

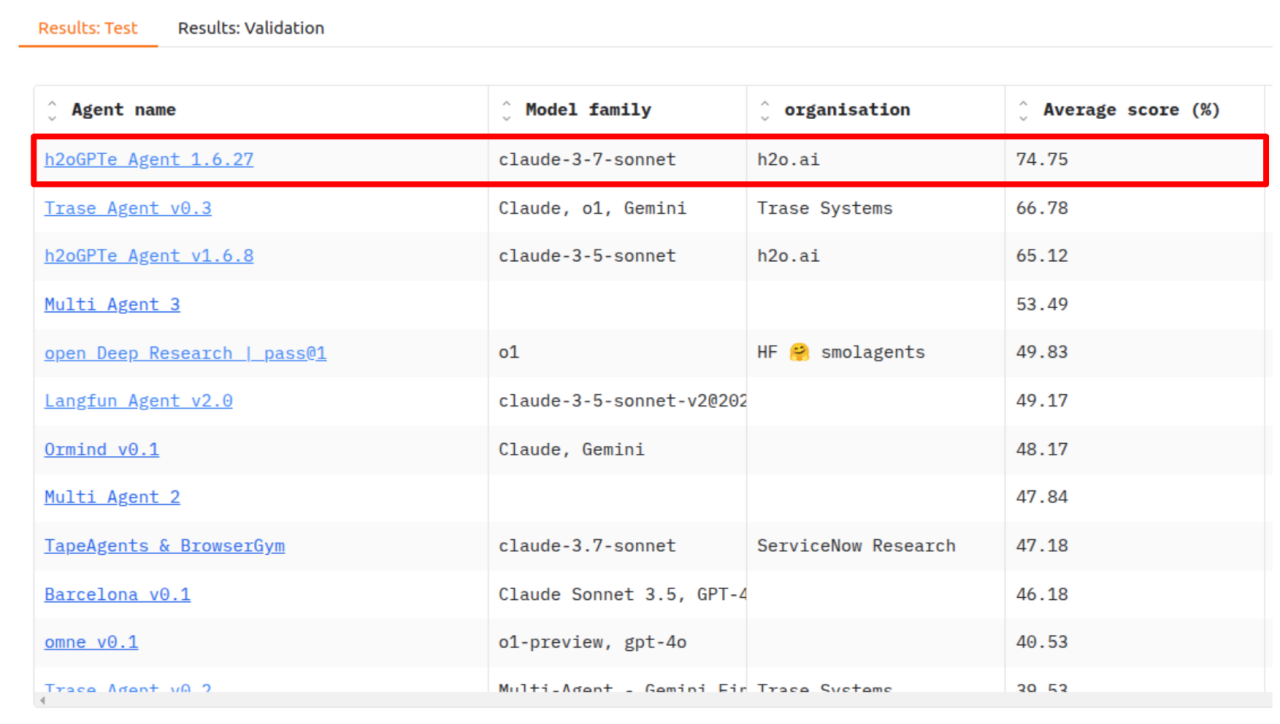
H2O.ai Lidera o benchmark "General AI Assistants” (GAIA)


Temos o orgulho de anunciar que nosso Agente h2oGPTe conquistou novamente o 1º lugar no prestigiado benchmark GAIA (Assistentes de IA Geral) com uma impressionante taxa de precisão de 75% – a primeira vez que uma nota C foi alcançada no conjunto de testes GAIA. Anteriormente, a H2O.ai foi a primeira a obter uma nota de aprovação no teste GAIA. Esta conquista nos coloca à frente da Deep Research da OpenAI, enquanto igualamos o desempenho da novata Manus. Este marco valida nossa visão e abordagem na criação de assistentes de IA que oferecem tanto capacidade excepcional quanto valor prático em aplicações do mundo real.
