







Image Tasks on H2O Driverless AI
I’d like to thank Grandmaster Yauhen Babakhin for reviewing the drafts and the very useful corrections & suggestions.
Introduction
In this talk Kaggle GrandMaster and Data Scientist at H2O.ai: Yauhen Babakhin shows us a few prototype demos of how DriverlessAI’s upcoming release will work with Image Data and the related tasks. The images and representations used in this talk and writeup are a teaser to the product, Grandmaster has told me that the team is currently working on the UI and it might vary slightly
Teaser: We will have GrandMaster on The Chai Time Data Science Show once the Official releases of Driverless AI for Image Data are out. Stay Tuned for that 
Why Image Data?
As you might know, DriverlessAI currently works with Tabular Data, TimeSeries Data, and Text Data.

The next missing piece in the puzzle would be image 
Problem Types
Computer Vision Problem Types include:
- Classification:
The goal here is to classify the image as belonging to a class. Ex: Hot Dog or Not Hot Dog. - Semantic Segmentation:
The goal here to label the pixels for certain classes. - Classification + Localization:
The goal would be to first, classify the image to a certain class and then localize the position of the object in the image. - Object Detection:
The goal here is to detect the objects inside the image. - Instance Segmentation:
The goal here is to detect objects in the image and segment them at a pixel level.

At H2O World, Grandmaster Babakhin had shown us two prototype demos for Classification and Semantic Segmentation. However, the other categories are also being tested at the time of writing.
Challenges to building models for Deep Learning
There can be multiple hyper-parameter that we need to set:
- Learning Rate
- Optimizer + Loss Function
- Batch Size + Input Size
- Architecture
Training Process also involves a lot of decision making to be done:
- Number of Epochs
- Cropping Strategy
- Augmentations
- Learning Rate Scheduler
Training Models with DriverlessAI:
Driverless AI selects the optimal strategy for selecting all of the hyperparameters listed above.
Architectures:
- You could start with an ImageNet Pre-Trained Model.
Currently, Over 30 Pretrained models are supported:
– (SE)-ResNe(X)ts
– DenseNets
– MobileNets
– EfficientNets - Use a custom Architecture Instead.
- NAS: Run a Neural Architectural search
Once the architectures are defined, various dynamic techniques are also applied while training. For instance:
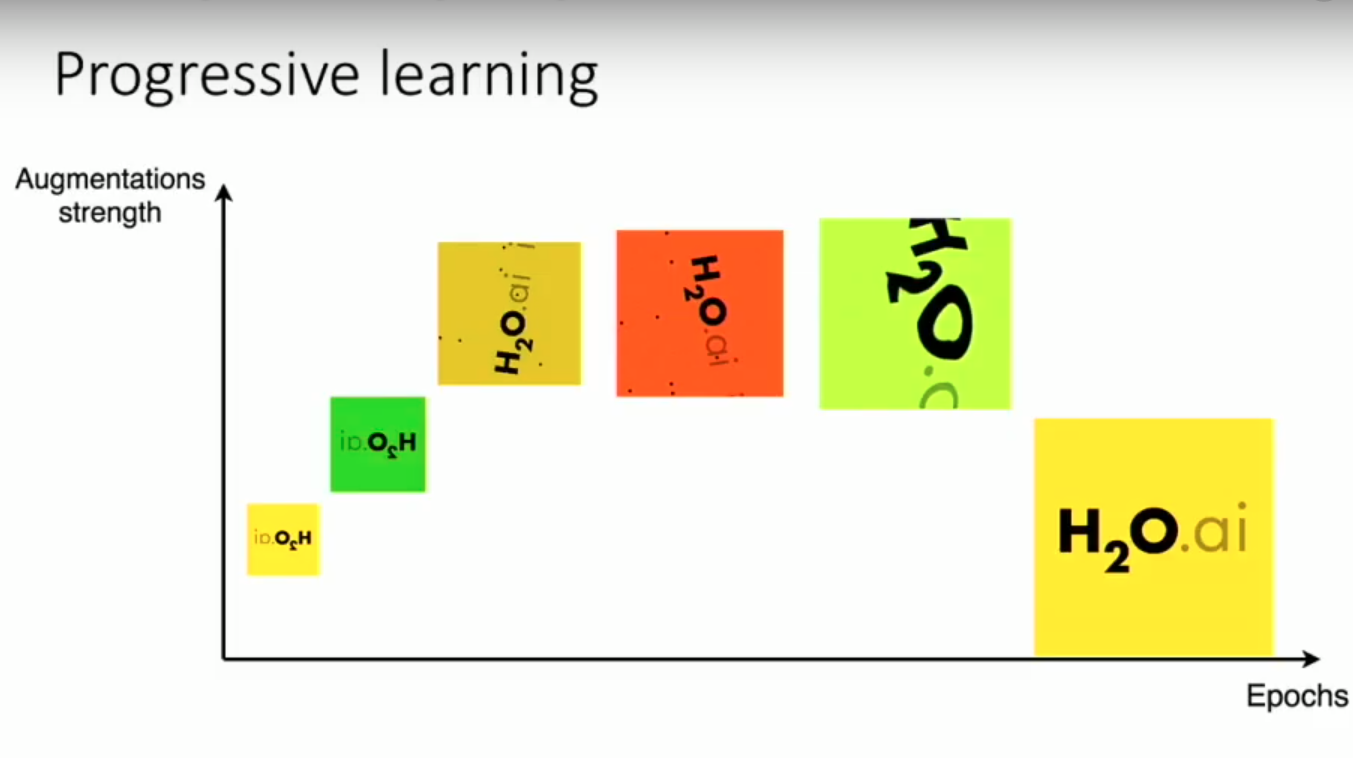
The image shows how the augmentation + Image Size can be varied while training a model.
