


Predictive Modeling at Scale: Cisco Modernizes Predictive Model Production with H2O (joint work with Lou Carvalheira)

Cisco’s Challenges
Cisco is the global leader in networking. It is a company that has long embraced the power of predictive analytics. On a regular quarter, Cisco’s Strategic Marketing Organization builds and deploys around 60,000 predictive models to treat each of 160M+ companies it maintains in its database. These models generate predictions that help determine which companies are more likely to buy specific products in the following quarter. The predictions are used by marketing and sales teams from Cisco and its partners to guide and prioritize effort and investments, particularly in the mid-market, partner-led company space.
More accurate and 15x faster than previous solution on a 4-node H2O cluster
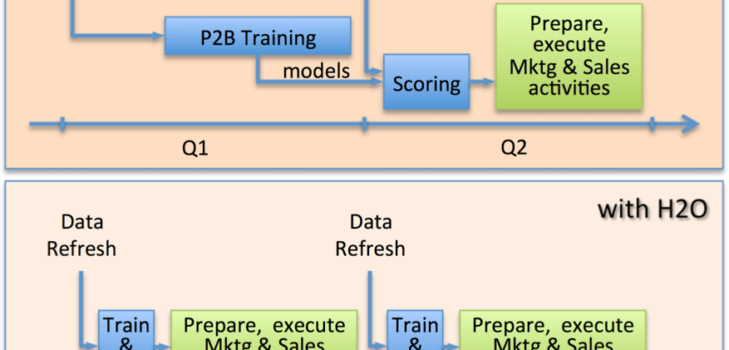
In the last 8 years Cisco has developed and refined what it calls a Propensity-to-Buy (P2B) factory, a set of data preparation procedures, model training and score deployment. The processes also include the generation of control groups that are automatically embedded in the deployment of all models and used to evaluate the real “in the field” performance of each of the models Cisco produces.
As Cisco grew its products and services portfolio, as well as its prospects’ database, they encountered serious speed and scalability challenges in its analytical environment. Due to the dynamics of the technology market, buying patterns change very rapidly: products that only large companies bought a year ago are now more and more common among medium and small companies. To adapt to those quickly changing conditions Cisco recreates all its predictive models from scratch every single quarter. However, training and testing 60,000 models and scoring them against 160M companies took more than 4 weeks with the tools they used before. And that, using only standard techniques (decision trees and logistic regressions ), no ensembles or grid search for best models. To avoid even longer processing times the models were trained on relatively small samples, rarely larger than 100 thousand rows. With such tight schedule, a mistake of any sort inevitably meant long hours for the data mining teams and opportunity cost for the business
Cisco needed to modernize and expand its predictive model factory to produce models for more products, using more of the immense amount of data available, increasing accuracy and doing it much more quickly than before so that more time is available for preparing and running campaigns, marketing and selling activities that will contribute to turning a prediction of a purchase into a real business transaction.
The Solution
After evaluating several big data machine learning platforms, Cisco chose to partner with H2O. It chose H2O because H2O offers an in-memory distributed machine learning platform that is bigger, faster, better, and less resource-restrictive:
- Faster. Big-data machine learning algorithms are mostly implemented as MapReduce jobs (e.g., in Mahout). They are disk-based algorithms that trade speed for scalability. H2O implements distributed machine learning algorithms in-memory, and are usually 100 times faster than MapReduce.
- Bigger. With its unique in-memory compression techniques, H2O can handle billions of data rows in-memory, even with a fairly small cluster. We are frequently seeing 50-100x reductions in data size in memory after compression.
- Better. In addition to common ML algorithms (such as logistic regressions, linear regression, generalized linear model, Naive Bayesian, etc.), H2O implements best-in-class ensemble algorithms such as Random Forest and Ada Boosting at scale. Customers can build hundreds of simple models and combine them to get the best prediction results. H2O also implements deep learning algorithms that power state-of-art use cases.
- Less Resource-Restrictive. Data compression and in-memory processing enables H2O to handle a large data set with a lot less machines, even when more sophisticated models are built. This is particularly important for departments who do not have the resources or expertise to operate a cluster with hundreds of machines. With H2O, a few machines may suffice.
In addition to these advantages, data scientists at Cisco also find H2O very easy to use. First, it does not require substantial change from their current way of doing data science . H2O implements almost all common machine learning algorithms, so data scientists are just using a new tool, instead of learning new algorithms. Second, H2O is easy to learn and use. H2O has a web interface that does data ingestion, munging, model building and model comparison, all very intuitive to new users. It also has an R interface that allows R users to use H2O without leaving the R shell. Third, because building a model is a lot faster in H2O, H2O is highly responsive compared to legacy vendors. Data scientists can build “what if” models and quickly see results to improve their models. Fourth, H2O’s REST API makes it very easy to deploy and/or integrate. It could also generate self-contained, high-performance Java code that can be embedded in customer’s workflow.
