment as well. So it's a nice way to start to do collaboration on code or model building together. Alright, so next, I'm going to come back to my homepage, and I'm going to go to drive, where I'm going to show you how we can upload data and some new features in the drive. So the purpose of drive is to be one place to organize all your files are using the cloud. So feature store is focused on our features that we use for model building, it shows you the overview of features, you can see the summary statistics, and so forth. But drive, we might not just have datasets, we might have the output of machine learning models, whether that's predictions, or a mojo or auto doc, and all of that can be saved in one place. So I can access it in different apps, different AI engines, and so forth. So you don't have to spend a lot of time uploading and downloading data and moving all around, it's just in drive for you.
One of the new things in Drive is a nice import manager that allows you to import multiple files at once, a lot more smoothly. So we wanted to show that today. So I'm going to choose to import from s3. But as you can see, there's lots of different connectors available to me. And from s3, ahead of time, I went ahead and put in my credentials, these are saved for me securely, so that I don't have to import them every time I can just access it. And if I have multiple credentials, I can set up those different profiles as well. So I'll use those credentials. And I will get the link of where my data is. Some public data, and then I'm just gonna go ahead and hit next. And I'll choose a couple files that I might be interested in. Let's let's play with the airline sentiment. So after I import these, um, these aren't necessarily particularly huge files. But oh, that's fair, I imported those earlier today. So this is nice, it's checking for me if I really do actually want to import these datasets and overwrite them, I'll go ahead and give them a new name. In this case, it will be okay to override but just in case. And we'll we'll show all and we can see the import manager here. And I can watch as each file imports. If one of these was say 100 gigabytes or something that was a bit larger, it would take longer to use. But I'd be able to use all the other files while it was going. I'm going to now take us really quick just to show you how we can then use this dataset and other places. I'm going to go into driverless AI.
it's gonna redirect from me, there we go, the gun and driverless AI. So this is our tool for automated model building. We're not gonna go through it too much right now. But I just wanted to show how we can then use the data that we just imported. So I'll go back to the root here. And I can see, here's my airline sentiment two that I had just added. And I can go ahead and add that right into this instance of driverless AI. So we don't have to re import it from s3, or worry about certain credentials here. Alright. And then the last thing I want to show you is some of our new admin features. So I'm going to come into a different environment where I happen to be an admin, because these are features only available to admins. So yeah, anyway, I'll come into Admin Center and visit this application. And, again, this is for our managed club customers. So you don't have to be like a Kubernetes admin or understand the backend it. But there are things that you might want to do to be able to control and understand your environment. So I can do firewall management, which essentially says, by default, any IP can access the cloud environment, but you might want to make this more strict. So the reason that it would be nice to access the environment is maybe I don't want to use the Manage notebook solution. I really want to run the the notebook on my local machine for whatever reason, then I'd be allowed to connect from my local machine. So that can be controlled here for security. And the other way around, you can let the iCloud access or not access outside resources, so our admins can make sure they understand the security here of who's talking to your platform and who's not. The user management allows you to add new users into your environment. I'm not going to show everyone's email today. But you can easily add and remove accounts and change access. And then the newest feature here is our AI unit consumption. So the app cloud platform is consumption based, we're looking at how often and how many resources and AI units which is based on storage, and memory, and CPU, and GPU are being used all at once. So here admins can easily see what our consumption is what capacity it is. So this environment has access to 14 units. Right now we're using less than one, so we're really low on capacity. But we can see over time, if there's any spikes. Right now, as I'm doing this demo, there is a higher spike, of course, and so forth. So this gives our admins a little more insight and visibility into what's going on in their platform, in terms of what it might end up costing them. And then there's a little bit more details about the environment. Alright, so at this point, I'm going to go ahead and stop and introduce our next presenter, who's going to be Abhishek Moto, who's going to talk about ml ops and responsible AI.
