






Entrenando Tu Propio LLM Sin Programación
Businesses today can make leaps and bounds to revolutionize the way things are done with the use of Large Language Models (LLMs). LLMs are widely used by businesses today to automate certain tasks and create internal or customer-facing chatbots that boost efficiency.
Challenges with dynamic adaption of LLMs
As with any new hyped-up thing that dropped to the market fast, there are a few challenges with traditional, pre-trained LLMs that do not have retrieval functionality. For example, think of a chatbot that has been trained on a massive amount of data in 2020 but if you ask it a simple question about what the weather is today in your area, or the ongoing score of a football game, it’s unable to give you a proper answer. You may have already come across this problem.
This kind of LLM simply does not know present data and is missing the relevant, timely context required to answer this question correctly. You are lucky if it admits to not knowing the answer but it may just hallucinate and give you an incorrect answer.
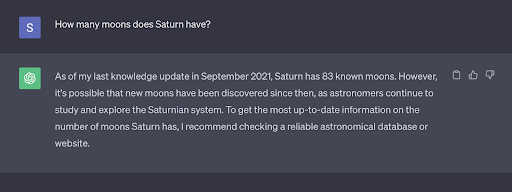
According to NASA, Saturn has 146 moons in orbit as of June 2023. Although this traditional LLM does point out that more moons may have been discovered since then, it is unable to give you an accurate, updated answer.
Which brings us to some of the core challenges we face with LLMs:
- It may not have a proper source or be able to cite one
- It can get outdated easily
- It can struggle to answer complex or challenging questions and may end up hallucinating answers
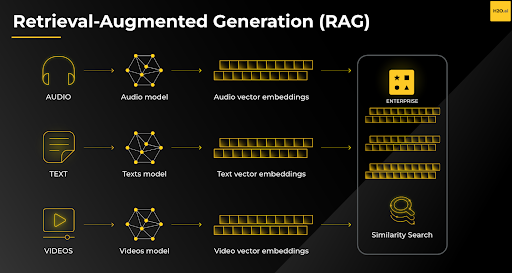
This is where Retrieval Augmented Generation (RAG) comes in. In the most basic of terms, Retrieval-augmented generation (RAG) is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge.
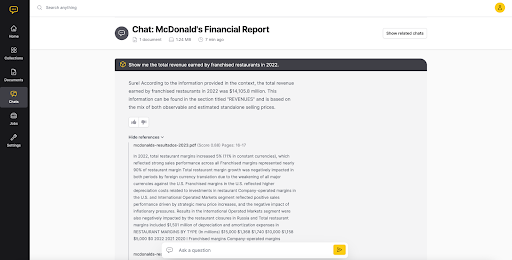
For instance, in the example below, the app draws on McDonald’s annual reports to answer the question of how much total revenue was earned by franchised McDonald’s outlets in the year 2022.
Achieving business agility using RAG
RAG-equipped chatbots absorb their information from a variety of sources, including databases, documents, and the internet, to provide accurate and contextually relevant responses. This is particularly useful when users have complex or multi-step queries. Using a RAG system contributes significantly towards making the business more agile, especially if the company has a customer-facing chatbot.
Here are a few examples of how businesses are embracing RAG-based systems today:
- Financial services companies are using RAG to generate personalized financial advice and risk assessments.
- Healthcare companies are using RAG to generate personalized treatment plans and answer patient questions about their medical conditions.
- E-commerce companies are using RAG to generate personalized product recommendations.
- Customer support teams are using RAG to generate personalized customer support responses and answer customer questions more quickly and efficiently.
With RAG, the core challenges faced with outdated LLMs are mitigated by augmenting new data to the LLM to help it give more updated and context-aware responses. This is done in two ways:
- Training the model on new data by constantly searching the web
- Uploading documents to enhance the LLM module and give it more information to base its responses on
For example, consider a chatbot being used in a medical context. An LLM without RAG may struggle to provide a good answer to the question “A patient is calling in to dispute a hospital charge. What documents and evidence do they need to attach to their claim?”. A RAG-based system, however, would be able to retrieve some relevant information from internal data uploaded by the hospital. An LLM-powered system can also be prompted to not answer questions that are not contained within the trusted information.
H2O.ai’s generative AI tools are based on a RAG-centric approach and can be used to easily create internal chatbots that are context-aware, updated, and customized toward your business use cases.
In addition to improving accuracy, RAG can also help to reduce bias in question answering systems. Pre-trained LLMs can be biased towards the data that is already baked into the model. For example, a pre-trained LLM that is trained on a dataset of news articles might be biased towards certain topics or perspectives.
RAG can help to reduce bias by retrieving information from a variety of sources, including sources that are known to be unbiased. This allows RAG-based systems to provide more objective and unbiased answers to questions.
Now, as a business, it is expensive to keep continuously fine-tuning a large language model to constantly include new data and become more context aware. You may even have internal data that you are cautious about exposing. Using a RAG approach, businesses can leverage their own internal data for generating precise, context-aware responses based on internal trusted information, and without incurring the substantial operational costs associated with continuously fine-tuning the model. Even with the fast-paced, constantly evolving nature of LLMs, the added benefit of the RAG approach is that companies just don’t need to worry about fine-tuning newer LLMs that come out. With this approach, you can simply upload your data at question/query time, making it instantly context-aware.