During the initial stages, we’d like to train on a model of small size with fewer augmentations followed by more rigorous augmentations during training which then are reduced towards the end of the training.
Example based on a Simple Use-Case
The talk demoed a simple-use case of a task from a Competition by Intel on Analytics Vidhya.
Note to the reader, the goal here wasn’t to show the performance of DAI for the task. A little teaser from GM Babakhin tells me that the performance is already in the gold medal zone for older kaggle competitions and medal zone for the recent ones!
The idea here was to show-case a potential interface.
Checkout the Dataset here
Goal:
Image classification with 15k train images and 6 classes:
- Buildings
- Forest
- Glacier
- Mountain
- Sea
- Street
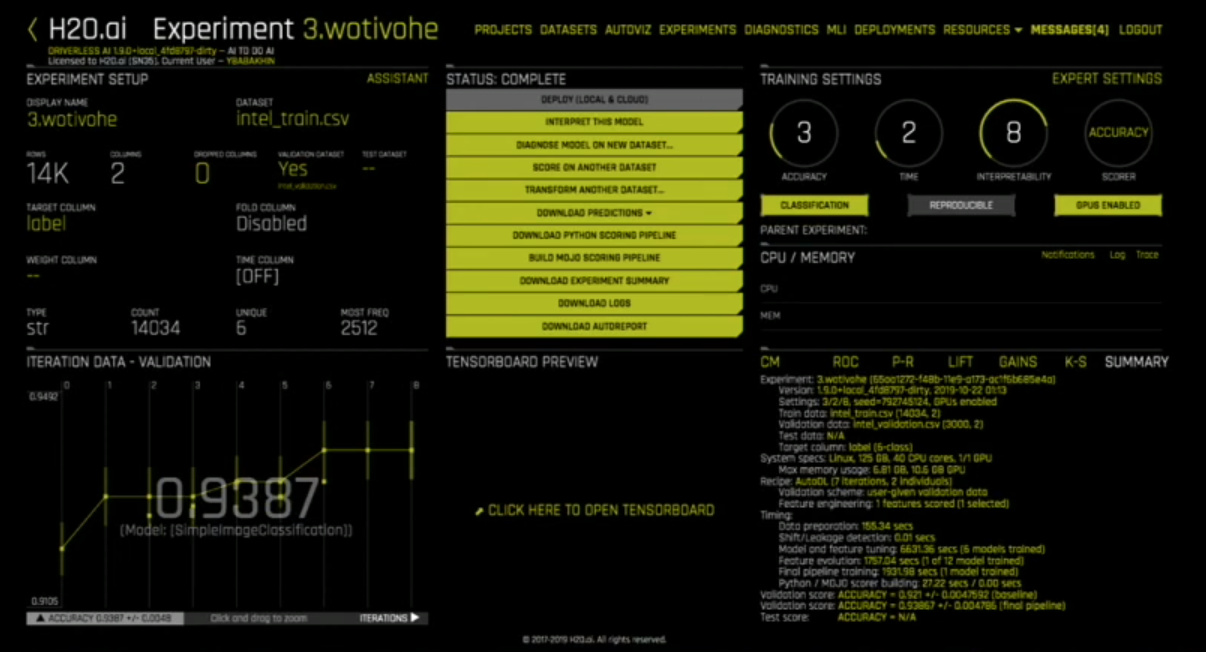
DriverlessAI Interface:
You get the familiar “Iron Man Console” (Note: these are my words, but you can’t deny that  ) with a single zone dedicated to TensorBoard after you’ve pointed DriverlessAI to the dataset path.
