







Mission Impossible: Improving Patient Care Through Automated Document Processing
Don’t tell Bob Rogers’ team something can’t be done.
When Rogers embarked on an ambitious project to automate the processing of the more than 1.4 million electronically faxed documents received annually by the Center for Digital Health Innovation at the University of California, San Francisco (UCSF CDHI), advisors and vendors initially told him the project was “impossible.” “We had a panel of experts come to us as part of our due diligence who said ‘what you’re trying to do is impossible’,” Rogers, who serves as the center’s expert in residence for artificial intelligence, said during a recent H2O.ai webinar . “We were hopeful that information extraction from structured documents was possible, but we weren’t sure.”
The Center for Digital Health Innovation, which provides the renowned UCSF health system the latest advanced technologies to support the center’s innovative patient care, was challenged in efficiently and accurately handling this wide array of patient records including referrals, prescription requests, requisitions for medical equipment, lab results and other forms. Rogers’ team had a vision for not only easing the administrative burden on the center’s staff but ultimately improving patient care and outcomes.
A complex, moving target
Medical records are among the most complex documents to process. Each medical facility, care provider and insurer has unique forms that don’t necessarily follow a standard pattern. While these semi-structured documents include similar information, they do so in different formats and inconsistently labeled fields. “These are not simple forms or forms that repeat,” Rogers said. “There is nuance in primary care, current provider, referrals and current history that can be up to 100 pages. Figuring out who is who and what the intent is is a complex undertaking,” he added.
The center had experimented with optical character recognition (OCR) and robotic process automation (RPA) to extract information to limited success. According to Lu Chen, lead data scientist at UCSF CDHI who led what came to be known as the Intake Automation project: “We tried to solve the problem with a template-based fax process, with predefined areas where OCR could look and extract information. (However), templates changed over time and the success rate dropped year over year.”
UCSF CDHI turned to the team at H2O.ai to explore how H2O Document AI could overcome the initial limitations of Intake Automation. “UCSF came in with the RPA efforts they had tried, and they were data-rich when they came to us,” said Mark Landry, one of H2O.ai’s lead data scientists and a Kaggle Grandmaster who consulted on the project. They “were already able to get more accurate characters from the screen and could deploy a more complex learning algorithm” that could recognize, for example, what a patient name looks like regardless of the format or who sent the form.
How it works
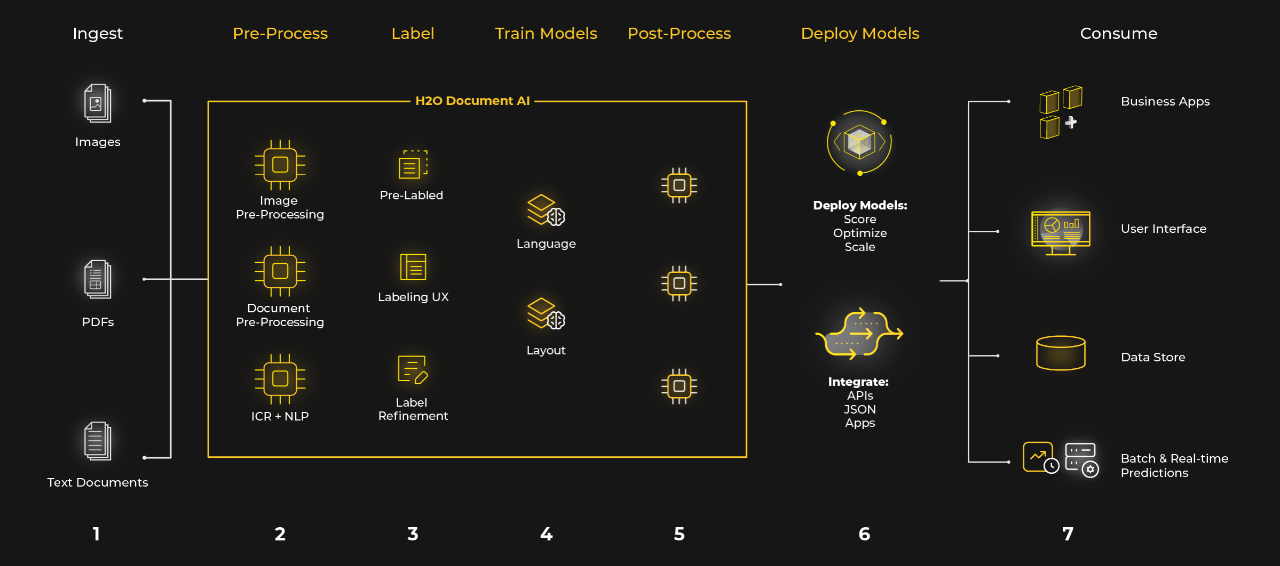
H2O Document AI augmented the Intake Automation solution with the addition of intelligent character recognition (ICR) that utilizes dynamically learning algorithms for general character and word recognition, understanding of the document’s layout and natural language processing (NLP) to make document management easier. H2O Document AI comprises six logical processes:
- Ingest – documents are uploaded to H2O Document AI using a web interface or API. H2O Document AI accommodates a wide variety of formats including images, scans such as PDF, embedded text documents with layout metadata such as Word documents or HTML pages, and regular text “left-to-right/top-to-bottom” documents such as email or editable forms.
- Pre-Process – computer vision and NLP features support the recognition and handling of embedded text, logos and other images, page orientation, deskewing, optimizing text formatting, eliminating background “noise” and rectifying document quality challenges.
- Label – the addition, improvement and validation of document labels, including the creation of labels for unlabeled documents, fixing data label errors in training data, provisioning label interfaces for data scientists and third-party human labelers, integration with common label formats and other advanced options for label validation.
- Train Models – selection of the training data set from H2O Document AI, which automatically learns the document and creates models. This includes language understanding and layout recognition and an AI/ML engine that deploys multiple computer vision and NLP algorithms for a wide array of AI tasks including entity recognition, document and page classification, form understanding, and grouping and set identification.
- Post-Process – ensures consistency, accuracy and organization of scored documents. Post-process enables customers to undertake customized jobs that use AI algorithms (vs. rules) to ensure quality predictions and insights.
- Deploy Models – models are published to H2O MLOPS, part of the H2O AI Hybrid Cloud, or into a cloud on on-premise environment.
Top technology, tight collaboration
Rogers and Chen credit the tight cooperation between UCSF CDHI and the H2O.ai team for the success of Intake Automation. “The collaboration process with H2O.ai was key in how we were able to succeed,” Rogers said. “UCSF and H2O were aligned in the mission, which makes for a fantastic partnership. (We) were able to come together with the right data and right conception of the problem and how it fits within our applications, and, frankly, I don’t think I’m overstepping to say that Lu and I were a bit starstruck working with Mark and some of the other Kaggle Grandmasters together on this project.”
Sri Ambati, CEO and co-founder of H2O.ai, said: “The best innovation in AI is no longer at the level of the algorithm, but is actually at the co-creation of data scientists and domain experts. If you can make that (collaboration) happen easily and take the best of the context-setting and the best of the algorithms, and automate that to fine-tune and search, you have a very compelling outcome.”
To learn more about H2O Document AI and how it can address your document automation challenges, please visit our website .
Additional Resources
- UCSF CHI / H2O Document AI case study
- H2O.ai Community
- H2O.ai on GitHub
- H2O.ai on YouTube







