
H2O.ai Blog
Filter By:
5 results Category: Year:
Using Python's datatable library seamlessly on Kaggle
Managing large datasets on Kaggle without fearing about the out of memory error Datatable is a Python package for manipulating large dataframes. It has been created to provide big data support and enable high performance. This toolkit resembles pandas very closely but is more focused on speed.It supports out-of-memoy datasets, multi-thr...
Read more
Speed up your Data Analysis with Python’s Datatable package
A while ago, I did a write up on Python’s Datatable library . The article was an overview of the datatable package whose focus is on big data support and high performance. The article also compared datatable’s performance with the pandas’ library on certain parameters. This is the second article in the series with a two-fold objective: ...
Read more
Stacked Ensembles and Word2Vec now available in H2O!
Prepared by: Erin LeDell and Navdeep Gill MathJax.Hub.Config({ tex2jax: {inlineMath: [['$','$'], ['\\(','\\)']]} }); Stacked Ensembles ensemble <- h2o.stackedEnsemble(x = x, y = y, training_frame = train, base_models = my_models) Python:ensemble = H2OStackedEnsembleEstimator(base_models=my_models) ensemble.train(x=x, y=y, training...
Read more
Red herring bites
At the Bay Area R User Group in February I presented progress in big-join in H2O which is based on the algorithm in R’s data.table package. The presentation had two goals: i) describe one test in great detail so everyone understands what is being tested so they can judge if it is relevant to them or not; and ii) show how it scales with...
Read more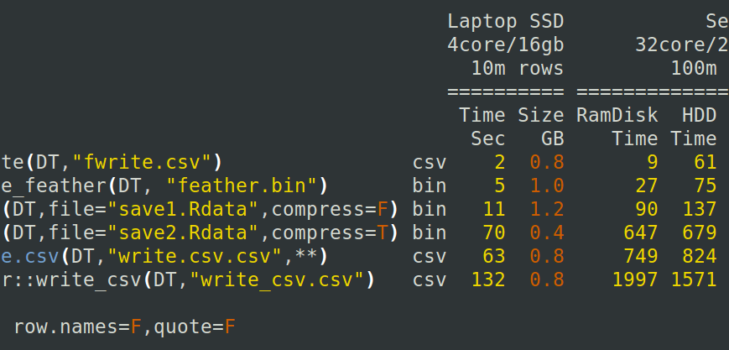
Fast csv writing for R
R has traditionally been very slow at reading and writing csv files of, say, 1 million rows or more. Getting data into R is often the first task a user needs to do and if they have a poor experience (either hard to use, or very slow) they are less likely to progress. The data.table package in R solved csv import convenience and speed in 2...
Read more