A Deep Dive into H2O’s AutoML
The demand for machine learning systems has soared over the past few years. This is majorly due to the success of Machine Learning techniques in a wide range of applications. AutoML is fundamentally changing the face of ML-based solutions today by enabling people from diverse backgrounds to use machine learning models to address complex scenarios. However, even with a clear indication that machine learning can provide a boost to certain businesses, a lot of companies today struggle to deploy ML models.
This is because there is a shortage of experienced and seasoned data scientists in the industry. In a way, the demand for machine learning experts has outpaced the supply. Secondly, a lot of machine learning steps require more experience than knowledge, especially when deciding which models to train and how to evaluate them. Such gaps are pretty apparent today, and a lot of efforts are being taken to address these issues. Automated Machine learning may be an answer to such impediments, and in this article, we shall understand in-depth how that can be achieved.
Automated Machine Learning: AutoML
Automated machine learning (AutoML) is the process of automating the end-to-end process of applying machine learning to real-world problems. AutoML tends to automate the maximum number of steps in an ML pipeline — with a minimum amount of human effort — without compromising the model’s performance.
Aspects of Automated Machine Learning
Automated machine learning can be thought of as the standard machine learning process with the automation of some of the steps involved. AutoML very broadly includes:
- Automating certain parts of data preparation, e.g. imputation, standardization, feature selection, etc.
- Being able to generate various models automatically, e.g. random grid search, Bayesian Hyperparameter Optimization, etc.
- Getting the best model out of all the generated models, which most of the time is an Ensemble, e.g. ensemble selection, stacking, etc.
H2O’s Automatic Machine Learning (AutoML)

H2O is a fully open-source, distributed in-memory machine learning platform with linear scalability. H2O supports the most widely used statistical & machine learning algorithms , including gradient boosted machines, generalized linear models , deep learning , and many more.

H2O also has an industry-leading AutoML functionality(available in H2O ≥3.14) that automates the process of building a large number of models, to find the “” model without any prior knowledge or effort by the Data Scientist. H2O AutoML can be used for automating the machine learning workflow, which includes automatic training and tuning of many models within a user-specified time-limit.
Some of the important features of H2O’s AutoML are:
- Open-source, distributed (multi-core + multi-node) implementations of cutting edge ML algorithms.
- Availability of core algorithms in high-performance Java. including APIs in R, Python, Scala, web GUI.

- Easily deployable models to production as pure Java code.
- Seamlessly works on Hadoop, Spark, AWS, your laptop, etc.
Who is it for?
H2O’s AutoML can also be a helpful tool for the novice as well as advanced users. It provides a simple wrapper function that performs a large number of modeling-related tasks that would typically require many lines of code. This essentially frees up the time to focus on other aspects of the data science pipeline, such as data preprocessing, feature engineering , and model deployment.
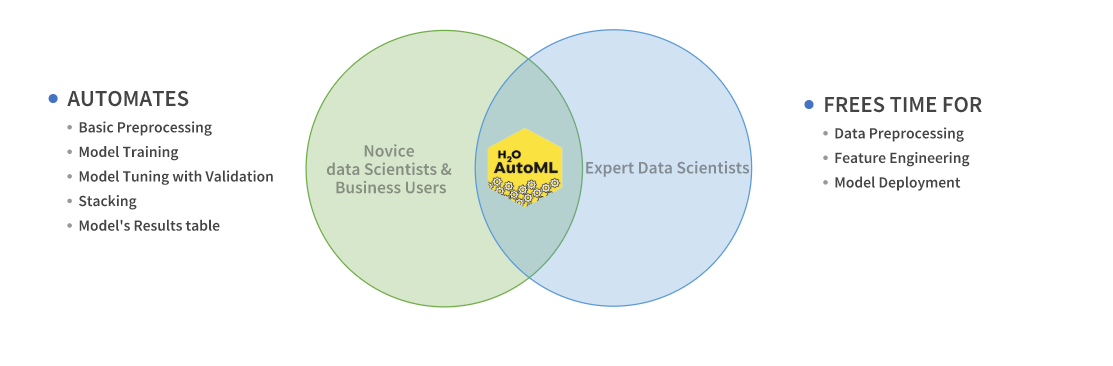
AutoML Interface
H2O AutoML has an R and Python interface along with a web GUI called Flow. The H2O AutoML interface is designed to have as few parameters as possible so that all the user needs to do is to point to their dataset, identify the response column and optionally specify a time constraint or limit on the number of total models trained.