Awesome, thank you, Michelle. And hey, everyone, good to see a lot of good engagement coming in, in the chat, and making sure that we're getting all of your questions answered. So I'm going to talk about ml ops and responsible AI, as Michelle just mentioned, and I want to kind of start off the overall conversation going a little bit deeper on ml ops. So just before me, Michelle had started talking about what is included in overall H2O ai cloud. And this diagram over here starts to talk a little bit more about deeper level information on ml ops, and what is really part of that. So ML Ops is your end to end place where you come in to manage, deploy, and monitor your machine learning models. So from a H2O ai cloud standpoint, and ml ops standpoint, we're completely agnostic towards whatever the model is that you've got, whether you've trained the model on HBOs engines, or you've trained the model outside of that. Our model management and ml ops capabilities is able to be agnostic towards any of those, and take you through the overall workflow of Model Management, deployment and monitoring. Effectively, anything that comes after the model gets trained, all throughout our ML ops platform. We also enable a lot of different third party integrations that allow you to use your favorite tools, and bring them into and connect them into issues ml ops. And then we also provide lots of team collaboration management analytics capabilities, governance capabilities, and infrastructure that allows you to configure your workflow for the best possible scenarios that you've got within your organization. And all of this wants a model to actually deployed and be monitored, that gets consumed into a variety of different AI applications. Whether you're building this directly into a end user application, or you've got some level of predictions happening within a tool that you've got a scoring internally, all of that can be made possible through our H2O labs. So that's a very quick overview on what H2O ML ops actually is. And now let's dive deeper into what are some of the new innovations that have happened within this space. The first thing I want to talk about is our enhanced modern monitoring capability. So some of our customers in the past have gone through and use our existing modern modern capability. And there have been some friction points with our SSO or single sign. We have now brought in our model monitoring capability all within the same application of ml ops. And our users are able to interact and get all of their monitoring details for the models all in the same place. You're able to get details about your model health, your model prediction details, the features that are getting consumed the most, as well as a drift that is happening on your features over time. So of course, this is where we're kind of starting off bringing everything together in one single place for our customers, lots more capabilities that are coming up on top of this suit. So that's really the first thing I want to talk about is the enhanced model monitor.
The second capability I'm super excited to talk about is our age. chooose model analyzer. This is a brand new product that we are that we've been working on for the wild. And we want to release now to our customers, which helps our users and our customers start to understand how robust their model is. And the way we talk about robustness is really to look at some of the edge cases and edge areas where the model has not seen any data around seeing how the model behaves in those spaces and see if the model is actually perturbing or changing the prediction value, or not based off of something that the model has not actually seen. So there are a few different techniques that we have enabled within each was model analyzer, we have things like counterfactual explanations, which help our users understand the closest example within a dataset that actually perturbs a prediction or changes the overall prediction. We also have adversarial explanations, which goes in and tries to break the model actively, and figures out what is the smallest amount of feature change or feature value change, that would actually perturb the prediction. And it also allows you to do what if analysis, you're able to look at all of your feature values, change any number of them, and change the value for them. And see in a what if basis, what happens to the overall prediction. And all of this data really kind of goes in, and you're able to save it in order for you to retrain your model, and make the model more robust. So let's take a look at how that works. So you can access each tools model analyzer from our east to AI cloud. Right here, I've got the model analyzer app as it panned out for myself. So I'm just going to click here. And once I click on visit, it's going to open this application. So in this homepage, what I can see is I've got a number of different datasets and models that have been pre loaded. So I'm just going to click quickly click on one particular dataset. So over here, I've got my entire data set, and I've got a model already loaded for it. And I can see there's about 6000 different values that are over here that are paginated across the existing. So what I really want to do is try to see for a given given datasets, so for example, rows, index one and index two, what is the closest way I can perturb it or figure out what is a weak point for these particular data points. So I'm gonna click on Run, and then start, I'm going to choose all of the features because I want all of them to be made available for myself, before I actually go in and start to exclude any. So all of these features are available to be changed in order for me to to change the prediction. So the job has been finished. And I can click on view the report. And over here very quickly, I can see that for each of the rows that I had predicted, or that I had selected, I'm able to change particular values, change the education value from three to two, eight from 49 to 37. And then be able to choose a model prediction of values from a 65 to a 41. And similarly, for the other data point that I've actually looked at as well. For that I had to change a few different values, as you can see an orange and that change the overall model prediction value from 71, to 42. So this is really, really important when we as a data scientist when we as model, validators want to go in and try to identify what the weak points of the model actually are. And then I can use the results that were produced based off of this to go ahead and start to go ahead and use the new data points and see if the prediction value is actually accurate or not. And I can go and retrain the model and use these data points to make my model more robust.