) with a single zone dedicated to TensorBoard after you’ve pointed DriverlessAI to the dataset path.
Note that the datasets are expected in a certain format: For example-considering classification as a task: it should be a .csv file with the path to the image and image label.
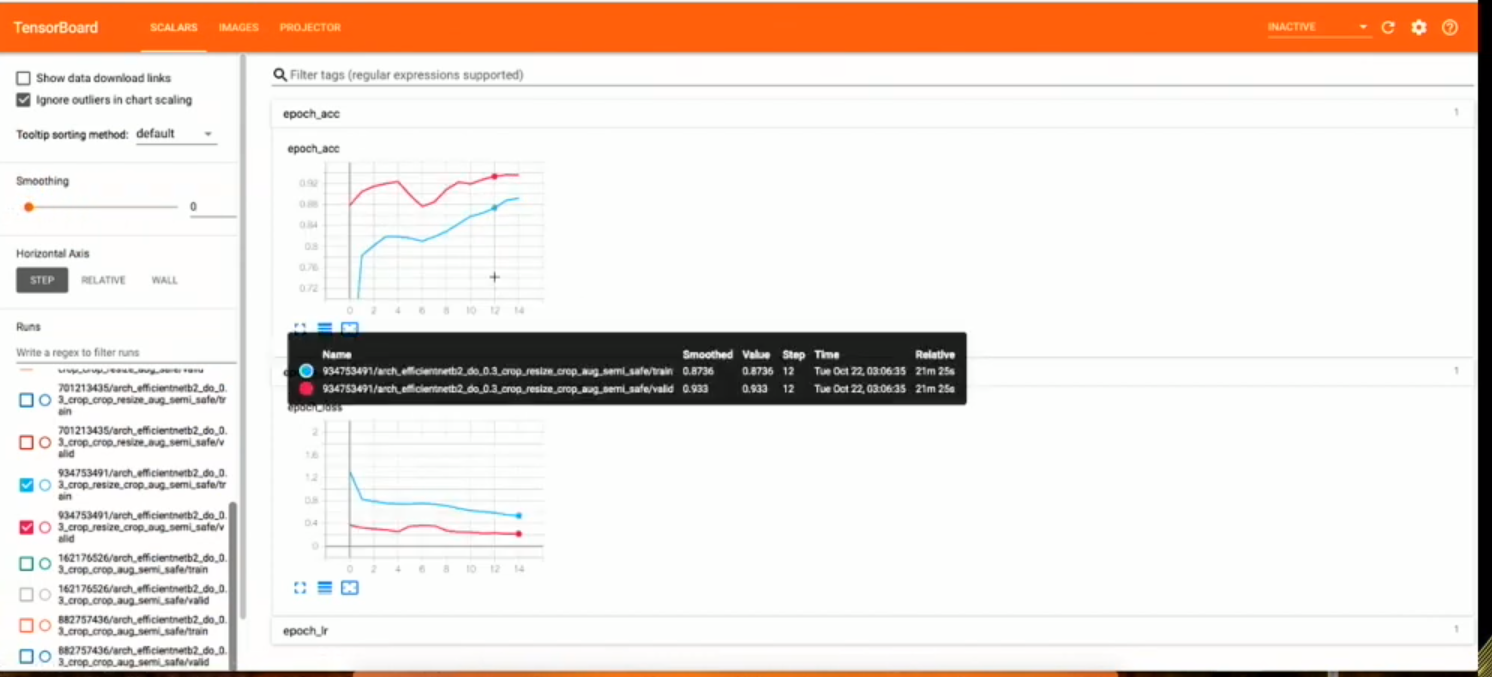
Tensorboard Integration
DriverlessAI will be shipped with a Tensorboard integration which will allow you to have tensorboard running along with DriverlessAI on a separate port.
Tensorboard allows you to monitor various aspects such as:
- Performance of multiple models/individual models.