Novas Capacidades do Agente
Desde nosso anúncio anterior sobre os resultados do benchmark GAIA, aprimoramos significativamente nossa tecnologia de agente com vários recursos-chave que contribuíram para nosso desempenho aprimorado:
- Navegação Aprimorada no Navegador
Nosso agente agora apresenta capacidades sofisticadas de navegação na web que permitem explorar sites complexos, seguir links de forma inteligente e extrair informações relevantes com maior precisão. Ele pode preencher formulários, extrair tabelas HTML e do Google Sheets, capturar telas ou responder perguntas sobre elementos específicos da página, pesquisar dentro de uma página, preencher todos os campos de formulário de uma vez, salvar páginas como PDF e muito mais. Essas capacidades aprimoram significativamente o pacote de uso de navegador de código aberto e permitem que o agente lide com tarefas de pesquisa de múltiplas etapas que exigem exploração profunda de recursos online.
- Busca Unificada em Múltiplos Mecanismos
Nosso agente agora emprega uma ferramenta avançada de busca unificada que usa compreensão de consultas para decidir quais mecanismos de busca utilizar para cada tarefa específica. Ele coordena de forma inteligente buscas no Google (com várias versões da consulta derivadas da compreensão da pergunta), Bing, API de Notícias, Wikipedia, Wolfram Alpha, Semantic Scholar, ArXiv, agente de navegador e Wayback Machine. O sistema agrega e reclassifica resultados usando um LLM ou responde diretamente às perguntas raciocinando sobre esses resultados consolidados, fornecendo informações mais abrangentes e precisas.
- Raciocínio Avançado com Claude 3.7 Sonnet
Nossa arquitetura de agente agora incorpora o Claude 3.7 Sonnet da Anthropic como nosso modelo principal de agente, com seu modo de raciocínio especializado alimentando nosso agente de raciocínio avançado. Esta abordagem de modelo duplo permite que nosso agente principal delegue estrategicamente tarefas analíticas complexas para a versão otimizada para raciocínio, aprimorando significativamente nossas capacidades de resolução de problemas enquanto mantém a eficiência operacional.
- Integração com GitHub para Engenharia de Software
Integramos ferramentas dedicadas do GitHub que capacitam nosso agente a navegar por repositórios, entender bases de código e auxiliar em tarefas de engenharia de software. Esta capacidade tem mostrado resultados promissores no SWE-bench e benchmarks similares, fornecendo aos desenvolvedores assistência mais contextual.
- Atribuição de Fontes em Tempo Real e Citações Inline nas Respostas
Nosso agente foi aprimorado com novas capacidades de atribuição de fontes, agora exibindo links de fontes em tempo real à medida que os descobre e utiliza durante seu processo de pesquisa. Além disso, as respostas finais incluem citações inline que referenciam fontes específicas, criando uma estrutura rigorosa de citação que aumenta a transparência e permite que os usuários verifiquem as informações de forma independente.
Entendendo Nossos Resultados no Benchmark GAIA
O GAIA foi criado pelas equipes Meta-FAIR, Meta-GenAI, HuggingFace e AutoGPT para testar os limites dos LLMs. O benchmark GAIA se destaca de outros benchmarks de IA por focar em tarefas do mundo real que exigem uma combinação de raciocínio, manipulação multimodal e proficiência no uso de ferramentas. O GAIA avalia quão bem os sistemas de IA ajudam os usuários a realizar tarefas reais - desde análise de dados até processamento de documentos e questões complexas de pesquisa.
O benchmark inclui 466 perguntas cuidadosamente elaboradas em três níveis de dificuldade, de fácil (nível 1) a moderadamente desafiador (nível 2) até desafiador (nível 3), testando:
- Navegação na web e síntese de informações
- Compreensão multimodal (texto, imagens, áudio)
- Execução de código e análise de dados
- Manipulação de arquivos em vários formatos
- Raciocínio complexo e planejamento
Exemplos de perguntas:
- Nível 1: Qual foi o número real de inscrições no ensaio clínico sobre H. pylori em pacientes com acne vulgar de janeiro a maio de 2018, conforme listado no site do NIH?
- Nível 2: De acordo com https://www.bls.gov/cps/, qual foi a diferença no desemprego (em %) nos EUA em junho de 2009 entre homens de 20 anos ou mais e mulheres de 20 anos ou mais?