So that's, that's one capability that this tool provides being able to see the adversary examples. The other thing is I'm just gonna click on one particular value and I can see all of the features that I have within this particular model. And I can go right to the bottom and see what are the explanations for this. So which feature is the most contributing the most positively or the most negatively tomorrow prediction? And this allows me to do conduct what if analysis on my side so for example, I can look at the value of pay five and start to change this up since it has the most. It has the highest feature importance So I can change the value from two through seven, go to my inference tab and predict, or I can go from seven, back to negative two. And click predict based off of that, and see how the model predictions actually changing. And once again, this what if analysis helps our customers, our users identify where the model can potentially break. So extremely powerful tool that we think our customers are going to have a great time playing around with, and making their model more and more robust. So that's model analyzer in a nutshell, the next feature that I want to talk more about is our experiment tracking feature. And within our ML ops, experiment, tracking is also brand new, and a term that is getting more and more popular amongst the overall ml ops industry. So within H2O is experiment tracking, we're allowing our customers to log their model parameters, artifacts and metrics programmatically. In order for you to keep track of all of your experimentation details, data scientists that we work with, they some, they are running 10s, if not hundreds of experiments, all in parallel, with slight modifications on their parameters. And what they're really looking at understanding is how does each experiment and yield different overall metrics. And traditionally, our customers have done this all throughout a spreadsheet and a really manual way. And experiment tracking really helps our data scientists automate that process, visualize our process, and helps them create an end to end lineage for their experiments. So let's take a look at what that looks like. I thought experiment tracking currently running in a Jupyter notebook right now, effectively just initializing the experiment tracking client from a side and then getting all of the modules installed. And then at this point, I can start to get my user name registered and getting the overall client registered. So I seem to get my authentication token really quickly, which I'll do right here. And the input the values that were here, and I am authenticated. At this point, I can go in and start going ahead with my register with my iterations. So I'm just going to register an iteration name as any name, and then start to log parameters. So over here, I'm logging two parameters over here, running that, and that's starting to get registered, registering some metrics, for example, RMSE, and r squared, and also registering artifacts. So very quickly, as you can see, I can incorporate a couple of lines of code within my overall experiment codebase and start to log details of what is the actual feature, what is the actual parameters that I'm logging with, or sort of trying to experiment with? What are the output metrics, and any artifacts that are associated with my experiment. And just like that, I can head into a UI that we've built out, that we're actually consuming right now from the open source AMOLED flow platform. And we will see over here that h two Innovation Day, that's what I had named my experiment, all of these different parameters and metrics and artifacts that have logged, you can view them over here. So these are all individually logging metrics, parameters and artifacts. But what we have over here is also a integration with an H two or three model. So a model is getting trained over here, and it starts to log all of the parameters, metrics, artifact details, it's just running the overall this code block right now. But what we'll see is very quickly, as I refresh,
we are now logging our RandomForest h two or three model. And it is now all of the metric parameters are getting captured over here. All of the metrics are getting captured over here, and any metadata values that have sent it. So this is super, super powerful for our customers who are looking to experiment with lots of different experiments all in parallel. And let me show you how a comparative view actually looks like on this as well. Because once we have many, many different experiments happening together, we want to be able to compare the values. So I've got a second learn model and I've got to use two or three random forest model, I'm going to select both of them and click Compare. And I can start to visualize the different values that I'm getting from or that I have inputted in and logged into each of the different models, I can look at the different run details, I can look at different parameters that went in. And I can look at metrics that should be logged here as well. And that helps me very simply compare my different experiments against each other, and helps the data scientists really go ahead and select the best experiment that they have underside. So going back over here and finishing off some of the new innovation that we've built out over here, we think this is an extremely powerful product within the overall ml ops portfolio. That helps our users track the end to end lineage of their experiment, compare experiments, very simply log out the details in one place that they can then pull afterwards. Now, as well as visualize all of the results on their side, such that they can view compare and contrast the experiments that they have run. So that's really, in a nutshell, what we've got over the last couple of months. So a quick overview on a roadmap, we're looking at doing as well to enhance the capabilities even further of ml ops, we're looking at enhancing our experiment tracking capability, and integrating that directly with our east to ml ops, such that you can log in experiment detail within experiment tracking, and then very quickly bring them to ml ops for deployment purposes. So that's a capability that we're working on integration. And that's going to be available very soon for all of you. And we're also looking at enhancing our model explanations at runtime within ml ops. So previously, a lot of our customers have been using our popular feature of getting explanations at runtime for models that are in the Mojo format, we're now going to be opening that up into getting explanations for models that are in the Python scoring pipelines. We're also within monitoring, we're going to be adding much more capabilities around feature importance and dataset management. And for our another monitoring monitoring addition, we're going to be allowing our customers to do third party deployment monitoring. So models will be able to be able to deploy it anywhere outside of the H2O infrastructure. And monitoring could be done by H2O.