H2O.ai uses our own tools like h2oGPT, H2O LLM Studio, and H2O LLM Data Studio to achieve new levels of productivity within the company, and they can be used by other businesses to do the same. The most enticing benefit being that you can still hold ownership of your own internal data while creating a customized and updated chatbot to provide updated, specific, and context-aware responses to user prompts.
This blog was originally published in English here: https://www.analyticsvidhya.com/blog/2023/09/training-your-own-llm-without-coding/
Introducción
La Inteligencia Artificial Generativa, un campo fascinante que promete revolucionar cómo interactuamos con la tecnología y generamos contenido, ha causado sensación en el mundo. En este artículo, exploraremos el fascinante mundo de los Modelos grandes de lenguaje (LLMs, por sus siglas en inglés), sus componentes básicos, los desafíos planteados por los LLMs de código cerrado y la aparición de modelos de código abierto. También profundizaremos en el ecosistema de LLMs de H2O, que incluye herramientas y marcos como h2oGPT y LLM DataStudio, que permiten a las personas entrenar LLMs sin necesidad de habilidades extensas en programación.
Objetivos de Aprendizaje:
Comprender el concepto y las aplicaciones de la Inteligencia Artificial Generativa con Modelos grandes de lenguaje (LLMs).
Reconocer los desafíos de los LLMs de código cerrado y las ventajas de los modelos de código abierto.
Explorar el ecosistema de LLMs de H2O para el entrenamiento de IA sin habilidades extensas en programación.
Componentes Básicos de los LLMs: Modelos Funcionales y Ajuste Fino
Antes de adentrarnos en los detalles de los LLMs, retrocedamos un poco y comprendamos el concepto de la Inteligencia Artificial Generativa. Mientras que la IA predictiva ha sido la norma, la IA generativa cambia el enfoque, centrándose en la predicción basada en patrones de datos históricos. Equipa a las máquinas con la capacidad de crear nueva información a partir de conjuntos de datos existentes.
Imagina un modelo de aprendizaje automático capaz de predecir y generar texto, resumir contenido, clasificar información y más, todo desde un solo modelo. Aquí es donde entran en juego los Modelos grandes de lenguaje (LLMs).
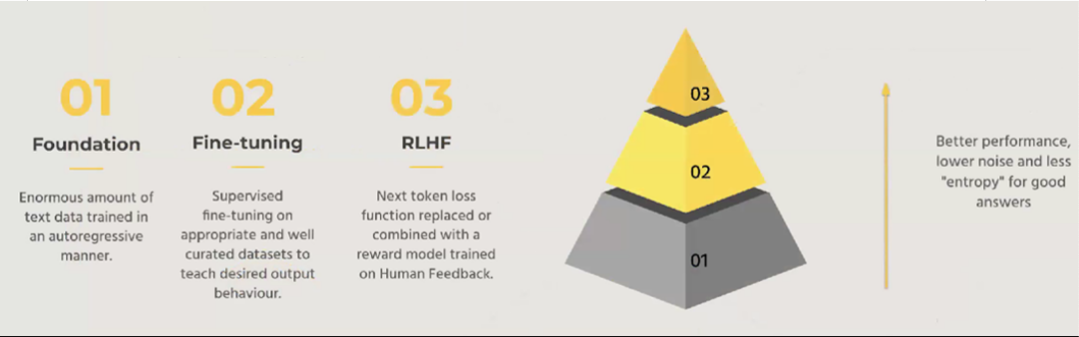
Los LLMs siguen un proceso de varios pasos, comenzando con un modelo fundamental. Este modelo requiere un conjunto de datos extenso para entrenar, a menudo en el orden de terabytes o petabytes de datos. Estos Modelos Funcionales aprenden al predecir la siguiente palabra en una secuencia para entender los patrones dentro de los datos.