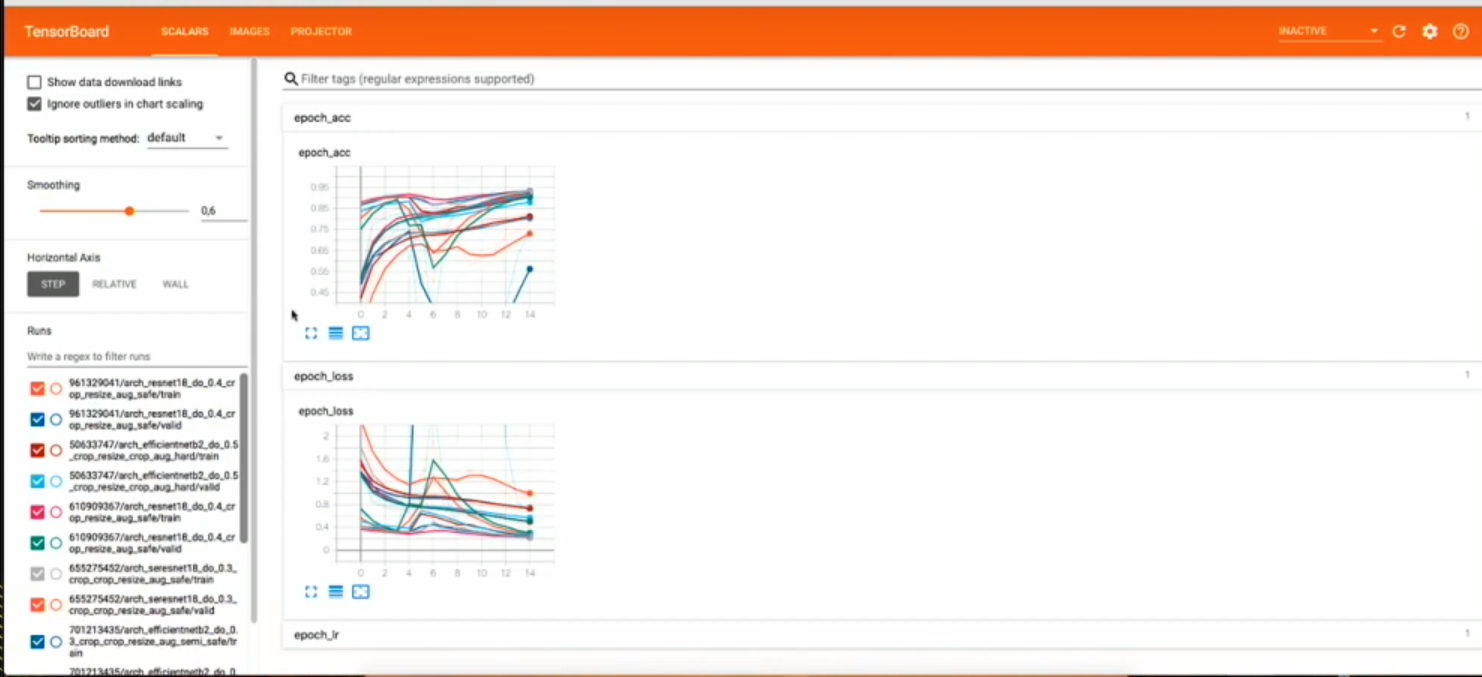
- Look at the loaded data
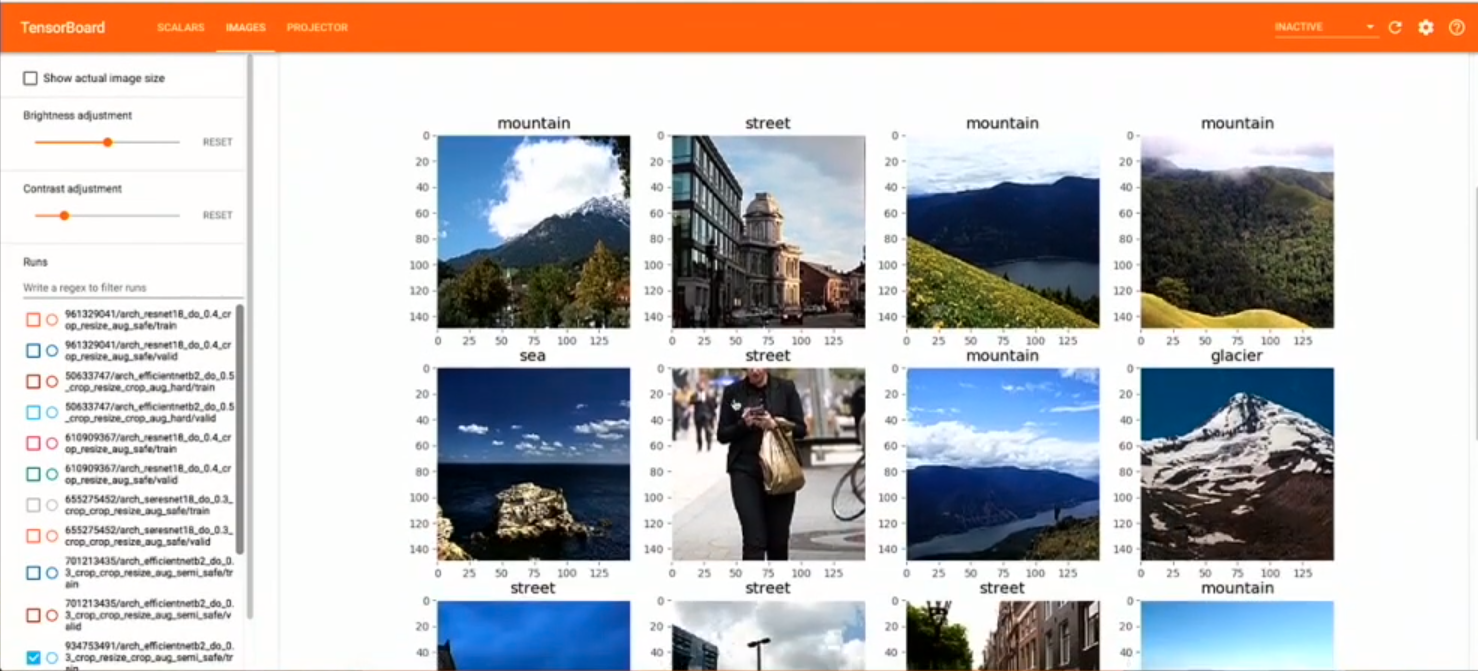
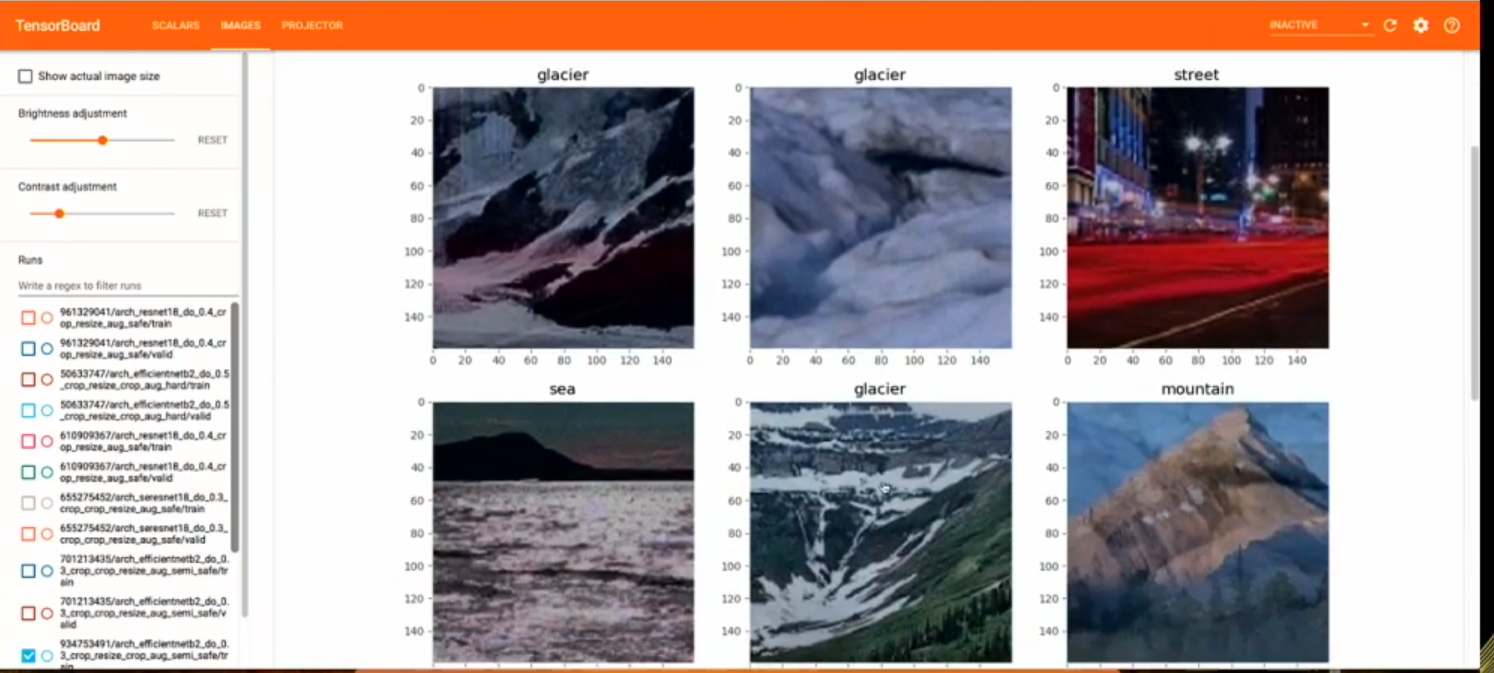
- Look at the augmented data (for checking augmentations)
- Dynamic Confusion Matrix (while training)

