







Boosting LLMs to New Heights with Retrieval Augmented Generation

Businesses today can make leaps and bounds to revolutionize the way things are done with the use of Large Language Models (LLMs). LLMs are widely used by businesses today to automate certain tasks and create internal or customer-facing chatbots that boost efficiency.
Challenges with dynamic adaption of LLMs
As with any new hyped-up thing that dropped to the market fast, there are a few challenges with traditional, pre-trained LLMs that do not have retrieval functionality. For example, think of a chatbot that has been trained on a massive amount of data in 2020 but if you ask it a simple question about what the weather is today in your area, or the ongoing score of a football game, it’s unable to give you a proper answer. You may have already come across this problem.
This kind of LLM simply does not know present data and is missing the relevant, timely context required to answer this question correctly. You are lucky if it admits to not knowing the answer but it may just hallucinate and give you an incorrect answer.
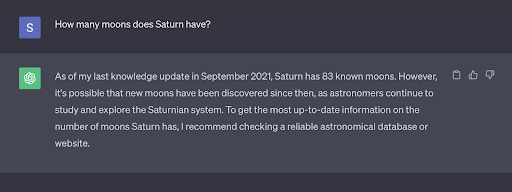
According to NASA, Saturn has 146 moons in orbit as of June 2023. Although this traditional LLM does point out that more moons may have been discovered since then, it is unable to give you an accurate, updated answer.
Which brings us to some of the core challenges we face with LLMs:
- It may not have a proper source or be able to cite one
- It can get outdated easily
- It can struggle to answer complex or challenging questions and may end up hallucinating answers
This is where Retrieval Augmented Generation (RAG) comes in. In the most basic of terms, Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge.
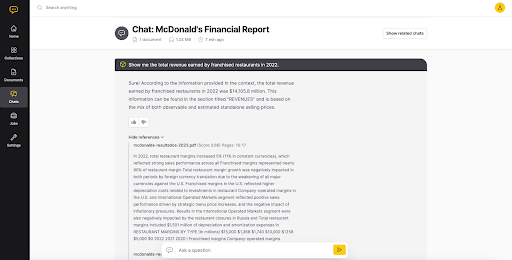
For instance, in the example below, the app draws on McDonald’s annual reports to answer the question of how much total revenue was earned by franchised McDonald’s outlets in the year 2022.
Achieving business agility using RAG
RAG-equipped chatbots absorb their information from a variety of sources, including databases, documents, and the internet, to provide accurate and contextually relevant responses. This is particularly useful when users have complex or multi-step queries. Using a RAG system contributes significantly towards making the business more agile, especially if the company has a customer-facing chatbot.
Here are a few examples of how businesses are embracing RAG-based systems today:
- Financial services companies are using RAG to generate personalized financial advice and risk assessments.
- Healthcare companies are using RAG to generate personalized treatment plans and answer patient questions about their medical conditions.
- E-commerce companies are using RAG to generate personalized product recommendations.
- Customer support teams are using RAG to generate personalized customer support responses and answer customer questions more quickly and efficiently.
With RAG, the core challenges faced with outdated LLMs are mitigated by augmenting new data to the LLM to help it give more updated and context-aware responses. This is done in two ways:
- Training the model on new data by constantly searching the web
- Uploading documents to enhance the LLM module and give it more information to base its responses on
For example, consider a chatbot being used in a medical context. An LLM without RAG may struggle to provide a good answer to the question “A patient is calling in to dispute a hospital charge. What documents and evidence do they need to attach to their claim?”. A RAG-based system, however, would be able to retrieve some relevant information from internal data uploaded by the hospital. An LLM-powered system can also be prompted to not answer questions that are not contained within the trusted information.
H2O.ai’s generative AI tools are based on a RAG-centric approach and can be used to easily create internal chatbots that are context-aware, updated, and customized toward your business use cases.
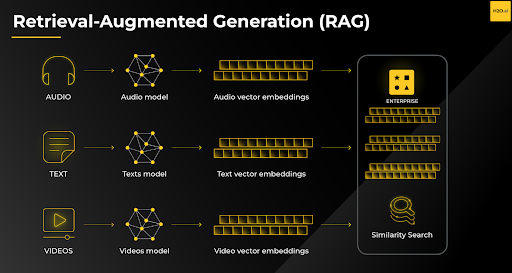
In addition to improving accuracy, RAG can also help to reduce bias in question answering systems. Pre-trained LLMs can be biased towards the data that is already baked into the model. For example, a pre-trained LLM that is trained on a dataset of news articles might be biased towards certain topics or perspectives.
RAG can help to reduce bias by retrieving information from a variety of sources, including sources that are known to be unbiased. This allows RAG-based systems to provide more objective and unbiased answers to questions.
Now, as a business, it is expensive to keep continuously fine-tuning a large language model to constantly include new data and become more context aware. You may even have internal data that you are cautious about exposing. Using a RAG approach, businesses can leverage their own internal data for generating precise, context-aware responses based on internal trusted information, and without incurring the substantial operational costs associated with continuously fine-tuning the model. Even with the fast-paced, constantly evolving nature of LLMs, the added benefit of the RAG approach is that companies just don’t need to worry about fine-tuning newer LLMs that come out. With this approach, you can simply upload your data at question/query time, making it instantly context-aware.
H2O.ai uses our own tools like h2oGPT, H2O LLM Studio, and H2O LLM Data Studio to achieve new levels of productivity within the company, and they can be used by other businesses to do the same. The most enticing benefit being that you can still hold ownership of your own internal data while creating a customized and updated chatbot to provide updated, specific, and context-aware responses to user prompts.