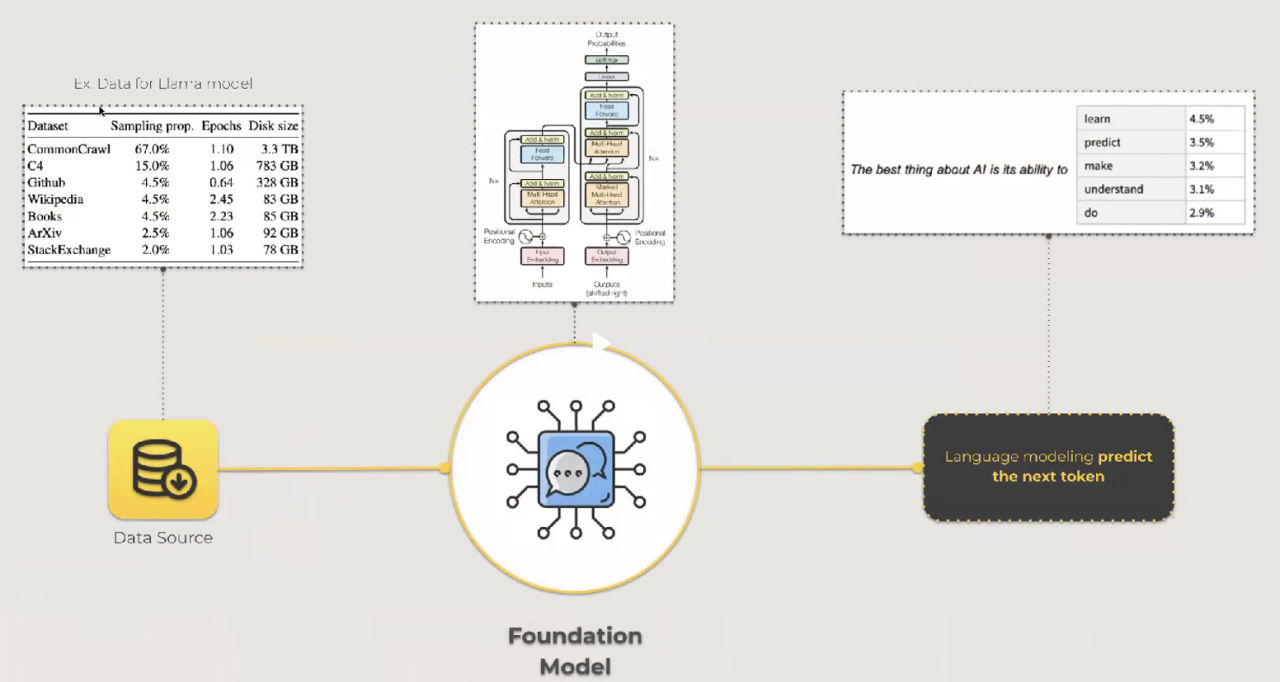
Una vez que se establece el modelo fundamental, el siguiente paso es el ajuste fino. Durante esta fase, se emplea el ajuste supervisado en conjuntos de datos seleccionados para moldear el comportamiento deseado del modelo. Esto puede implicar entrenar al modelo para realizar tareas específicas como selección de opciones múltiples, clasificación y más.
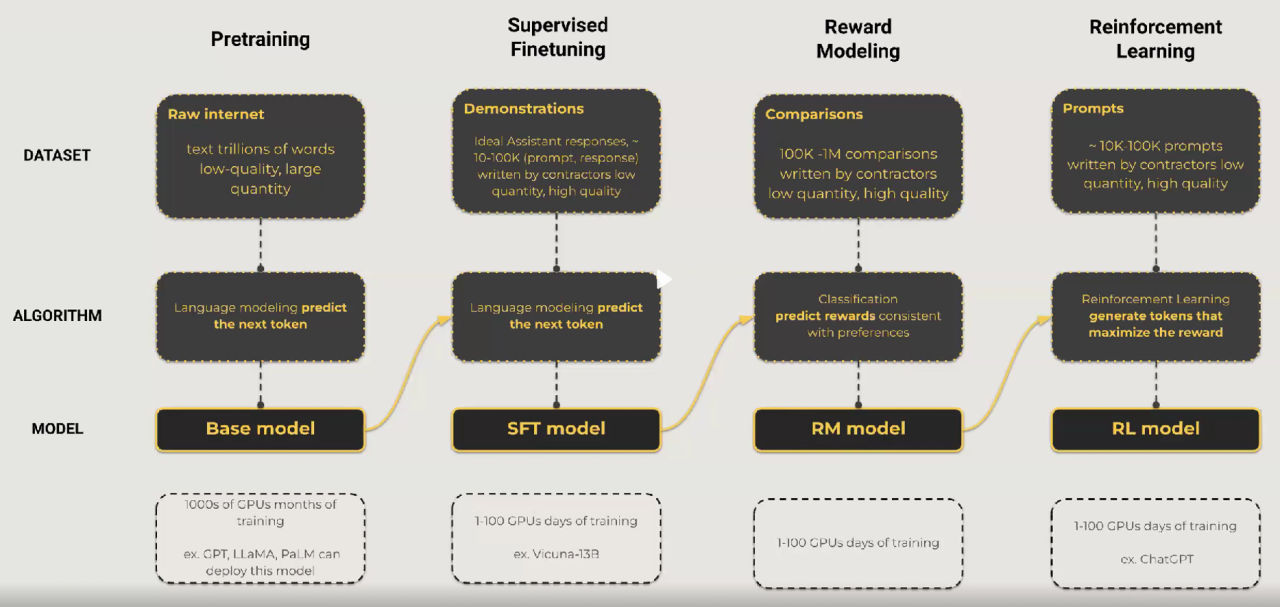
El tercer paso, el aprendizaje por refuerzo con retroalimentación humana, perfecciona aún más el rendimiento del modelo. Utilizando modelos de recompensa basados en la retroalimentación humana, el modelo ajusta sus predicciones para alinearse más estrechamente con las preferencias humanas. Esto ayuda a reducir el ruido y aumentar la calidad de las respuestas.