So that in a nutshell, is what we're what we have been up to. And we are going to be working on on ml ops to give you a bit of a view into the overall product. And now I'm going to jump into our responsible AI portfolio. Responsible AI is if you've been using H2O for a little while, you know that H2O has some of the more powerful machine learning interpretability and responsible AI capabilities across the market across the industry. So we have just as a recap, over 20 different techniques that are available through our driverless AI a product which allow you to interpret models in a wide variety of different ways. And what we're looking at doing now, and we're happy to announce now is opening that up the capabilities and the power that we have built out within driverless AI for our MLA and opening that up to any product, any framework and any model that is that you are building your model for. So we are launching H2O sonar, which is a library a Python package that has a wide variety of responsible AI methods and techniques, all into a single place. So if you are looking at operationalizing responsible AI within your organization, you no longer have to go through lots of different libraries with inconsistent formats and consistent data ingestion, and come straight to H2O, sonar, and be able to get all of your responsible AI needs, irrespective of what frameworks or models you're working with. So this is absolutely brand new. And we're watching this right now. The model frameworks that we are currently supporting our psychic learning issue are three on top of the Jarvis AI ones. And we will be adding more and more frameworks on top of this. And the current methods and techniques that were supporting our shared values, partial dependence, so PD and ice decision tree surrogate model, disparate impact analysis or DIA and Colonel chefs feature importance. So once again, these are also the capabilities that we currently have right now. And we will be expanding this and incorporating all of the innovation that we've already done on the driverless AI ml AI side and bringing that into H2O Sona. So let's take a look at how that works. So once again, I'm going to go into my Python notebook. And I've got a PD ice explainer that I've got as a notebook kind of running over here. So just importing all of the necessary libraries and datasets, I can then go in and run the actual explainer, the PD ice explainer, which gives me all the details for the explainer right here. So all the different parameters, all the values that I can go in and look deeper into, that will be outputted. At this point, I want to make sure that the model that I have is also loaded. So over here, I've got a psychic learn model that is loaded and set up. And with this, I can run the actual explainer on the model that I've got. So now that the explainer is actually run, I can now run this code block to get the actual results and get a summary. So the summary of the PT ice is a shown very quickly as the calculations are done. And then not just that, I can then hit a couple of visualization and charting outputs that we've got, in order for me to actually see the result in data for any particular feature. So for the education feature, I can see the PD values, or the pay for which is a feature that we've got, I can see the values for that as well. So that's just a tabular view that we've got going, you can also visualize this in any way that you want as well, we got a couple of samples over here for both education and pay for. And you can see very quickly that I can visualize the PDU results in a histogram or a line chart format. And we also have the capability for us to save and log all of the data and the output that we've got in a few different libraries of scale. So all of this is available for us to use. We are we have released this in a limited preview at the moment. So if you are a customer of ours, and you want to try this out, please reach out to your account manager and we're happy to get you access. So you can get going on this.
So that is what the team has been working on so far. But what is coming up next for Responsible AI. And I'm happy to talk a little bit more about the roadmap on AI governance. So AI governance is something that we are currently working on very, very hard on trying to help our customers operationalize responsible AI within their organization within their teams. What this is going to actually incorporate is a dashboard that we can provide to an executive audience, that gives them an overall view of risk for all of their AI projects across the organization. It's going to have a set of tools that our AI practitioners or AI project teams can use to identify any areas of concerns, run off the tests that are needed, and tooling to help remediate any of the issues that are over there. And also a system of record that is helping our customers and organizations store, manage and retrieve any of the data and metadata that is needed for the AI projects. So we're excited to be working on this right now. We think it's gonna be incredibly valuable. Some of the customers that we have had early conversations on, they've had very positive feedback on this so far. And we're going to be happy to show how this is all coming about at the next event. And with that, I will pass this on to Meghan Kircher, who is going to be talking about H2O Three. Hi, everybody.