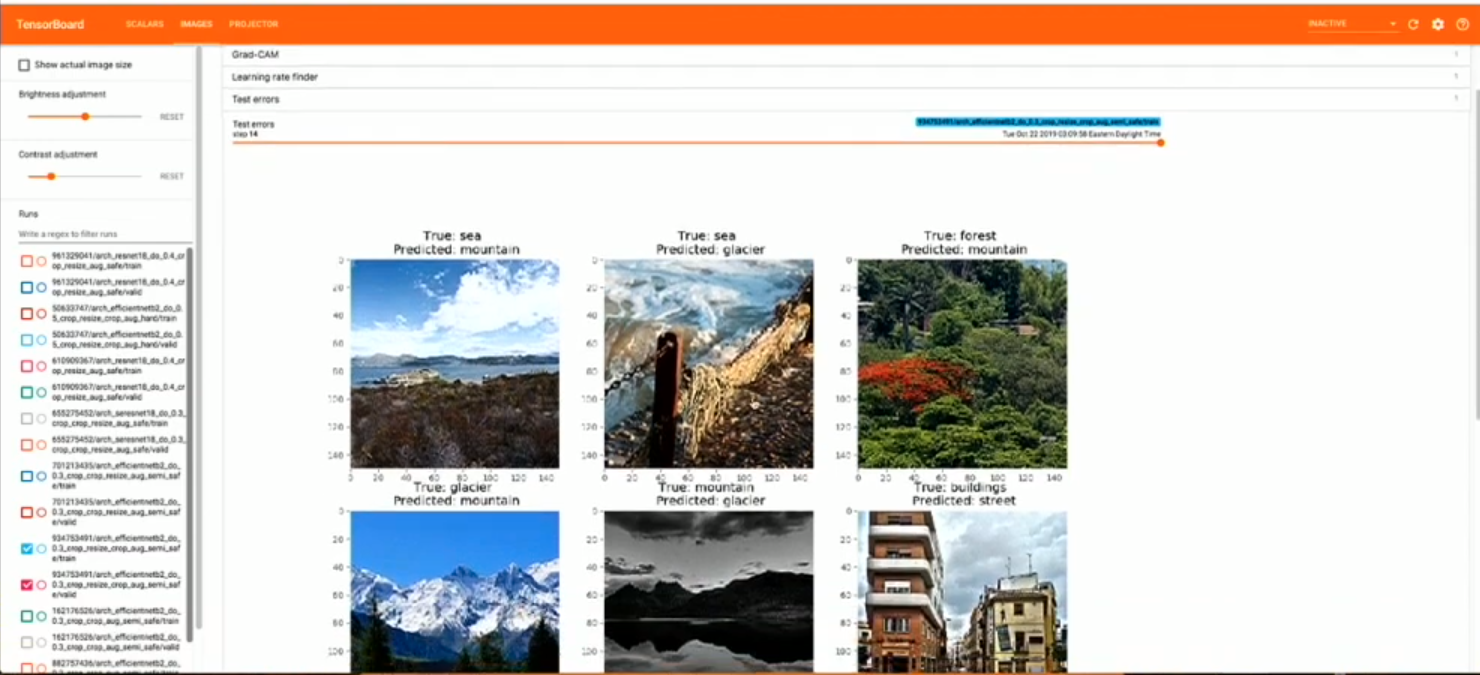
- Test Errors
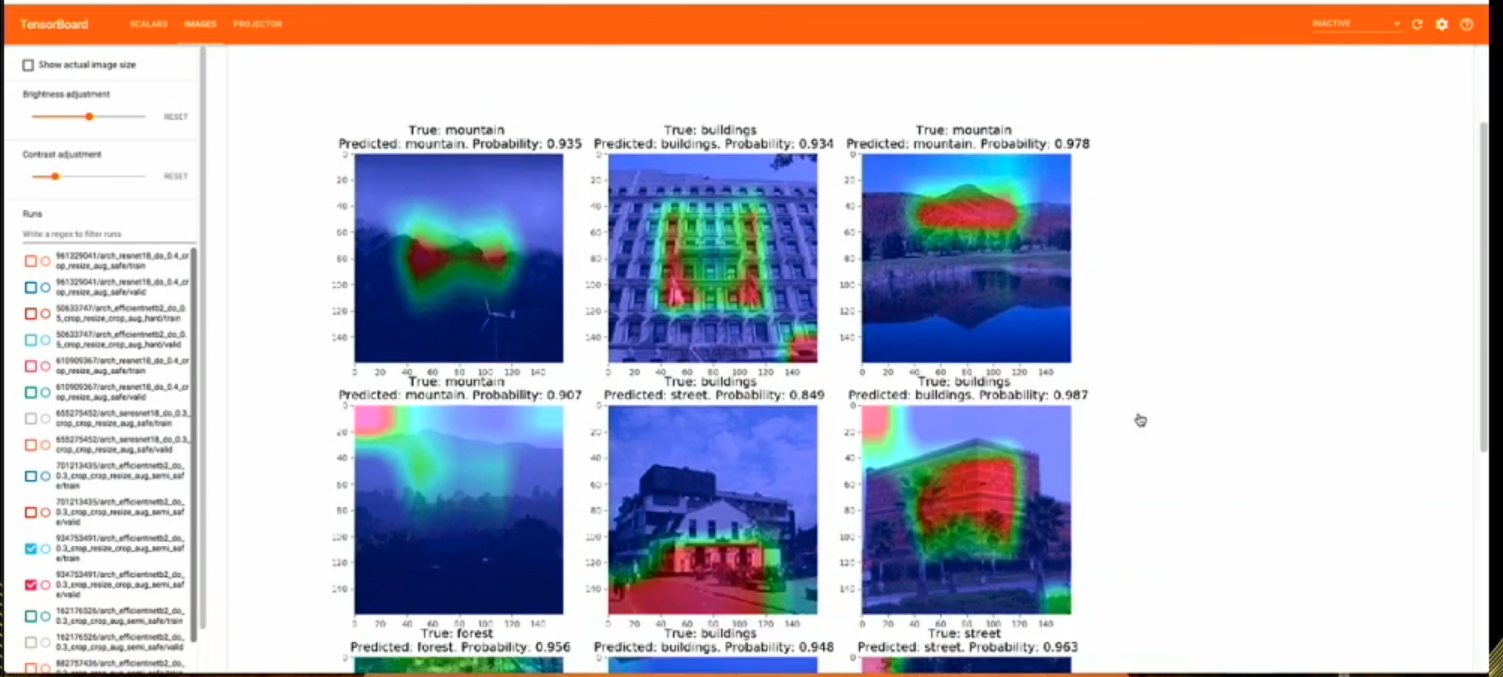
- Grad-CAM with heatmaps
- Create projections of the last layer embeddings to inspect model outputs.
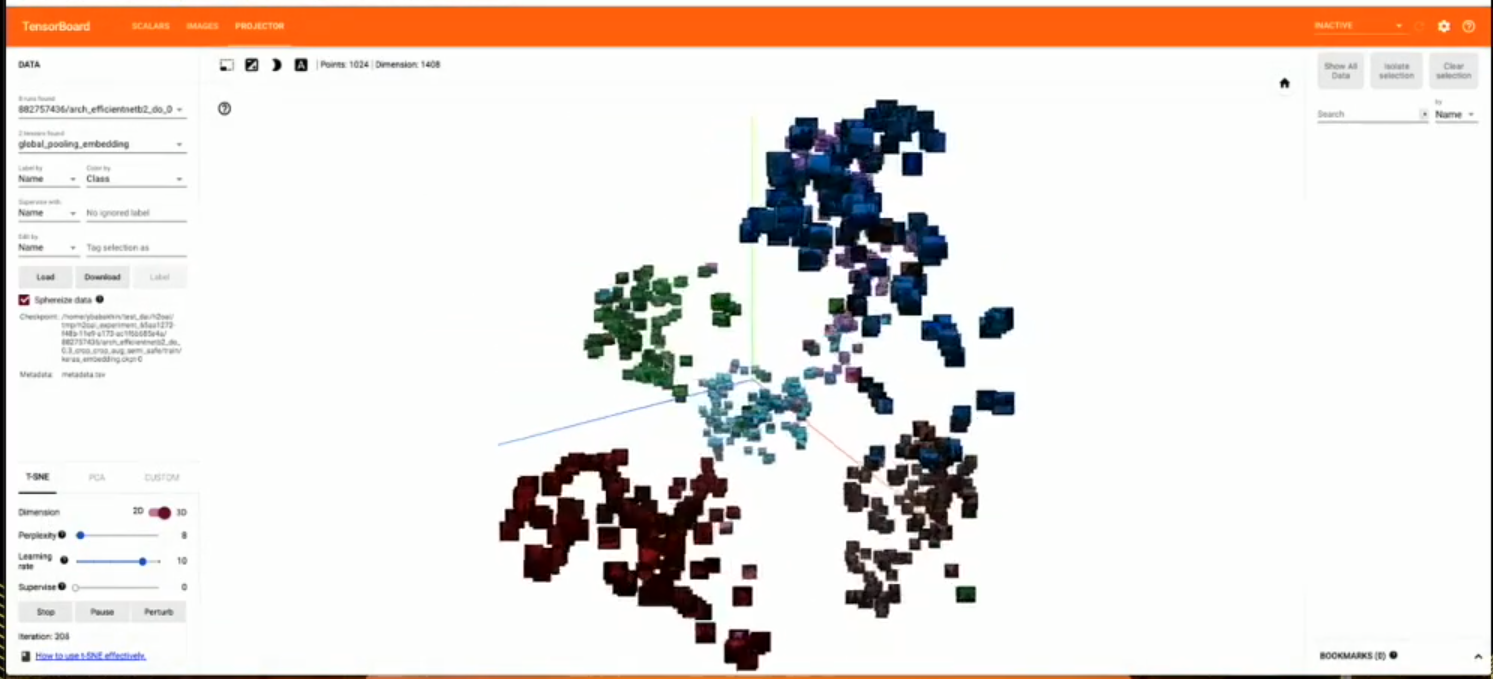