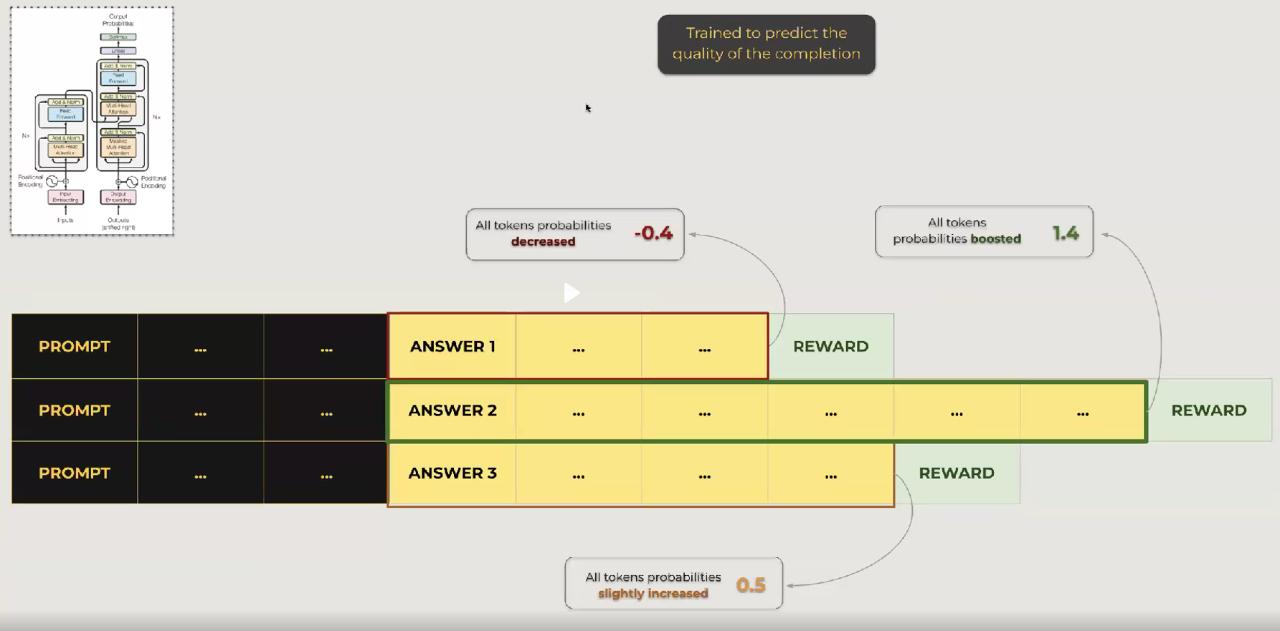
Cada paso en este proceso mejora el rendimiento del modelo y reduce la incertidumbre. Es importante destacar que la elección del modelo fundamental, del conjunto de datos y de las estrategias de ajuste fino depende del caso de uso específico.
Desafíos de los LLMs de Código Cerrado y el Auge de los Modelos de Código Abierto
Los LLMs de código cerrado, como ChatGPT, Google Bard y otros, han demostrado su efectividad. Sin embargo, presentan sus propios desafíos. Estos incluyen preocupaciones sobre la privacidad de los datos, limitada personalización y control, altos costos operativos y ocasional falta de disponibilidad.
Las organizaciones e investigadores han reconocido la necesidad de LLMs más accesibles y personalizables. En respuesta, han comenzado a desarrollar modelos de código abierto. Estos modelos son rentables, flexibles y pueden adaptarse a requisitos específicos. También eliminan preocupaciones sobre el envío de datos sensibles a servidores externos.
Los LLMs de código abierto capacitan a los usuarios para entrenar sus propios modelos y acceder a los detalles internos de los algoritmos. Este ecosistema abierto proporciona más control y transparencia, lo que lo convierte en una solución prometedora para diversas aplicaciones.
Ecosistema de LLMs de H2O: Herramientas y Marcos para Entrenar LLMs Sin Programación
H2O, un actor destacado en el mundo del aprendizaje automático, ha desarrollado un sólido ecosistema para LLMs. Sus herramientas y marcos facilitan el entrenamiento de LLMs sin la necesidad de una amplia experiencia en programación. Vamos a explorar algunos de estos componentes.

h2oGPT
h2oGPT es un LLM ajustado finamente que se puede entrenar con tus propios datos. ¿La mejor parte? Es completamente gratuito de usar. Con h2oGPT, puedes experimentar con LLMs e incluso aplicarlos comercialmente. Este modelo de código abierto te permite explorar las capacidades de los LLMs sin barreras financieras.
Herramientas de Implementación
H2O.ai ofrece una variedad de herramientas para implementar tus LLMs, asegurando que tus modelos puedan ponerse en acción de manera efectiva y eficiente. Ya sea que estés construyendo chatbots, asistentes de ciencia de datos o herramientas de generación de contenido, estas opciones de implementación proporcionan flexibilidad.
Marcos de Entrenamiento de LLMs
Entrenar un LLM puede ser complejo, pero los marcos de entrenamiento de LLMs de H2O simplifican la tarea. Con herramientas como Colossal y DeepSpeed, puedes entrenar tus modelos de código abierto de manera efectiva. Estos marcos admiten varios Modelos Funcionales y te permiten ajustarlos finamente para tareas específicas.
