




Using Python's datatable library seamlessly on Kaggle

Managing large datasets on Kaggle without fearing about the out of memory error
Datatable is a Python package for manipulating large dataframes. It has been created to provide big data support and enable high performance. This toolkit resembles pandas very closely but is more focused on speed.It supports out-of-memoy datasets, multi-threaded data processing, and has a flexible API. In the past, we have written a couple of articles that explain in detail how to use datatable for reading, processing, and writing tabular datasets at incredible speed:
- An Overview of Python’s Datatable package
- Speed up your Data Analysis with Python’s Datatable package
These two articles compare datatable’s performance with the pandas’ library on certain parameters. Additionally, they also explain how to use datatable for data wrangling and munging and how their performance compares to other libraries in the same space.
However, this article is mainly focused on people who are interested in using datatable on the Kaggle platform. Of late, many competitions on Kaggle are coming with datasets that are just impossible to read in with pandas alone. We shall see how we can use datatable to read those large datasets efficiently and then convert them into other formats seamlessly.
Currently datatable is in the Beta stage and undergoing active development.
Installation
Kaggle Notebooks are a cloud computational environment that enables reproducible and collaborative analysis. The datatable package is part of Kaggle’s docker image. This means no additional effort is required to install the library on Kaggle. All you have to do is import the library and use it.
importas0.11.1
However, if you would want to download a specific version of the library(or maybe the latest version when available), you can do so by pip installing the library. Make sure the internet setting is set to ON in the notebooks.
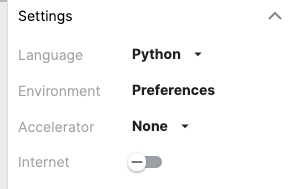 !pip install datatable==0.11.0
!pip install datatable==0.11.0If you want to install datatable locally on your system, follow the instructions given in the official documentation .
Usage
Let’s now see an example where the benefit of using datatable is clearly visible. The dataset that we’ll use for the demo is being taken from a recent Kaggle competition titled Riiid Answer Correctness Prediction competition . The challenge was to create algorithms for “Knowledge Tracing” by modeling the student knowledge over time. In other words, the aim was to accurately predict how students will perform in future interactions.

The train.csv file consists of around a hundred Million rows . The data size is ideal for demonstrating the capabilities of the datatable library.
Pandas, unfortunately, throws an out of memory error and is unable to handle datasets of this magnitude. Let’s try Datatable instead and also record the time taken to read the dataset and its subsequent conversion into pandas dataframe
1. Reading data in CSV format
The fundamental unit of analysis in datatable is a Frame. It is the same notion as a pandas DataFrame or SQL table, i.e., data arranged in a two-dimensional array with rows and columns.

The fread() function above is both powerful and extremely fast. It can automatically detect and parse parameters for most text files, load data from .zip archives or URLs, read Excel files, and much more. Let’s check out the first five rows of the dataset.

Datatable takes less than a minute to read the full dataset and convert it to pandas.
2. Reading data in jay format
The dataset can also be first saved in binary format (.jay) then read in using the datatable. The .jay file format is designed explicitly for datatable’s use, but it is open to be adopted by some other libraries or programs.
# saving the dataset in .jay (binary format)Let’s now look at the time taken to read in the jay format file.
# reading the dataset from .jay format
It takes less than a second to read the entire dataset in the .jay format. Let’s now convert it into pandas, which is reasonably fast too.

Let’s quickly glance over the first few rows of the frame:
Here we have a pandas dataframe that can be used for further data analysis. Again the time taken for the conversion was mere 27s.
Conclusion
In this article, we saw how the datatable package shines when working with big data. With its emphasis on big data support , datatable offers many benefits and can improve the time taken to perform wrangling tasks on a dataset. Datatable is an open-source project , and hence it is open to contributions and collaborations to improve it and make it even better. We’ll love to have you try it out and use it in your projects. If you have questions about using datatable, post them on Stack Overflow using the [py-datatable] tag.