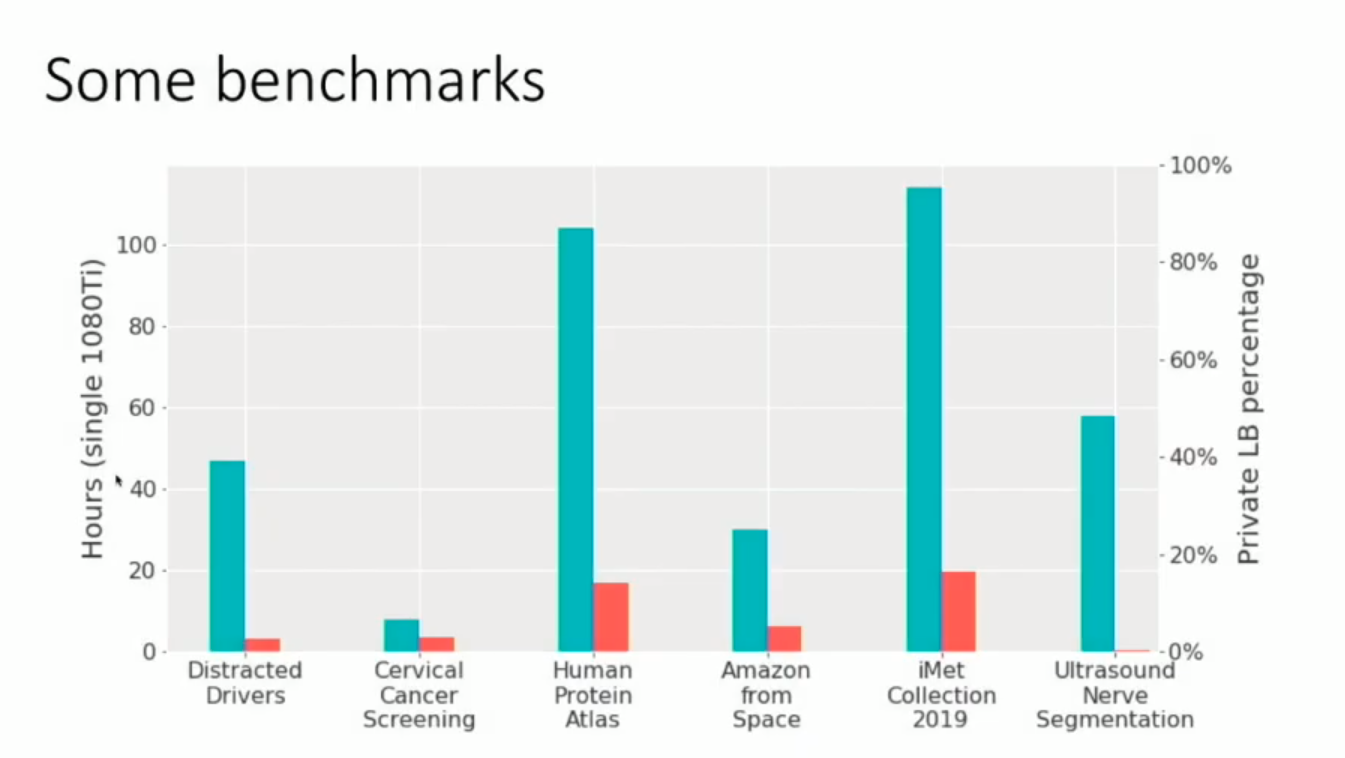
Benchmarks for Datasets
The graph below shows the training time on a single GPU Vs the Private LB% (Red).
As you can see the accuracies are great even given the short training hours (Short, in the context of image data)
What’s Next?
The remainder of the other tasks would be next on the radar along with moving the Computer Vision ideas into the product.
I’d recommend checking out the website for the latest updates, for when the product comes out as well.
If you’d like to check out interviews with Top Practitioners, Researchers and Kagglers about their Journey. Check out the Chai Time Data Science Podcast. Available both as audio and video.