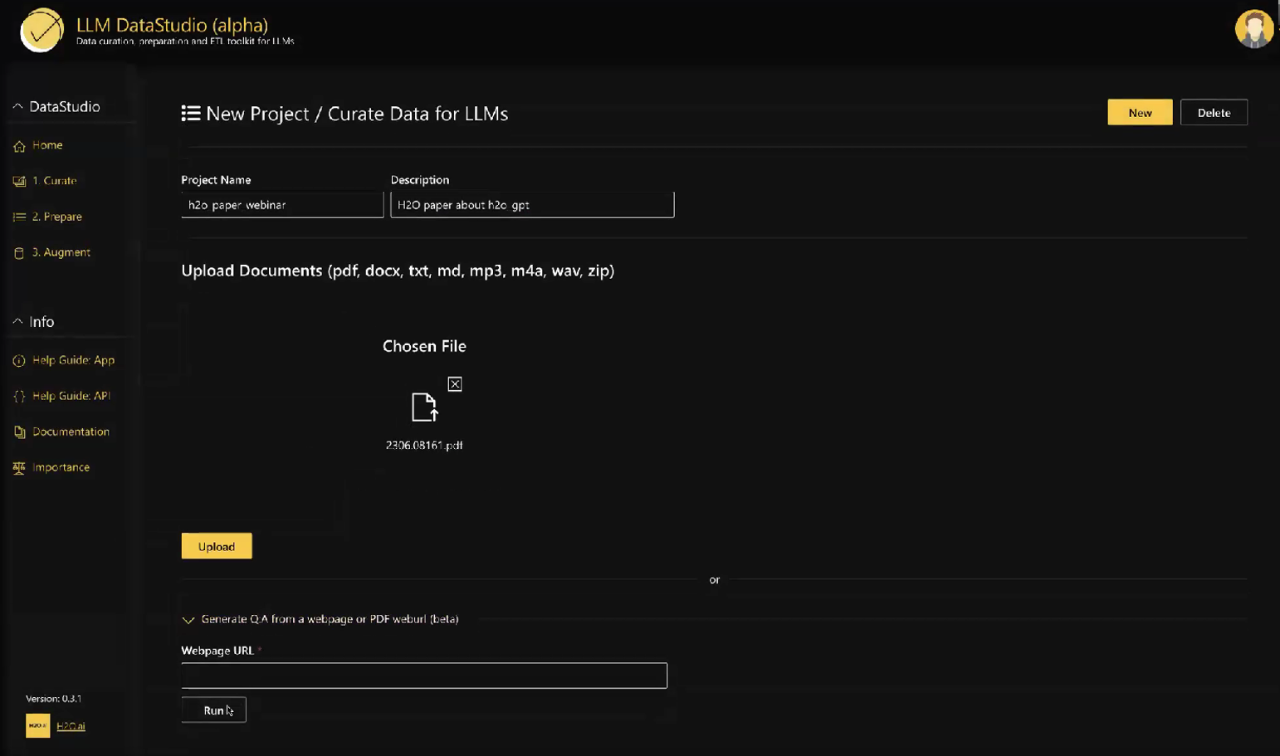
Demo: Preparación de Datos y Ajuste Fino de LLMs con LLM DataStudio de H2O
Ahora, sumerjámonos en una demostración de cómo puedes usar el ecosistema de LLMs de H2O, centrándonos específicamente en LLM DataStudio. Esta solución sin programación te permite preparar datos para ajustar finamente tus modelos de LLM. Ya sea que trabajes con texto, PDF u otros formatos de datos, LLM DataStudio simplifica el proceso de preparación de datos, haciéndolo accesible para muchos usuarios.
En esta demostración, recorreremos los pasos para preparar datos y ajustar finamente LLMs, destacando la naturaleza fácil de usar de estas herramientas. Al final, tendrás una comprensión más clara de cómo aprovechar el ecosistema de H2O para tus propios proyectos de LLM.
El mundo de los LLMs y la IA generativa está evolucionando rápidamente, y las contribuciones de H2O a este campo lo hacen más accesible que nunca. Con modelos de código abierto, herramientas de implementación y marcos amigables para el usuario, puedes aprovechar el poder de los LLMs para una amplia gama de aplicaciones sin necesidad de habilidades extensas en programación. El futuro de la generación de contenido y la interacción impulsada por la IA ha llegado, y es emocionante formar parte de este viaje transformador.
Introducción a h2oGPT: una Interfaz de Chat Multi-Modelo
En el mundo de la inteligencia artificial y el procesamiento del lenguaje natural, ha habido una evolución notable en las capacidades de los modelos de lenguaje. La llegada de GPT-3 y modelos similares ha allanado el camino para nuevas posibilidades en la comprensión y generación de texto similar al humano. Sin embargo, el viaje no termina allí. El mundo de los modelos de lenguaje sigue expandiéndose y mejorando, y un desarrollo emocionante es h2oGPT. Esta interfaz de chat multi-modelo lleva el concepto de los Modelos grandes de lenguaje al siguiente nivel.