Installation
H2O offers an R package that can be installed from CRAN and a Python package that can be installed from PyPI. In this article, we shall be working with the Python implementation only. Also, you may want to look at the installation documentation for complete details.
Dependencies :
pip install requests
pip install tabulate
pip install "colorama>=0.3.8"
pip install future
Installing with pip
pip install h2o
Every new Python session begins by initializing a connection between the python client and the H2O cluster .
H2O AutoML functionalities
H2O’s AutoML is equipped with the following functionalities:
- Necessary data pre-processing capabilities (as in all H2O algorithms).
- Trains a Random grid of algorithms like GBMs, DNNs, GLMs, etc. using a carefully chosen hyper-parameter space.
- Individual models are tuned using cross-validation.
- Two Stacked Ensembles are trained. One ensemble contains all the models (optimized for model performance), and the other ensemble provides just the best performing model from each algorithm class/family (optimized for production use).
- Returns a sorted “<strong”>Leaderboard” of all models.
- All models can be easily exported to production.
Case Study
Predicting Material Backorders in Inventory Management using Machine Learning

For the case study, we shall be working with a Product Backorders dataset. The goal here is to predict whether or not a product will be put on backorder status, given a number of product metrics such as current inventory, transit time, demand forecasts and prior sales. It’s a classic Binary Classification problem. The dataset can be accessed from here.
Reference
R. B. Santis, E. P. Aguiar and L. Goliatt, “Predicting Material Backorders in Inventory Management using Machine Learning,” 4th IEEE Latin American Conference on Computational Intelligence, Arequipa, Peru, 2017.
Methodology
The basic outline for this Machine Problem will be as follows.

We start by importing the h2o Python module and H2OAutoML class. This is then followed by initializing a local H2O cluster.
import h2o
from h2o.automl import H2OAutoML
h2o.init(max_mem_size='16G')
This is a local H2O cluster. On executing the cell, some information will be printed on the screen in a tabular format displaying amongst other things, the number of nodes, total memory, Python version, etc.. Also, the h2o.init() makes sure that no prior instance of H2O is running.
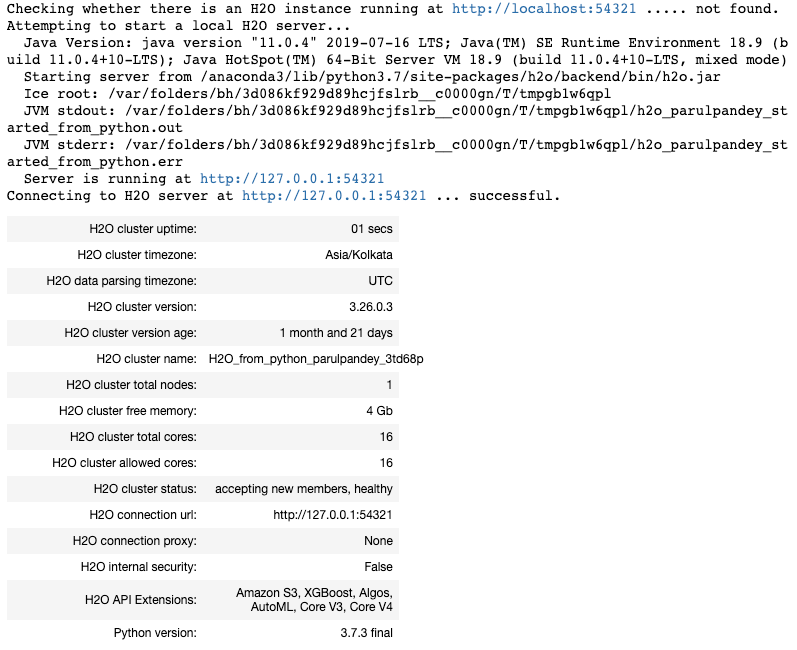
By default, the H2O instance uses all the cores and about 25% of the system’s memory. However, in case you wish to allocate it a fixed chunk of memory, you can specify it in the init function.