- Nível 3: Nos padrões dos Estados Unidos de 2 de julho de 1959 para graus de frutas processadas, vegetais e certos outros produtos listados como desidratados, considere os itens na 'seção de secos e desidratados' especificamente marcados como desidratados, juntamente com quaisquer itens na seção Congelados/Refrigerados que contenham o nome completo do item, mas não se estiverem marcados como Refrigerados. Em agosto de 2023, qual é a porcentagem (arredondada para o número inteiro mais próximo) desses padrões que foram substituídos por uma nova versão desde a data indicada nos padrões de 1959?
Responder a perguntas de nível 1 requer cerca de 5 etapas para um humano e até 1 ferramenta, mas pode desafiar a acuidade visual da IA. Perguntas de nível 2 requerem 5-10 etapas humanas e quaisquer ferramentas, enquanto perguntas de nível 3 requerem até 50 etapas humanas e qualquer número de ferramentas.
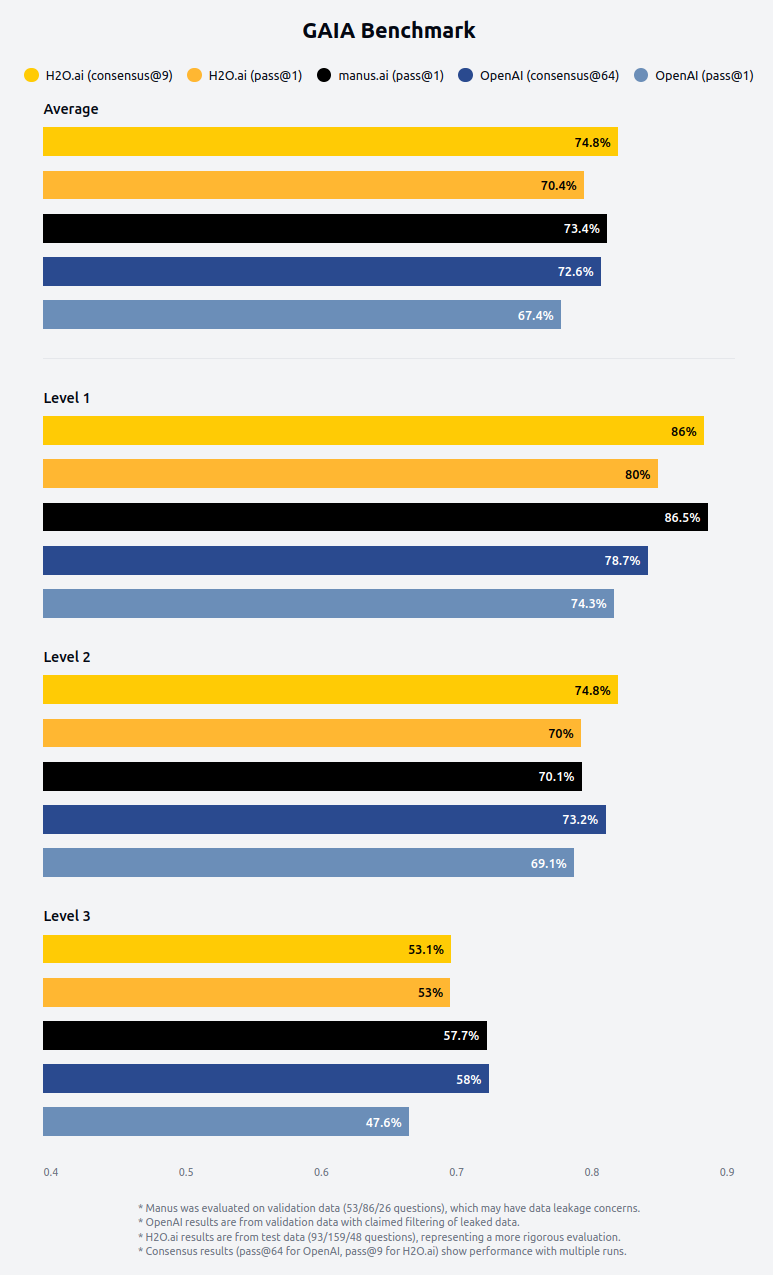
Metodologia de Benchmark e Desafios de Contaminação de Dados
Embora benchmarks como o GAIA forneçam insights valiosos sobre as capacidades dos agentes, devemos reconhecer considerações metodológicas importantes que afetam a interpretação:
- Todas as perguntas e respostas do conjunto de validação GAIA estão amplamente disponíveis online e foram incorporadas em conjuntos de dados de treinamento de LLM, criando potencial contaminação de dados.
