




H2O LLM DataStudio Part II: Convert Documents to QA Pairs for fine tuning of LLMs

Convert unstructured datasets to Question-answer pairs required for LLM fine-tuning and other downstream tasks with H2O LLM Data Studio Curate.
Every organization needs to own its GPT as simply as it needs to bring its data, algorithms, and models (read more here). A common problem we see in organizations is that they want to be able to finetune and personalize their own company LLM but don’t have many structured datasets available. However, all companies have a wealth of unstructured datasets that could be utilized to create these personalized LLMs. This is where LLM DataStudio’s new capability Curatecan help.
In part one of the H2O LLM DataStudio blogs we introduced streamlined no-code data preparation pipelines for LLMs, LLM DataStudio. LLM DataStudio is an end-to-end data preparation tool that encompasses Curate, Prepare, and Augment.
- Curate: Documents (PDFs, DOCs, Audio & Video files) to Q:A pairs.
- Prepare: Prepare datasets using a variety of text preprocessing techniques relevant to LLMs such as profanity and toxicity removal, padding, truncation, flattening & deduplication.
- Augment: Augment external datasets with your data to make them rich and bias-free, for example adding RLHF datasets.
Introducing LLM DataStudio Curate – converting documents to QA pairs for LLM fine-tuning and downstream tasks!
H2O LLM DataStudio’s new Curate component is a no-code capability to build structured LLM datasets from unstructured data in any organization. Think policy or product documentation, podcasts, zoom meeting recordings, and internal news articles, their potential to be utilized with AI has been unlocked with Curate. Utilizing smart chunking, intelligent prompt engineering, and H2OGPTs Large Language Model, Curate automatically generates diverse question-answer pairs or context summarization pairs to translate the unstructured datasets into structured data for LLM Fine Tuning with H2O LLM Studio or any other downstream tasks.
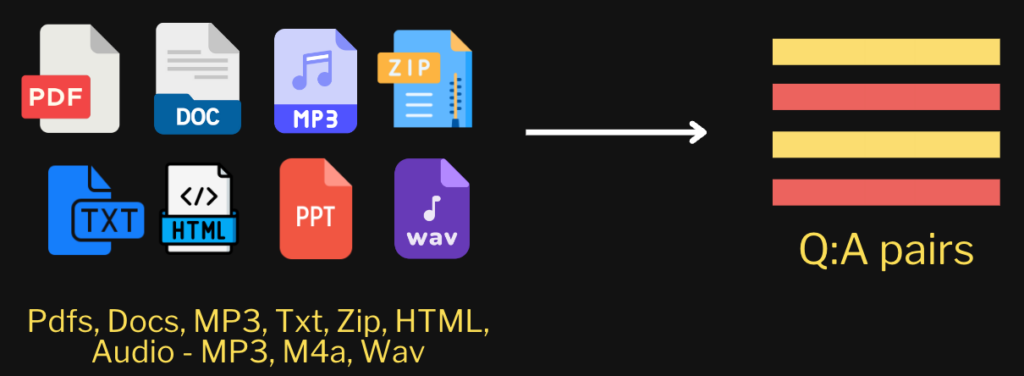
Input Document: Product Brief

Output: Generated Question-Answer Pairs
Key Functionalities
1. Variety of Data Types
- Documents (pdf, docx, md, txt)
- Audio (.wav, m4a, mp3)
- Markdowns, HTML
- Collection of all of the above (.zip collections)
- Web URLs and PDFs
2. LLM Based on QA pair generation
- Utilizing H2OGPT large open source LLM to use the documents as a reference to formulate and format QA pair generation. This capability handles the full end to end pipeline from breaking your document into pieces (chunking), using intelligent prompting techniques and ensuring consistent output formats.
3. Fast QA Mode
- Configure what proportion of input documents to use for QA generation.
- Identify sections (chunks) of input documents that are not only diverse from each other but also content-rich to ensure refined but diverse QA generation.
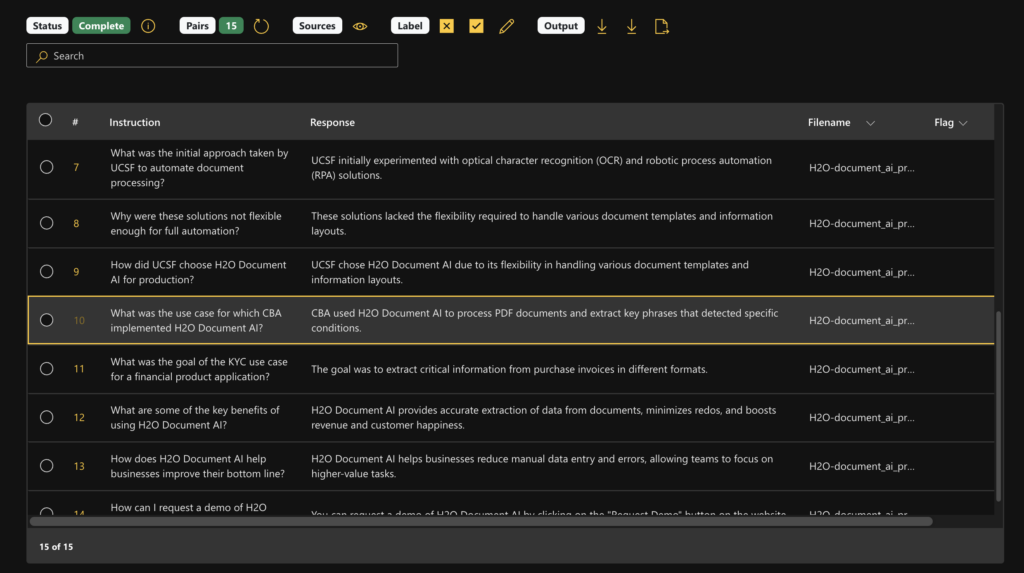
4. View, customize the output
- Reference Check: Explore the text chunks from the original document to see where the question and answer pair was generated.
- Flag: Flag whether a row is relevant or irrelevant. These rows can then be filtered out in Prepare.
- Edit: Customise and update any QA pair.
- Download Dataset: Download the datasets as either JSON or csv.
- Send to Prepare: Easily send the curated dataset to a Prepare project. This easy integration allows users to configure a data preparation workflow including augmenting the dataset with either other curated collections or one of the carefully selected public datasets, removing any sensitive or toxic content that may have been present in this documentation, filtering out any rows marked as irrelevant and many other workflows demonstrated in Part One of LLM Data Studio Blog Series.
5. Use the new structured dataset to finetune LLM in H2O LLM Studio.
- Output your dataset as csv for easy import into LLM Studio to finetune. Take a look at the previous blog post on LLM Studio here.
LLM DataStudio Demo
See this flow in action in the following video demonstrating an end-to-end workflow utilizing all components of LLM DataStudio and LLM Studio.
What’s Next?
To wrap up, H2O LLM Data Studio is an essential tool that provides a consolidated solution for preparing data for Large Language Models. Being able to curate datasets from unstructured data and also continue the dataset creation with no-code preparation pipelines, data preparation for LLMs becomes a smooth task.
In a world where data powers everything, LLM DataStudio is an easy-to-use solution that takes the headache out of curating and preparing data. Stay tuned as we continue to democratize LLM data preparation for all organizations. For more information, please contact sales@h2o.ai