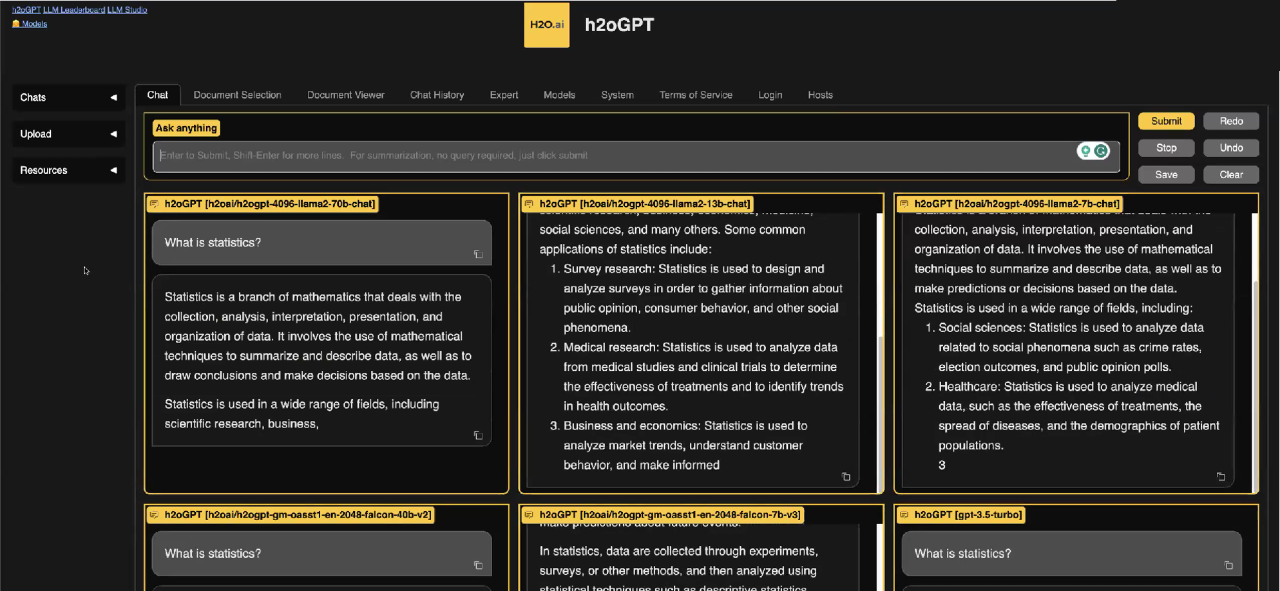
h2oGPT es como un descendiente de GPT, pero con una diferencia. En lugar de depender de un solo modelo de lenguaje masivo, h2oGPT aprovecha el poder de varios modelos de lenguaje que funcionan simultáneamente. Este enfoque proporciona a los usuarios una variedad de respuestas e información. Cuando haces una pregunta, h2oGPT envía esa consulta a varios modelos de lenguaje, incluyendo Llama 2, GPT-NeoX, Falcon 40 B y otros. Cada uno de estos modelos responde con su propia respuesta única. Esta diversidad te permite comparar y contrastar respuestas de diferentes modelos para encontrar la que mejor se adapte a tus necesidades.
Por ejemplo, si haces una pregunta como “¿Qué es la estadística?”, recibirás respuestas de varios LLMs dentro de h2oGPT. Estas respuestas diferentes pueden ofrecer perspectivas valiosas sobre el mismo tema. Esta característica poderosa es increíblemente útil y completamente gratuita de usar.
Simplificando la Curación de Datos con LLM DataStudio
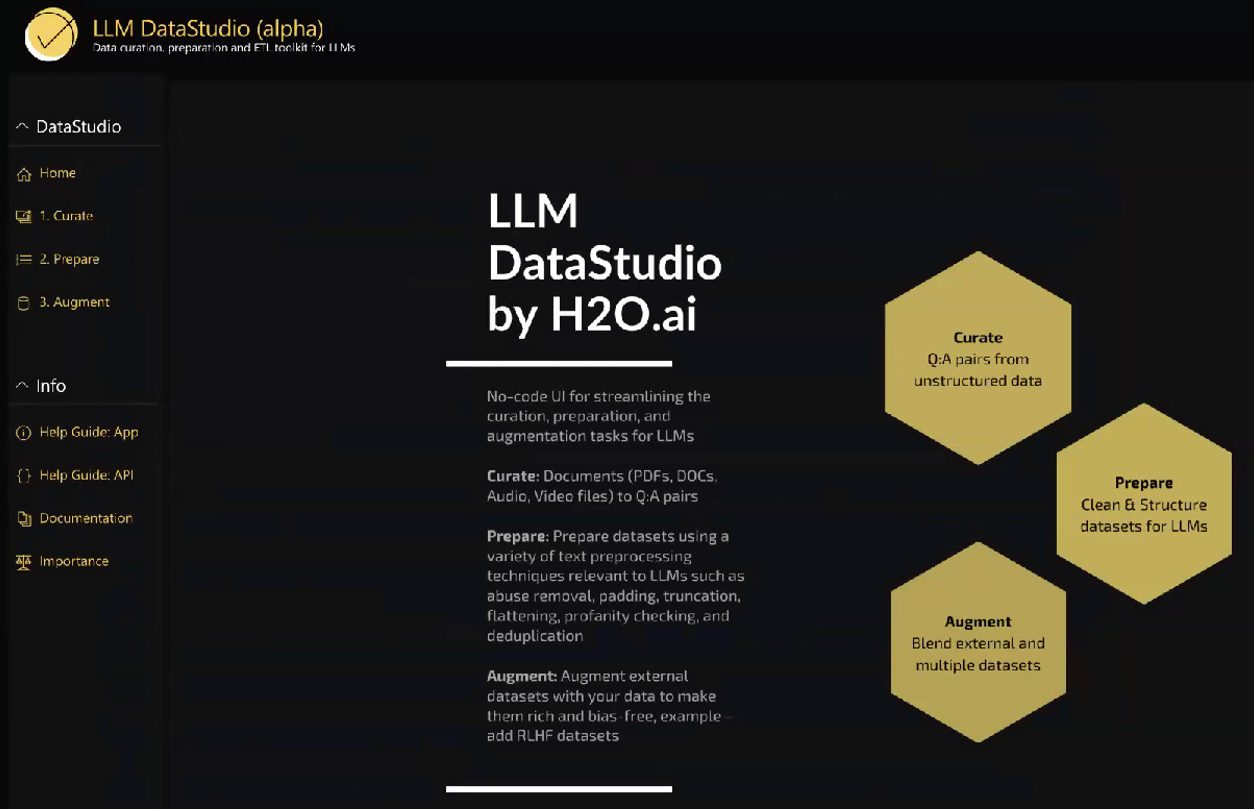
Para ajustar finamente un modelo de lenguaje grande de manera efectiva, necesitas datos curados de alta calidad. Tradicionalmente, esto implicaba contratar personas para crear promps manualmente, recopilar comparaciones y generar respuestas, lo que podía ser un proceso laborioso y que llevaba mucho tiempo. Sin embargo, h2oGPT introduce una solución innovadora llamada LLM DataStudio que simplifica este proceso de curación de datos.
LLM DataStudio te permite crear conjuntos de datos curados a partir de datos no estructurados de manera fácil. Imagina que deseas entrenar o ajustar finamente un LLM para comprender un documento específico, como un artículo de H2O sobre h2oGPT. Normalmente, tendrías que leer el artículo y generar preguntas y respuestas manualmente. Este proceso puede ser arduo, especialmente con una gran cantidad de datos.