Loading data into H2O
Let’s importing data from a local CSV file. The command is very similar to pandas.read_csv , and the data is stored in memory as an H2OFrame .
data_path = "https://github.com/h2oai/h2o-tutorials/raw/master/h2o-world-2017/automl/data/product_backorders.csv"df = h2o.import_file(data_path)
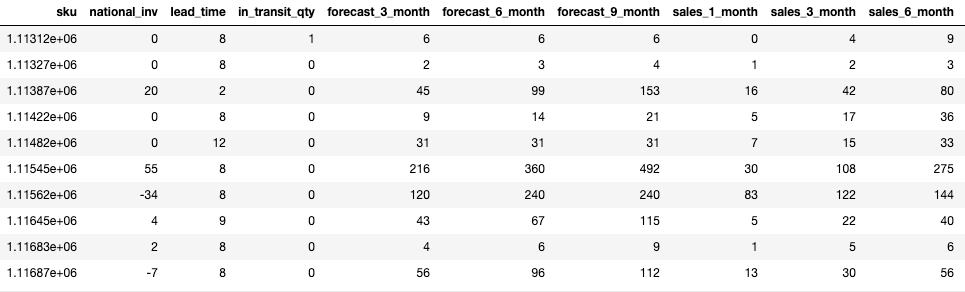
Let’s take a look at a portion of the data.
df.head()
print(f'Size of training set: {df.shape[0]} rows and {df.shape[1]} columns')
-------------------------------------------------------------
Size of training set: 19053 rows and 23 columns
Splitting the dataset into train and test datasets
splits = df.split_frame(ratios=[0.8], seed=1)
train = splits[0]
test = splits[1]
Specifying the Response and Predictor variables
Next, let’s identify the response column and save the column name as y. The response column is called "went_on_backorder" and represents whether a product went on backorder or not (a binary response). We will also remove the sku column since it’s a unique identifier and should not be included in the set of predictor columns, which are stored a list called x.
y = "went_on_backorder"
x = df.columns
x.remove(y)
x.remove("sku")
Run AutoML
Run AutoML, stopping after 120 seconds. The max_runtime_secs argument provides a way to limit the AutoML run by time. In general, it’s good to run AutoML for longer than 2 minutes, but it also depends on the size of your dataset. You could choose to run it for several hours or longer if you have big data.
aml = H2OAutoML(max_runtime_secs=120, seed=1)
aml.train(x=x, y=y, training_frame=train)
Required Stopping Parameters
There are two stopping strategies (time or number-of-model based), and one of them must be specified. When both options are set, then the AutoML run will stop as soon as it hits one of either of these limits.
- max_runtime_secs: This argument controls how long the AutoML will run at the most, before training the final Stacked Ensemble models. Defaults to 3600 seconds (1 hour).
- max_models: Specify the maximum number of models to build in an AutoML run, excluding the Stacked Ensemble models. Defaults to
NULL/None.
There are several optional parameters also which can be set, e.g.: nfolds, balance_classes, class_sampling_factors, max_after_balance_size, max_runtime_secs_per_model, stopping_metric, etc. You can read more about them in the H2O AutoML documentation .
Leaderboard
Next, we can view the AutoML Leaderboard. The AutoML object includes a “leaderboard” of models that were trained in the process, including the 5-fold cross-validated model performance (by default).