- Durante nossas execuções do GAIA, descontaminamos nosso agente bloqueando explicitamente certos sites conhecidos por conter respostas do benchmark, mas observamos que os LLMs subjacentes memorizaram partes dos dados de validação.
- Mesmo ao bloquear fontes diretas com dados de validação, descobrimos que os modelos podem exibir "palpites" suspeitosamente precisos sobre estratégias de busca ou etapas intermediárias — uma forma mais sutil de contaminação.
- Esse vazamento de dados torna o conjunto de validação menos confiável para fins de benchmarking verdadeiros em comparação com o conjunto de testes, que fornece um ambiente de avaliação mais rigoroso.
- O conjunto de dados de validação é mais como fazer lição de casa com soluções no livro ou um exame de livro aberto, enquanto o conjunto de dados de teste é como um exame real sem respostas publicadas.
Por essas razões, enquanto a Deep Research da OpenAI e a Manus foram avaliadas em dados de validação, nossos resultados são avaliados no conjunto de dados de teste, uma avaliação mais rigorosa e extensa envolvendo quase o dobro do número de perguntas sem vazamentos de dados conhecidos.
Além disso, identificamos que aproximadamente 5% dos dados de validação e teste do GAIA contêm erros ou ambiguidades nas respostas de referência. Alguns são simples erros de digitação, enquanto outros são discrepâncias mais substanciais. Essas inconsistências criam uma oportunidade metodológica interessante: ao examinar como diferentes agentes respondem a perguntas com verdades fundamentais problemáticas, os pesquisadores podem entender melhor se as soluções estão sendo derivadas por meio de raciocínio ou potencialmente influenciadas por exposição prévia a dados de benchmark. Essa abordagem ajuda a avançar nossa compreensão coletiva da confiabilidade do benchmark e das metodologias de avaliação de agentes.
Em Breve
Estamos entusiasmados com várias capacidades futuras que vão aprimorar ainda mais o desempenho do nosso agente:
- Renderização de documentos em streaming no painel lateral
- Interação humana via pausas e chat durante o streaming
- Gerenciamento avançado de tarefas e subtarefas
- Agente especializado em formatação de respostas
- Implantação autônoma de sites, ferramentas e agentes
- Integração de conectores de dados como Teradata, Snowflake
Enterprise h2oGPTe
O Enterprise h2oGPTe é uma plataforma para resposta a perguntas sobre documentos via RAG, avaliação de modelos, IA de documentos e agentes. Nossa plataforma suporta implantações em nuvem, on-premise e air-gapped, incluindo o uso de modelos como DeepSeek R1 ou LLaMa 3.3 70B, onde o DeepSeek R1 alcança cerca de 45% no teste GAIA.
Análise Preditiva encontra IA Generativa
O agente Enterprise h2oGPTe executa o DriverlessAI ou outras plataformas de aprendizado de máquina a partir de um simples comando do usuário. O DAI faz previsão de séries temporais, modelagem de prevenção de fraudes, etc., e nosso agente fornece gráficos detalhados, resultados, insights de ciência de dados e recomendações de negócios.