Pero con LLM DataStudio, el proceso se vuelve significativamente más sencillo. Puedes cargar varios tipos de datos, como PDF, documentos de Word, páginas web, datos de audio y más. El sistema analizará automáticamente esta información, extraerá fragmentos relevantes de texto y creará pares de preguntas y respuestas. Esto significa que puedes crear conjuntos de datos de alta calidad sin necesidad de entrada manual de datos.
Limpieza y Preparación de Conjuntos de Datos Sin Programación
La limpieza y preparación de conjuntos de datos son pasos críticos en el entrenamiento de un modelo de lenguaje, y LLM DataStudio simplifica esta tarea sin necesidad de habilidades de programación. La plataforma ofrece una variedad de opciones para limpiar tus datos, como eliminar espacios en blanco, URLs, lenguaje inapropiado o controlar la longitud de la respuesta. Incluso puedes verificar la calidad de los promps y las respuestas. Todo esto se logra a través de una interfaz fácil de usar, por lo que puedes limpiar tus datos de manera efectiva sin escribir una sola línea de código.
Además, puedes ampliar tus conjuntos de datos con sistemas conversacionales adicionales, preguntas y respuestas, brindando a tu LLM aún más contexto. Una vez que tu conjunto de datos esté listo, puedes descargarlo en formato JSON o CSV para entrenar tu modelo de lenguaje personalizado.
Entrenando Tu LLM Personalizado con H2O LLM Studio
Ahora que tienes tu conjunto de datos curado, es hora de entrenar tu modelo de lenguaje personalizado, y H2O LLM Studio es la herramienta que te ayudará a hacerlo. Esta plataforma está diseñada para entrenar modelos de lenguaje sin necesidad de habilidades de programación.