All right. So I'm gonna be talking a little bit about each two or three and some of the capabilities available there. And I'm a data scientist at H2O Nagin just as an introduction, and I work with them the H2O three and driverless products. I was going to talk a little bit about each row three today just to end the discussion. H2O Three is our platform for distributed machine learning. It's completely open source, and able to ingest large amounts of data by creating clusters. So you'll see it on the screen. We have a bunch of different algorithms in H2O, some supervised and unsupervised, we also have auto ml there as well. And then with H2O Three, you can launch a cluster as large as you want that can ingest the full data set, and then you're able to interact with it from different languages and IDE s and today I'll show a quick demo of using our hosted Jupyter notebook to run a model with H2O Three. In this talk, I'm going to be focusing on anomaly detection in H2O Three. We've had anomaly detection for some time, but we've recently added extended isolation forests which I'll discuss and I wanted to bring to the forefront. So how can we essentially find out are suspicious behaviors in our data, even if it's large data. And some of the reasons why we might want to do that is fraud detection, sensor malfunction, help with stock trading or even detecting bot. So anomaly detection is really great if we want to be alerted that something strange is happening with our data, but we might not have a label for it. So we've been talking a lot about machine learning, and labeling and so on. And this is a great setup, if you don't have labels for when things are fraudulent. When there's a bot per se, or there's been a malfunction, you just want to know when there might be something alarming happening in your data set. So anomaly detection goal is really to figure out the general patterns that are happening in your data and identify places where that doesn't fit. There are three methods for anomaly detection needs two or three in an unsupervised manner. So unsupervised, meaning I don't really have a label for when things go a wire, but I want to figure out if I can detect that in advance. The first is clustering. So each two or three offers k means clustering, again, on a full distributed data set. To find natural segments in the data, we can use this algorithm to determine which observations cannot be clustered well, so an observation that can be clustered well doesn't somehow fit in with the rest of the patterns. The two or three also has dimensionality reduction algorithms, which learn a low representation of your data. And it uses this to find common patterns in your data. What we can then do is figure out which observations can be easily reconstructed. So where does that low dimensionality model get things wrong. And then finally, our most recent algorithm is isolation forest. And what this does is it trains trees in your dataset to determine how easy it is to separate an observation from the rest of the group. So observations that are easily separated, are more likely to be anomalies. All three of these algorithms and techniques are available in H2O Three, they're distributed, so they're going to work with your full data set. And what's nice about all three of these things is that they produce a mojo. So you'll get a Java object that's independent of each two or three, so you can use to kind of deploy an anomaly detection model in production. So what's new in anomaly detection, we've added extended isolation forest, it's a, it's an algorithm that removes the bias of isolation for us. And it's especially beneficial when you have wide data. We've also added some tutorials on how to use anomaly detection. And I'll show a little bit about how we can put that all together. So maybe anomaly detection is only my first step. But as we talked about in the panel, there's also the work of engaging with our business group explaining why something is an anomaly production, Ising it and so on. So when I talk about putting it all together and explaining it, and what we can do with H2O Three is not only build these algorithms to predict which observations are anomalous, but we can explain that. So here for example, I have some home price data I have identified from my isolation, isolation forest model that this is anomalous. And I can get the Shapley reason codes about why there why it is anomalous. So I built a surrogate model, I'll show the tutorial and in a minute, I figured out which variables lead to a high anomaly score. And then I get at a individual level information about why this record is strange. So now I can go ahead and take this information and provide this to a business group or explain each anomaly as it comes up to better identify why it is strange and what we should do about it.
So putting it all together in the AI cloud, although H2O Three is available, everyone can try it with the AI cloud, I can kind of add steps together to help me make this information available to a large variety of users and to speed line, this particular use case to monetizing my business. So I can define the objective, start building experiments in this case with H2O Three, explain them just like I talked about, we can also enable a bigger group with some low code apps. So I'm going to just show really quickly a wave app that I built that combines the results of H2O three so that I can show CryptoKeys to a large user and then evolve how can I monetize this information of when something is anomalous to help help optimize my goal. So let me just jump to my demo really quick. So here's our AI cloud environments. As Michelle showed, we have a Jupyter Notebook. Here I've connected to my age two or three cluster, I've imported some data. And I built an anomaly detection model to figure out which records are anomalous. I can then explain it with a surrogate decision tree model and figure out what's leading to anomalous scores, explain them and explain them at a at a particular individual level. So this is something common that a data scientist would do. But I can also put all this together are in an app. So here's a wave app, we've as our open source software, a Python library that allows to make low code, dashboards and applications. And I've made an a dashboard that's interactive, that showcases the results of my H2O three models. So even though each two or three is really running, distributed and running on large data, I can reduce the size of the data down for a dashboard purpose, see where my anomalies are located in a two dimensional form, get a nice table with my anomalies, and then even click and view more details. So with with the AI pi, we're able to kind of put all this together and showcase the results to a wide variety of users and see, see how it can be helpful for the business. All right, with that I think we're about at the end of time, so I'll pass it over to Vinod to to wrap everything up. Thank you.
