




H2O.ai Blog
Filter By:
5 results Category: Year:
Parallel Grid Search in H2O
H2O-3 is, at its core, a platform for distributed, in-memory computing. On top of the distributed computation platform, the machine learning algorithms are implemented. At H2O.ai, we design every operation, be it data transformation, training of machine learning models or even parsing to utilize the distributed computation model. In ord...
Read more
Behind the scenes of CRAN
(Just from my point of view as a package maintainer.) New users of R might not appreciate the full benefit of CRAN and new package maintainers may not appreciate the importance of keeping their packages updated and free of warnings and errors. This is something I only came to realize myself in the last few years so I thought I would write...
Read more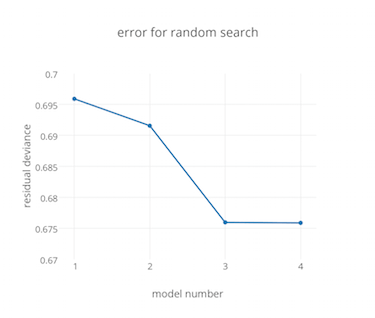
Hyperparameter Optimization in H2O: Grid Search, Random Search and the Future
“Good, better, best. Never let it rest. ‘Til your good is better and your better is best.” – St. Jerome tl;drH2O now has random hyperparameter search with time- and metric-based early stopping. Bergstra and Bengio[1] write on p. 281: Compared with neural networks configured by a pure grid search, we find that random search over the s...
Read more
Red herring bites
At the Bay Area R User Group in February I presented progress in big-join in H2O which is based on the algorithm in R’s data.table package. The presentation had two goals: i) describe one test in great detail so everyone understands what is being tested so they can judge if it is relevant to them or not; and ii) show how it scales with...
Read more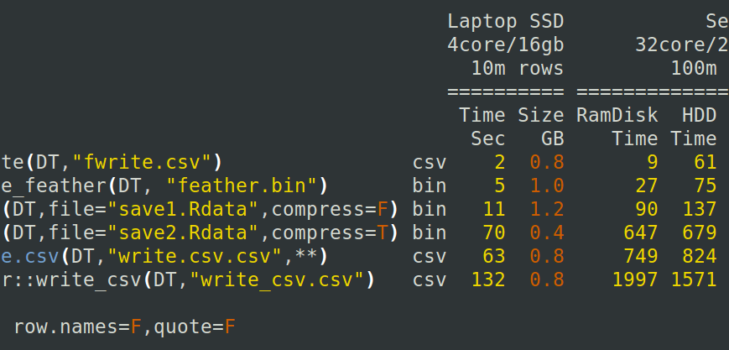
Fast csv writing for R
R has traditionally been very slow at reading and writing csv files of, say, 1 million rows or more. Getting data into R is often the first task a user needs to do and if they have a poor experience (either hard to use, or very slow) they are less likely to progress. The data.table package in R solved csv import convenience and speed in 2...
Read more