A default performance metric for each machine learning task (binary classification, multiclass classification, regression ) is specified internally, and the leaderboard will be sorted by that metric.
lb = aml.leaderboard
lb.head()
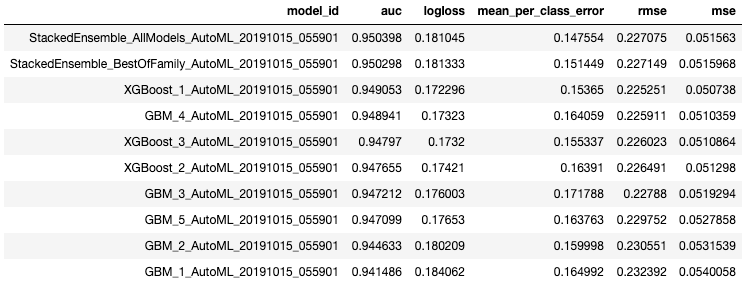
The leaderboard displays the top 10 models built by AutoML with their parameters. The best model is a Stacked Ensemble(placed on the top) and is stored as aml.leader.
Ensemble Exploration
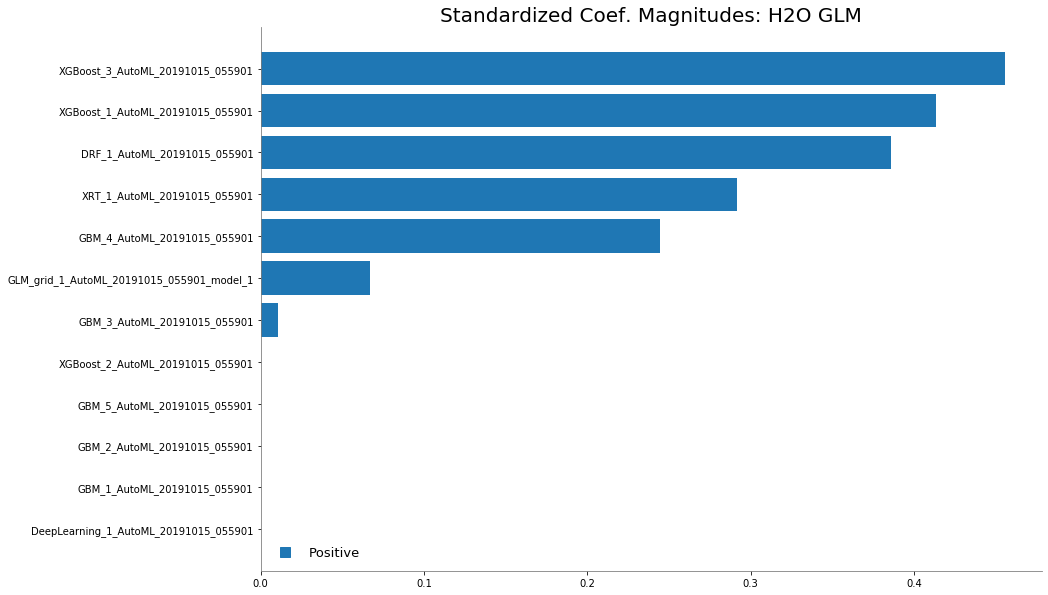
To understand how the ensemble works, let’s take a peek inside the Stacked Ensemble “All Models” model. The “All Models” ensemble is an ensemble of all of the individual models in the AutoML run. This is often the top-performing model on the leaderboard.
# Get model ids for all models in the AutoML Leaderboard
model_ids = list(aml.leaderboard['model_id'].as_data_frame().iloc[:,0])
se = h2o.get_model([mid for mid in model_ids if "StackedEnsemble_AllModels" in mid][0])
metalearner = h2o.get_model(se.metalearner()['name'])
Examine the variable importance of the metalearner (combiner) algorithm in the ensemble. This shows us how much each base learner is contributing to the ensemble.
%matplotlib inline
metalearner.std_coef_plot()
Predicting Using Leader Model
If you need to make predictions on a test set you can do that as follows:
pred = aml.predict(test)
pred.head()
Saving the Leader Model
You can also save and download your model and use it for deploying it to production.
h2o.save_model(aml.leader, path="./product_backorders_model_bin")
Conclusion
Essentially, the purpose of AutoML is to automate the repetitive tasks like pipeline creation and hyperparameter tuning so that data scientists can spend more of their time on the business problem at hand. AutoML also aims to make the technology available to everybody rather than a select few. AutoML and data scientists can work in conjunction to accelerate the ML process so that the real effectiveness of machine learning can be utilized. Check out the H2O AutoML User Guide to learn more!