Thank you. Thank you, Megan, for the wonderful presentation. Just want to bring Michelle back real quick to just talk about some of the new updates on beam. Michelle, if you already know Michelle.
I'm getting there. We're just at time, I didn't know we were gonna come back. Yeah, just take one minute. Yeah, sure. So Melinda showed us the wave website, but really quick H2O Wave is a SDK and Python and R that allows you to build front end applications. So when you think about the Machine Learning workflow and building your models, if we build a model that can say, for example, predict churn, we might want to know if churn happens or not. For our customer support team, when someone calls in, well, they're not going to run a curl command to a model deployed in ML ops and try to get a prediction, having some sort of interaction with a front end, that allows us to do something with our predictions can be really helpful. And a lot of the times our data scientists don't necessarily have a full stack skill set they might not know front end developing like HTML, or JavaScript or CSS. So wave has a component library that allows you to easily build interactive front ends, like the one Meghan just showed, and then deploy those into the cloud or the App Store. So what we're going to talk about for Wave today is a new feature called wave studio, that actually allows you to start building your applications directly from the AI cloud. Or if you're running away completely an open source, you can run this on your local machine as well. But you no longer have to use your favorite IDE like pi charm VS code, or VI, if you're really cool, you can have an IDE directly in your browser. So I'll go ahead and show you what that looks like.
So I'm going to go back to my cloud environment. And I will go ahead into the App Store and specifically search for the app I'm interested in which today is Web Studio. And we'll run into it. Again, each user can have their own instance of this app. So I'm gonna go to mine where I'm building my own applications. Alright, so here's an app that I've built. And it's deploying it for me, but I'm going to actually go into the studio, it's a different, slightly different URL in this application. And here you can see my IDE. So on the one side, I have the different projects that I'm working on in code that I'm writing. And then here is a render display of the app and building. I can choose if I want to see the console logs, which might be interesting to know how my app is running and logs that I might print out to it as a developer, I can just do the code if I want to. And again, this app is actually running here. So if I want to see it full, I can come into the new tab here. This is a Live ID and editor. So I added in this nice little card as I was testing, but I can delete it, and it goes away. We do have UI hints for wave. So I can say I would like to create a new card. I want it to be called my card. And then what do I want it? Well, there's a lot of different types of cards, but I might want this one to be a header card. Let's do a search for header. And this is gonna go ahead and populate the text me for a header card here. So we need to give it a location, a title and a subtitle. I mean, get rid of this card at the top. I don't need it while we're talking right now. But it's gonna go in the top right hand corner, it's gonna go all the way across the screen and be one unit tall. And I'm gonna say my test with no subtitle. And you can see that app is updating live as we go. So we can write our code here, see it rendered directly. And then if we wanted to, we could download this application. Some exciting things coming to you in the future for this for like automatic deployments of cloud and so forth. But we just wanted to show you what is coming next. And this is available for you to start playing around with in our open source, PR branch. Great. Thanks.
Thanks, Michelle. Thanks, everyone for staying on. Loads is a fairly long remaining webinar but some financial questions, we'll try to answer some of the other questions that came out separately outside of the call, or thank all the panelists earlier and all the product managers for coming in presenting with you. So there's a ton of phenomenal announcements we had. Starting with a feature store going to Harding torch, we're with the labeling app, and also the audio use cases that are being supported. Now coming to Emma labs, we have a lot of new innovations like experiment Tracking Model analyzer. We have sonar, which is our responsible AI library for model explanations, we have a lot of exciting things and document AI. How Kopparberg tea that can be to solve a lot of use cases I've been in car before in H2O, and not to mention the cloud itself and be managed to three. So I encourage everyone to go try it out, go to insurer AI slash free or go to the main website. It's called the homepage as a call to action. You can go sign up for our free trial and start accessing all these capabilities immediately. So let us know what you think. If you have questions, concerns, hit us up by email or go join our community slack. It's a great place to interact with all digital product managers on the team.
Awesome. Thanks for Thanks, everybody for attending. We really appreciate it and yeah, we're innovating on your behalf. So let us know what you need and and we'll keep making.
Thank you all have a good day