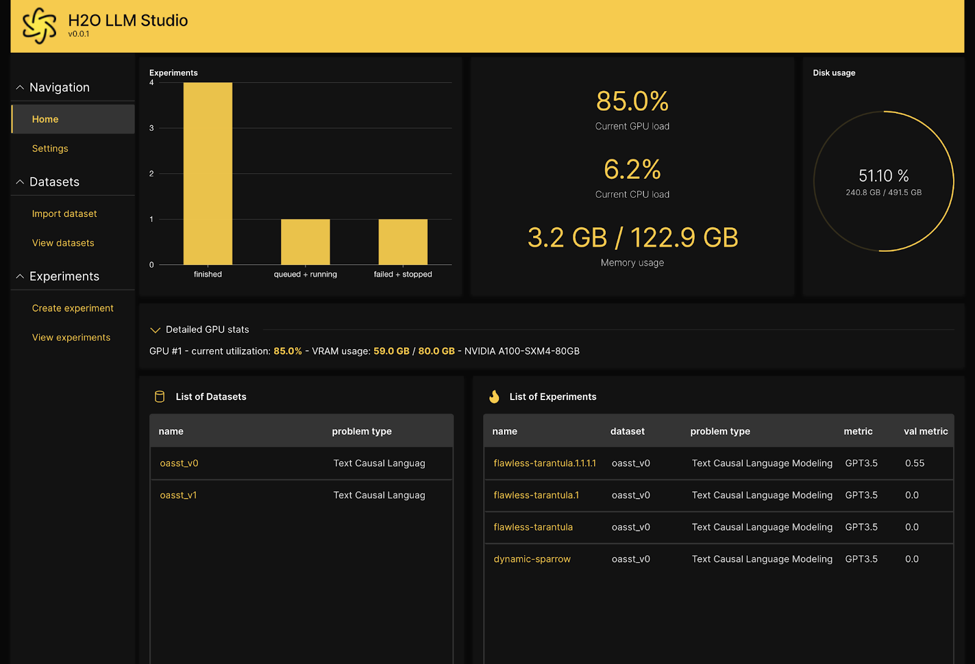
El proceso comienza importando tu conjunto de datos en LLM Studio. Especificas qué columnas contienen los promps y las respuestas, y la plataforma te proporciona una visión general de tu conjunto de datos. Luego, creas un experimento, le das un nombre y seleccionas un modelo base. La elección del modelo base depende de tu caso de uso específico, ya que diferentes modelos destacan en diversas aplicaciones. Puedes seleccionar entre varias opciones, cada una con diferentes números de parámetros para adaptarse a tus necesidades.

Puedes configurar parámetros como el número de épocas, la aproximación de bajo rango, la probabilidad de tarea, la temperatura y más durante la configuración del experimento. Si no estás familiarizado con estas configuraciones, no te preocupes; LLM Studio ofrece mejores prácticas para guiarte. Además, puedes usar GPT de OpenAI como métrica para evaluar el rendimiento de tu modelo, aunque también están disponibles métricas alternativas como BLEU si prefieres no utilizar APIs externas.
Una vez que tu experimento esté configurado, puedes comenzar el proceso de entrenamiento. LLM Studio proporciona registros y gráficos para ayudarte a supervisar el progreso de tu modelo. Después de un entrenamiento exitoso, puedes iniciar una sesión de chat con tu LLM personalizado, probar sus respuestas e incluso descargar el modelo para su uso futuro.
Conclusión
En este cautivador viaje por el mundo de los Modelos grandes de lenguaje (LLMs) y la Inteligencia Artificial generativa, hemos descubierto el potencial transformador de estos modelos. La aparición de LLMs de código abierto, ejemplificada por el ecosistema de H2O, ha hecho que esta tecnología sea más accesible que nunca. Estamos presenciando una revolución en la generación de contenido impulsada por la IA y la interacción con herramientas amigables para el usuario, marcos flexibles y modelos diversos como h2oGPT.
h2oGPT, LLM DataStudio y H2O LLM Studio representan un conjunto poderoso de herramientas que capacitan a los usuarios para trabajar con Modelos grandes de lenguaje, curar datos sin esfuerzo y entrenar modelos personalizados sin la necesidad de habilidades de programación. Esta suite de recursos integral simplifica el proceso y lo hace accesible a una audiencia más amplia, inaugurando una nueva era de comprensión y generación de lenguaje natural impulsada por la IA. Ya seas un profesional experimentado en IA o estés comenzando, estas herramientas te permiten explorar el fascinante mundo de los modelos de lenguaje y sus aplicaciones.
Principales Conclusiones:
- La Inteligencia Artificial Generativa, impulsada por los LLMs, permite que las máquinas generen contenido en lugar de simplemente predecir resultados basados en patrones de datos históricos, abriendo posibilidades más allá de los modelos predictivos tradicionales.
- Los LLMs de código abierto como h2oGPT ofrecen a los usuarios soluciones rentables, personalizables y transparentes, eliminando preocupaciones sobre privacidad de datos y control.
- El ecosistema de H2O ofrece una variedad de herramientas y marcos, como LLM DataStudio y H2O LLM Studio, que se presentan como una solución sin programación para el entrenamiento de LLMs.
Preguntas Frecuentes
P1. ¿Qué son los LLMs y en qué se diferencian de la IA predictiva tradicional?
R1. Los LLMs, o Modelos grandes de lenguaje, permiten que las máquinas generen contenido en lugar de simplemente predecir resultados basados en patrones de datos históricos. Pueden crear texto, resumir información, clasificar datos, entre otras cosas, ampliando las capacidades de la IA.
P2. ¿Por qué los LLMs de código abierto como h2oGPT están ganando popularidad?
R2. Los LLMs de código abierto están ganando tracción debido a su rentabilidad, capacidad de personalización y transparencia. Los usuarios pueden adaptar estos modelos a sus necesidades específicas, eliminando preocupaciones sobre privacidad de datos y control.
P3. ¿Cómo puedo entrenar LLMs sin habilidades extensas en programación?
R3. El ecosistema de H2O ofrece herramientas y marcos fáciles de usar, como LLM DataStudio y H2O LLM Studio, que simplifican el proceso de entrenamiento. Estas plataformas te guían a través de la curación de datos, la configuración del modelo y el entrenamiento, haciendo que la IA sea más accesible para una audiencia más amplia.