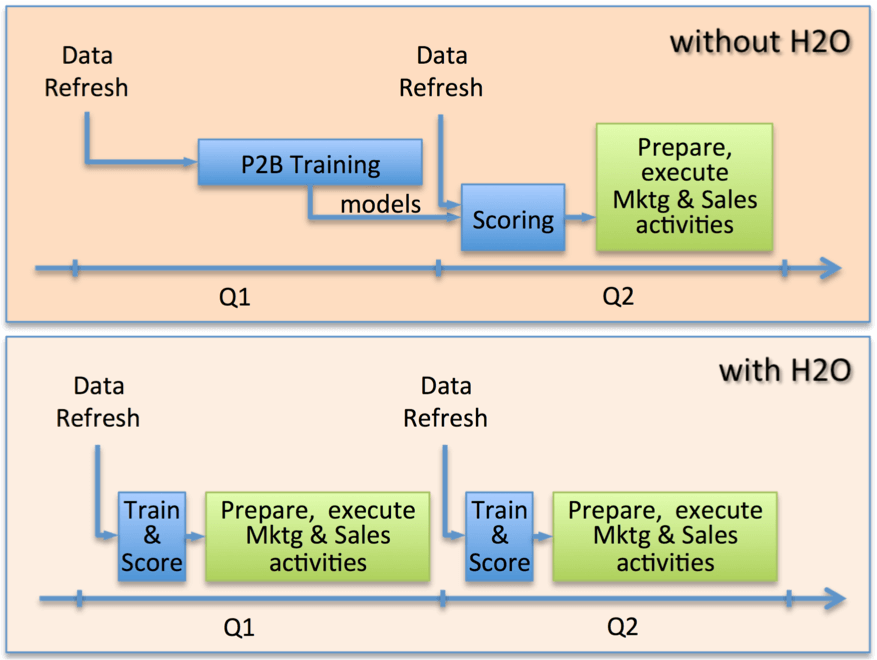
The results: quicker, more accurate predictions and more time spent on the actual deployment of the models.
With H2O, Cisco can now run models with much larger datasets. Instead of having to use small samples from the available data when creating its models, Cisco is currently using millions of observations during model training, while still respecting deadlines for model publication.
Running larger models also makes predictions more accurate. Technology buying patterns are similar to waves: they originate in the industries and countries where innovation and early adoption of new technologies is a common strategy and then flow to other industries and regions. A Cisco product that is early adopted today by Financial Services companies in US will be common in Brazilian Retail companies tomorrow. In order to identify those waves and characterize the buying profile of each company it is important to have all historical data from all markets available for modeling in a tool that can handle large volumes of information in a reasonable amount of time. H2O’s fast and scalable machine learning capabilities were designed to address that very challenge.
On a 4-node cluster with 24 cores and 128GB memory each, Cisco can now run its P2B factory to train models for the same amount of products, scoring all 160 million companies in a couple of day’s worth of processing, a fraction of the total time it took the old factory. The unprecedented speed has encouraged them to create models for more products, with more historical data on the companies, and experimenting with different techniques. Harder problems are treated with the heavy weapons from the deep learning and gbm algorithms while simpler challenges are tackled with the extremely quick glm and random forest techniques. By choosing specific techniques according to the importance and complexity of the prediction problem, Cisco was able to improve the accuracy of the models and the speed at which they’re produced.
In short, H2O has significantly improved Cisco model factory’s speed and throughput, enabling sales and marketing to predict customer behavior sooner and more accurately, and leading to more efficient targeting of their customers.
With H2O, Cisco can now run models with much larger datasets. Instead of having to use small samples from the available data when creating its models, Cisco is currently using millions of observations during model training, while still respecting deadlines for model publication.
Running larger models also makes predictions more accurate. Technology buying patterns are similar to waves: they originate in the industries and countries where innovation and early adoption of new technologies is a common strategy and then flow to other industries and regions. A Cisco product that is early adopted today by Financial Services companies in US will be common in Brazilian Retail companies tomorrow. In order to identify those waves and characterize the buying profile of each company it is important to have all historical data from all markets available for modeling in a tool that can handle large volumes of information in a reasonable amount of time. H2O’s fast and scalable machine learning capabilities were designed to address that very challenge.
On a 4-node cluster with 24 cores and 128GB memory each, Cisco can now run its P2B factory to train models for the same amount of products, scoring all 160 million companies in a couple of day’s worth of processing, a fraction of the total time it took the old factory. The unprecedented speed has encouraged them to create models for more products, with more historical data on the companies, and experimenting with different techniques. Harder problems are treated with the heavy weapons from the deep learning and gbm algorithms while simpler challenges are tackled with the extremely quick glm and random forest techniques. By choosing specific techniques according to the importance and complexity of the prediction problem, Cisco was able to improve the accuracy of the models and the speed at which they’re produced.
In short, H2O has significantly improved Cisco model factory’s speed and throughput, enabling sales and marketing to predict customer behavior sooner and more accurately, and leading to more efficient targeting of their customers.