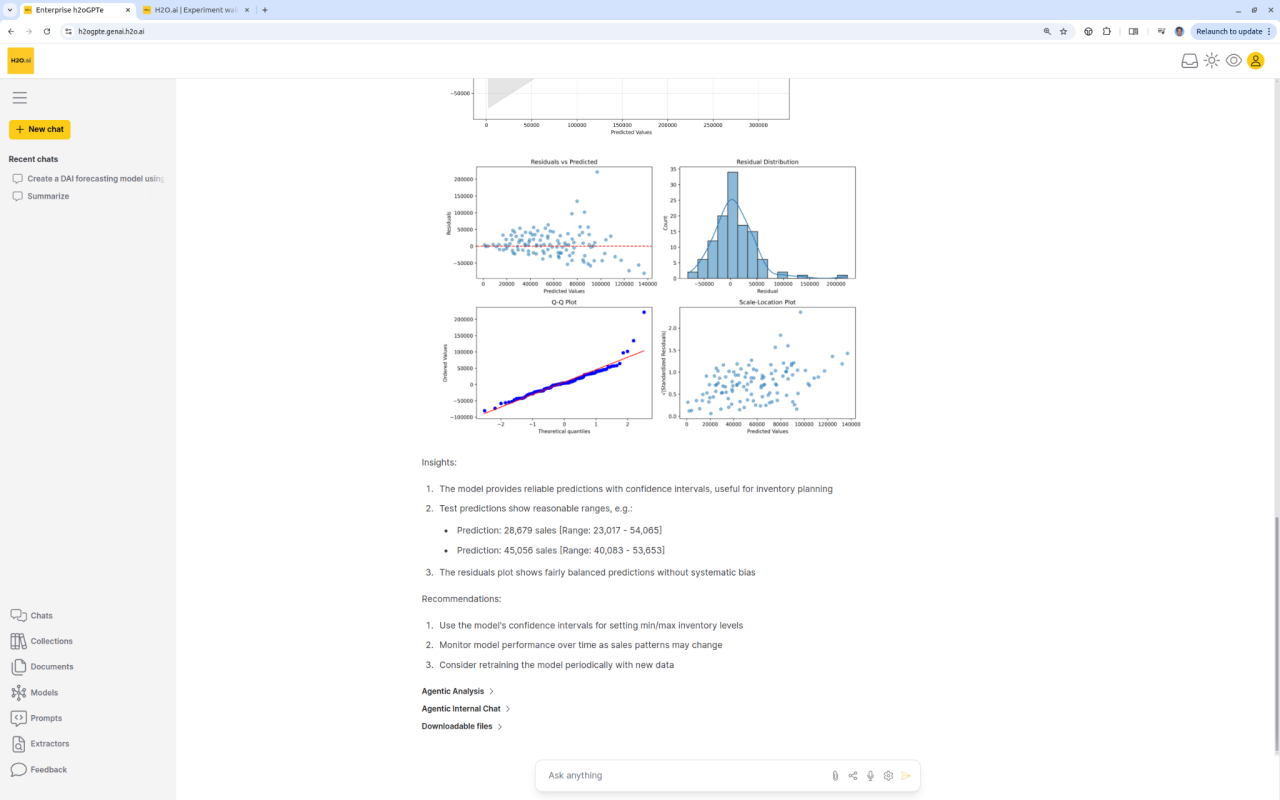
O Futuro dos Agentes
Nosso desempenho superior no GAIA representa mais do que apenas uma conquista técnica — valida nossa abordagem de construir sistemas de IA práticos e adaptáveis que podem realmente auxiliar em tarefas do mundo real.
O futuro do software empresarial não está em aplicações isoladas, mas em agentes inteligentes que podem coordenar perfeitamente entre ferramentas e fontes de dados. Nosso sucesso com o GAIA demonstra que estamos liderando o caminho para tornar esse futuro uma realidade.
Saiba mais sobre nós em h2o.ai.
Experimente nossa oferta freemium que inclui agentes em https://h2ogpte.genai.h2o.ai/.
h2oGPTe Agents Team: Jon McKinney, Fatih Ozturk, Laura Fink, Mathias Müller, Ryan Chesler, Arno Candel, Kim Montgomery, Luxshan Thavarasa, Prathushan Inparaj, Ruben Alvarez, and many others.